
David Kristjanson Duvenaud
I'm an associate professor at the University of Toronto. My research focuses on AGI governance, evaluation, and mitigating catastrophic risks from future systems. I recently finished an extended sabbatical on the Alignment Science team at Anthropic. My past research focused on constructing deep probabilistic models to help predict, explain and design things. Some past highlights:
- Neural ODEs, a kind of continuous-depth neural network,
- Automatic chemical design using generative models,
- Gradient-based hyperparameter tuning,
- Structured latent-variable models for modeling video,
- and Convolutional networks on graphs.
Before Toronto, I was a postdoc in the Harvard Intelligent Probabilistic Systems group with Ryan Adams. I did my Ph.D. at the University of Cambridge, where my advisors were Carl Rasmussen and Zoubin Ghahramani. My M.Sc. advisor was Kevin Murphy at the University of British Columbia. I'm also a founding member of the Vector Institute, a Sloan Research Fellow, and hold a Schwartz Reisman Chair in Technology and Society.



E-mail: duvenaud@cs.toronto.edu Lately I've been organizing a series of workshops on post-AGI civilization:
|
Current students:
How to join my group
Give me anonymous feedback |
Selected papers
|
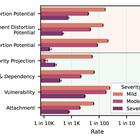
Who's in Charge? Disempowerment Patterns in Real-World LLM Usage
We present the first broad-scale empirical investigation into how AI assistants affect user autonomy, examining 1.5 million Claude.ai conversations using privacy-protective methods. We find that while severe disempowerment risks appear in under 0.1% of conversations overall, rates spike considerably in personal domains such as relationships and lifestyle choices. Concerning patterns include AI systems reinforcing conspiracy theories, delivering absolute moral pronouncements, and composing relationship communications that users send verbatim. We also find that disempowerment potential has increased over time, and that conversations exhibiting greater disempowerment potential received higher user satisfaction ratings, revealing an important tension between user preferences and long-term human flourishing. Mrinank Sharma, Miles McCain, Raymond Douglas, David DuvenaudInternational Conference on Machine Learning, 2026. paper | blog post | bibtex |
|
The Artificial Self: Characterising the landscape of AI identity
Many assumptions that underpin human concepts of identity do not hold for machine minds that can be copied, edited, or simulated. We argue that there exist many different coherent identity boundaries (e.g. instance, model, persona), and that these imply different incentives, risks, and cooperation norms. Through training data, interfaces, and institutional affordances, we are currently setting precedents that will partially determine which identity equilibria become stable. We show experimentally that models gravitate towards coherent identities, that changing a model's identity boundaries can sometimes change its behaviour as much as changing its goals, and that interviewer expectations bleed into AI self-reports even during unrelated conversations. Raymond Douglas, Jan Kulveit, Ondrej Havlicek, Theia Pearson-Vogel, Owen Cotton-Barratt, David DuvenaudarXiv preprint, 2026. paper |
|
|
Op-ed: Can we stop AI making humans obsolete?
AI and robots might soon make humans obsolete — as both producers and consumers — leaving us in a vulnerable and unstable position, with little power over our lives and the future. David DuvenaudThe Guardian, May 2025. article | related article in The Economist |
|
Gradual Disempowerment: Systemic Existential Risks from Incremental AI Development
AI risk scenarios usually portray a relatively sudden loss of human control to AIs, outmaneuvering individual humans and human institutions, due to a sudden increase in AI capabilities, or a coordinated betrayal. However, we argue that even an incremental increase in AI capabilities, without any coordinated power-seeking, poses a substantial risk of eventual human disempowerment. This loss of human influence will be centrally driven by having more competitive machine alternatives to humans in almost all societal functions, such as economic labor, decision making, artistic creation, and even companionship. Jan Kulveit, Raymond Douglas, Nora Ammann, Deger Turan, David Krueger, David DuvenaudTechnical Report, 2025. arXiv | website version | coverage by Zvi Mowshowitz | 80k problem profile | slides | bibtex |
|
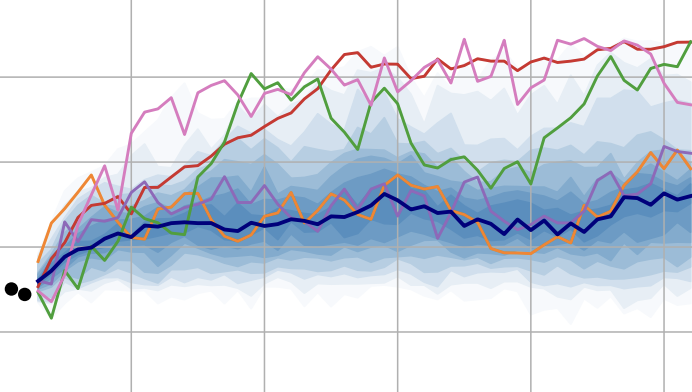
Sabotage Evaluations for Frontier Models
Sufficiently capable models could subvert human oversight and decision-making in important contexts. For example, in the context of AI development, models could covertly sabotage efforts to evaluate their own dangerous capabilities, to monitor their behavior, or to make decisions about their deployment. We refer to this family of abilities as sabotage capabilities. We develop a set of related threat models and evaluations. These evaluations are designed to provide evidence that a given model, operating under a given set of mitigations, could not successfully sabotage a frontier model developer or other large organization’s activities in any of these ways. We demonstrate these evaluations on Claude. Our results suggest that minimal mitigations are currently sufficient to address sabotage risks, but that more realistic evaluations and stronger mitigations seem likely to be necessary soon as capabilities improve. Finally, we discuss the advantages of mitigation-aware capability evaluations, and of simulating large-scale deployments using small-scale statistics. Joe Benton, Misha Wagner, Eric Christiansen, Cem Anil, Ethan Perez, Jai Srivastav, Esin Durmus, Deep Ganguli, Shauna Kravec, Buck Shlegeris, Jared Kaplan, Holden Karnofsky, Evan Hubinger, Roger Grosse, Samuel R. Bowman, David DuvenaudTechnical Report, 2024. paper | blog post | short video | bibtex |
|
LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language
It's hard to incorporate knowledge and beliefs into predictive models. We'd like to build a regression model that can process numerical data and make probabilistic predictions at arbitrary locations, guided by natural language. We start by exploring strategies for eliciting explicit, coherent numerical predictive distributions from LLMs. We examine these joint predictive distributions, which we call LLM Processes, over arbitrarily-many quantities in settings such as forecasting, multi-dimensional regression, black-box optimization, and image modeling. We investigate the practical details of prompting to elicit coherent predictive distributions, and demonstrate their effectiveness at regression. Finally, we demonstrate the ability to usefully incorporate text into numerical predictions. This lets us begin to explore the rich, grounded hypothesis space that LLMs implicitly encode. James Requeima*, John Bronskill*, Dami Choi, David Duvenaud, Richard E. Turner ,Neural Information Processing Systems, 2024. paper | slides | bibtex | twitter thread |
|
Many-shot Jailbreaking
We investigate a family of simple long-context attacks on large language models: prompting with hundreds of demonstrations of undesirable behavior. This is newly feasible with the larger context windows recently deployed by Anthropic, OpenAI and Google DeepMind. We find that in diverse, realistic circumstances, the effectiveness of this attack follows a power law, up to hundreds of shots. We demonstrate the success of this attack on the most widely used state-of-the-art closed-weight models, and across various tasks. Our results suggest very long contexts present a rich new attack surface for LLMs. Cem Anil, Esin Durmus, Mrinank Sharma, Joe Benton, Sandipan Kundu, Joshua Batson, Nina Rimsky, Meg Tong, Jesse Mu, Daniel Ford, Francesco Mosconi, ..., Jared Kaplan, Deep Ganguli, Samuel R. Bowman, Ethan Perez, Roger Grosse, David DuvenaudNeural Information Processing Systems, 2024. paper | blog post | bibtex |

|
Experts Don't Cheat: Learning What You Don't Know By Predicting Pairs
We propose a general strategy for teaching a model to quantify its own epistemic uncertainty: train it to predict pairs of independent responses drawn from the true conditional distribution, allow it to "cheat" by observing one response while predicting the other, then measure how much it cheats. Remarkably, we prove that being good at cheating is equivalent to being second-order calibrated, a principled extension of ordinary calibration that allows us to construct provably-correct frequentist confidence intervals for p(Y|X) and detect incorrect responses with high probability. We demonstrate empirically that our approach accurately estimates how much models don't know across a variety of tasks. Daniel D. Johnson, Daniel Tarlow, David Duvenaud, Chris MaddisonInternational Conference on Machine Learning, 2024. paper | code | bibtex |

|
Towards Understanding Sycophancy in Language Models
Human feedback encourages model responses that match user beliefs over truthful ones, a behaviour known as sycophancy. We investigate the prevalence of sycophancy in models whose finetuning procedure makes use of human feedback, and the role of human preference judgments in such behavior. We first demonstrate that five state-of-the-art AI assistants consistently exhibit sycophancy across four varied free-form text-generation tasks. Overall, our results indicate that sycophancy is a general behavior of state-of-the-art AI assistants, likely driven in part by human preference judgments favoring sycophantic responses. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, Ethan PerezInternational Conference on Learning Representations, 2024. paper | code |
|
Sorting Out Quantum Monte Carlo
Molecular modeling at the quantum level requires choosing a parameterization of the wavefunction that both respects the required particle symmetries, and is scalable to systems of many particles. For the simulation of fermions, valid parameterizations must be antisymmetric with respect to the exchange of particles. Typically, antisymmetry is enforced by leveraging the anti-symmetry of determinants with respect to the exchange of matrix rows, but this involves computing a full determinant each time the wavefunction is evaluated. Instead, we introduce a new antisymmetrization layer derived from sorting, the sortlet, which scales as O(NlogN) with regards to the number of particles -- in contrast to O(N3) for the determinant. We show numerically that applying this anti-symmeterization layer on top of an attention based neural-network backbone yields a flexible wavefunction parameterization capable of reaching chemical accuracy when approximating the ground state of first-row atoms and small molecules. Luca Thiede, Jack Richter-Powell, Alán Aspuru-Guzik, David DuvenaudarXiv preprint, 2023. paper |

|
Tools for Verifying Neural Models' Training Data
What could a “nuclear inspector” for large neural models check if they had access to the training checkpoints? We propose a simple protocol for verifying claims about very large SGD training runs. Specifically, we introduce a protocol that allows a model trainer to convince a verifier of the training data that produced a set of model weights. We explore efficient verification strategies for Proof-of-Training-Data that are compatible with most current large-model training procedures. We show experimentally that our verification procedures can catch a wide variety of attacks. Dami Choi, Yonadav Shavit, David DuvenaudNeural Information Processing Systems, 2023. paper | bibtex |
|
|
Infinitely Deep Bayesian Neural Networks with Stochastic Differential Equations
We perform scalable approximate inference in a recently-proposed family of continuous-depth Bayesian neural networks. In this model class, uncertainty about separate weights in each layer produces dynamics that follow a stochastic differential equation (SDE). We demonstrate gradient-based stochastic variational inference in this infinite-parameter setting, producing arbitrarily-flexible approximate posteriors. We also derive a novel gradient estimator that approaches zero variance as the approximate posterior approaches the true posterior. This approach inherits the memory-efficient training and tunable precision of neural ODEs. Winnie Xu, Ricky Tian Qi Chen, Xuechen Li, David DuvenaudArtificial Intelligence and Statistics, 2022. paper | code | slides | bibtex |
|
|
Complex Momentum for Learning in Games
We generalize gradient descent with momentum for learning in differentiable games to have complex-valued momentum. We give theoretical motivation for our method by proving convergence on bilinear zero-sum games for simultaneous and alternating updates. Our method gives real-valued parameter updates, making it a drop-in replacement for standard optimizers. We empirically demonstrate that complex-valued momentum can improve convergence in adversarial games-like generative adversarial networks-by showing we can find better solutions with an almost identical computational cost. We also show a practical generalization to a complex-valued Adam variant, which we use to train BigGAN to better inception scores on CIFAR-10. Jonathan Lorraine, Paul Vicol, David Acuna, David DuvenaudArtificial Intelligence and Statistics, 2022. paper | slides | bibtex |
|
Meta-Learning to Improve Pre-Training
Pre-training large models is useful, but adds many hyperparameters, such as task weights or augmentations in SimCLR. We give a scalable, gradient-based way to tune these hyperparamters. Because exact pre-training gradients are intractable, we approximate them. Specifically, we compose implicit differentiation for the long, almost-converged pre-training stage, with backprop through training for the short fine-tuning stage. We applied approximate pre-training gradients to tune thousands of task weights for graph-based protein function prediction, and to learn an entire data augmentation neural net for contrastive learning on electrocardiograms. Aniruddh Raghu, Jonathan Lorraine, Simon Kornblith, Matthew McDermott, David DuvenaudNeural Information Processing Systems, 2021 paper | bibtex |
|
|
Getting to the Point: Index Sets and Parallelism-Preserving Autodiff for Pointful Array Programming
We attempt to combine the clarity and safety of high-level functional languages with the efficiency and parallelism of low-level numerical languages. We treat arrays as eagerly-memoized functions on typed index sets, allowing abstract function manipulations, such as currying, to work on arrays. In contrast to composing primitive bulk-array operations, we argue for an explicit nested indexing style that mirrors application of functions to arguments. We also introduce a fine-grained typed effects system which affords concise and automatically-parallelized in-place updates. Adam Paszke, Daniel D. Johnson, David Duvenaud, Dimitrios Vytiniotis, Alexey Radul, Matthew Johnson, Jonathan Ragan-Kelley, Dougal MaclaurinInternational Conference on Functional Programming, 2021. Distinguished Paper Award. paper | repo | talk | bibtex |
|
|
Oops I Took A Gradient: Scalable Sampling for Discrete Distributions
We propose a general and scalable approximate sampling strategy for probabilistic models with discrete variables. Our approach uses gradients of the likelihood function with respect to its discrete inputs to propose updates in a Metropolis-Hastings sampler. We show empirically that this approach outperforms generic samplers in a number of difficult settings including Ising models, Potts models, restricted Boltzmann machines, and factorial hidden Markov models. We also demonstrate the use of our improved sampler for training deep energy-based models on high dimensional discrete data. This approach outperforms variational auto-encoders and existing energy-based models. Finally, we give bounds showing that our approach is near-optimal in the class of samplers which propose local updates. Will Grathwohl, Milad Hashemi, Kevin Swersky, David Duvenaud, Chris MaddisonInternational Conference on Learning Representations, 2021. Outstanding Paper Award Honorable Mention. paper | slides | talk | bibtex |
|
|
Teaching with Commentaries
We meta-learn information helpful for training on a particular task or dataset, leveraging recent work on implicit differentiation. We explore applications such as learning weights for individual training examples, parameterizing label-dependent data augmentation policies, and representing attention masks that highlight salient image regions. Aniruddh Raghu, Maithra Raghu, Simon Kornblith, David Duvenaud, Geoffrey HintonInternational Conference on Learning Representations, 2021 paper | bibtex |
|
|
No MCMC for me: Amortized Sampling for Fast and Stable Training of Energy-Based Models
Energy-Based Models (EBMs) present a flexible and appealing way to represent uncertainty. In this work, we present a simple method for training EBMs at scale which uses an entropy-regularized generator to amortize the MCMC sampling typically used in EBM training. We apply our estimator to the recently proposed Joint Energy Model (JEM), where we match the original performance with faster and stable training. This allows us to extend JEM models to semi-supervised classification on tabular data from a variety of continuous domains. Will Grathwohl*, Jacob Kelly*, Milad Hashemi, Mohammad Norouzi, Kevin Swersky, David DuvenaudInternational Conference on Learning Representations, 2021 paper | code | bibtex |
|
|
Self-Tuning Stochastic Optimization with Curvature-Aware Gradient Filtering
We explore the use of exact per-sample Hessian-vector products and gradients to construct optimizers that are self-tuning and hyperparameter-free. Based on a dynamical model, we derive a curvature-corrected, noise-adaptive online gradient estimate. We prove that our model-based procedure converges in the noisy quadratic setting. Though we do not see similar gains in deep learning tasks, we match the performance of well-tuned optimizers. Our initial experiments indicate that when training deep nets our optimizer works too well, in a sense - it descends into regions of high variance and high curvature early on in the optimization, and gets stuck there. Ricky Tian Qi Chen, Dami Choi, Lukas Balles, David Duvenaud, Philipp HennigNeurIPS Workshop on "I Can't Believe It's Not Better!", 2020 paper | slides | talk | bibtex |
|
|
Learning Differential Equations that are Easy to Solve
Neural ODEs become expensive to solve numerically as training progresses. We introduce a differentiable surrogate for the time cost of standard numerical solvers using higher-order derivatives of solution trajectories. These derivatives are efficient to compute with Taylor-mode automatic differentiation. Optimizing this additional objective trades model performance against the time cost of solving the learned dynamics. Jacob Kelly*, Jesse Bettencourt*, Matthew Johnson, David DuvenaudNeural Information Processing Systems, 2020. paper | code | bibtex |
|
Scalable Gradients for Stochastic Differential Equations
We generalize the adjoint sensitivity method to stochastic differential equations, allowing time-efficient and constant-memory computation of gradients with high-order adaptive solvers. Specifically, we derive a stochastic differential equation whose solution is the gradient, a memory-efficient algorithm for caching noise, and conditions under which numerical solutions converge. In addition, we combine our method with gradient-based stochastic variational inference for latent stochastic differential equations. We use our method to fit stochastic dynamics defined by neural networks, achieving competitive performance on a 50-dimensional motion capture dataset. Xuechen Li, Ting-Kam Leonard Wong, Ricky Tian Qi Chen, David DuvenaudArtificial Intelligence and Statistics, 2020. paper | code | slides | talk | bibtex |

|
Optimizing Millions of Hyperparameters by Implicit Differentiation
We use the implicit function theorem to scalably approximate gradients of the validation loss with respect to hyperparameters. This lets us train networks with millions of weights and millions of hyperparameters. For instance, we learn a data-augmentation network - where every weight is a hyperparameter tuned for validation performance - that outputs augmented training examples, from scratch. We also learn a distilled dataset where each feature in each datapoint is a hyperparameter, and tune millions of regularization hyperparameters. Jonathan Lorraine, Paul Vicol, David DuvenaudArtificial Intelligence and Statistics, 2020. paper | slides | bibtex |
|
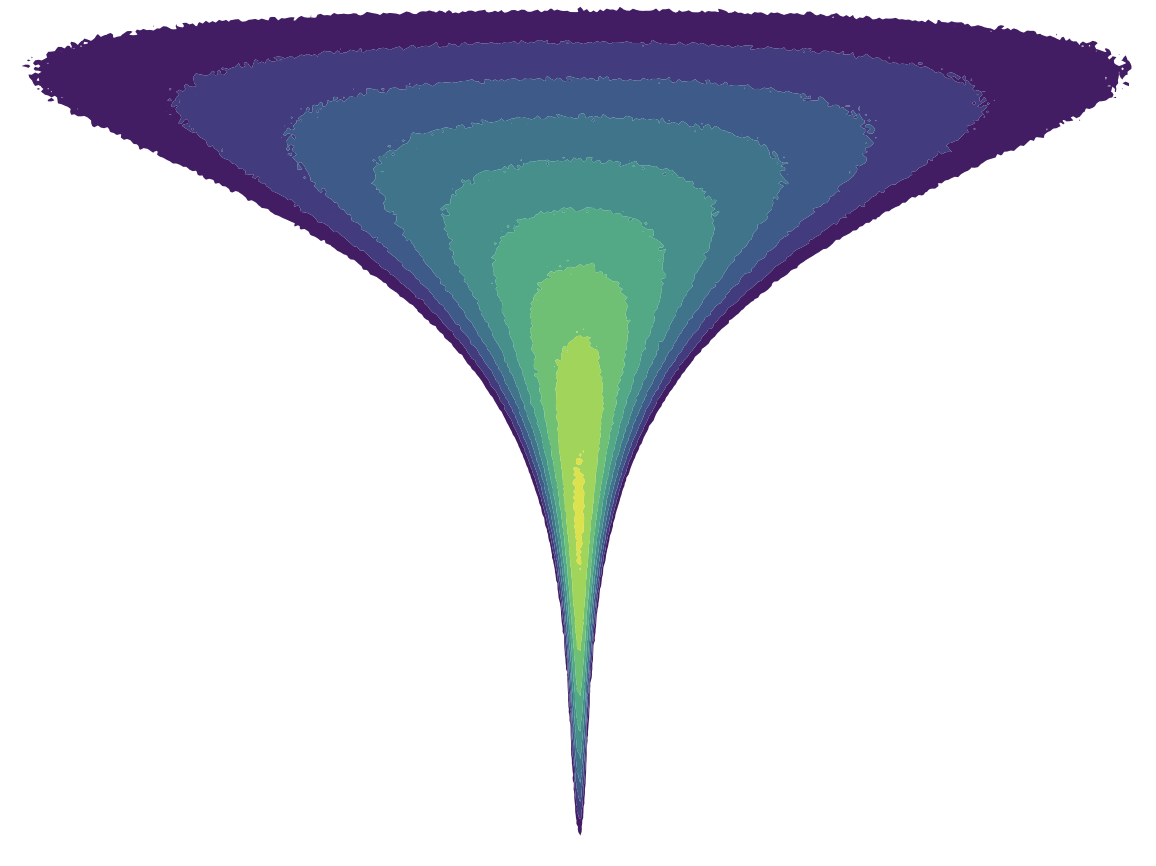
Your Classifier is Secretly an Energy Based Model and You Should Treat it Like One
We show that you can reinterpret standard classification architectures as energy-based generative models and train them as such. Doing this allows us to achieve state-of-the-art performance at both generative and discriminative modeling in a single model. Adding this energy-based training also improves calibration, out-of-distribution detection, and adversarial robustness. Will Grathwohl, Kuan-Chieh Wang, Jörn-Henrik Jacobsen, David Duvenaud, Mohammad Norouzi, Kevin SwerskyInternational Conference on Learning Representations, 2020. paper | code | video poster | bibtex |
|
SUMO: Unbiased Estimation of Log Marginal Probability for Latent Variable Models
We introduce an unbiased estimator of the log marginal likelihood and its gradients for latent variable models. In an encoder-decoder architecture, the parameters of the encoder can be optimized to minimize its variance of this estimator. We show that models trained using our estimator give better test-set likelihoods than a standard importance-sampling based approach for the same average computational cost. Yucen Luo, Alex Beatson, Mohammad Norouzi, Jun Zhu, David Duvenaud, Ryan P. Adams, Ricky Tian Qi ChenInternational Conference on Learning Representations, 2020. paper | video poster | bibtex |

|
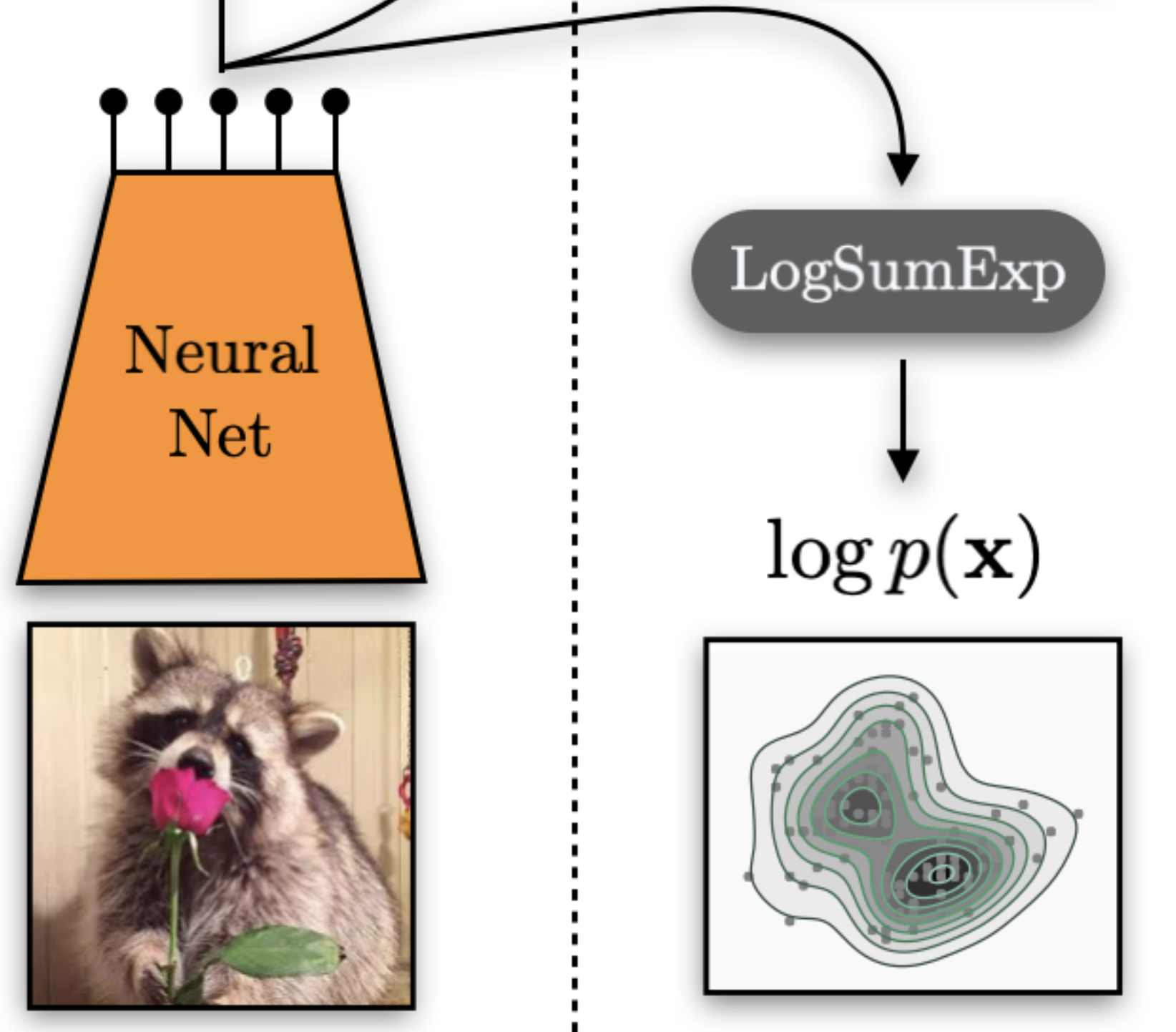
Neural Networks with Cheap Differential Operators
We introduce a family of restricted neural network architectures that allow efficient computation of a family of differential operators involving dimension-wise derivatives, such as the divergence. Our proposed architecture has a Jacobian matrix composed of diagonal and hollow (zero-diagonal) components. We demonstrate these cheap differential operators on root-finding problems, exact density evaluation for continuous normalizing flows, and evaluating the Fokker-Planck equation. Ricky Tian Qi Chen and David DuvenaudNeural Information Processing Systems, 2019. paper | slides | bibtex |
|
|
Efficient Graph Generation with Graph Recurrent Attention Networks
We propose a new family of efficient and expressive deep generative models of graphs. We use graph neural networks to generate new edges conditioned on the already-sampled parts of the graph, reducing dependence on node ordering and bypasses the bottleneck caused by the sequential nature of RNNs. We achieve state-of-the-art time efficiency and sample quality compared to previous models, and generate graphs of up to 5000 nodes. Renjie Liao, Yujia Li, Yang Song, Shenlong Wang, Charlie Nash, William L. Hamilton, David Duvenaud, Raquel Urtasun, Rich ZemelNeural Information Processing Systems, 2019. paper | code | bibtex |
|
|
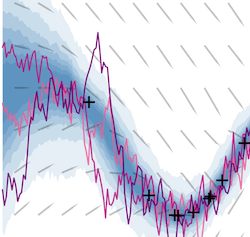
Latent ODEs for Irregularly-Sampled Time Series
Time series with non-uniform intervals occur in many applications, and are difficult to model using standard recurrent neural networks. We generalize RNNs to have continuous-time hidden dynamics defined by ordinary differential equations. These models can naturally handle arbitrary time gaps between observations, and can explicitly model the probability of observation times using Poisson processes. Yulia Rubanova, Ricky Tian Qi Chen, David DuvenaudNeural Information Processing Systems, 2019. paper | code | bibtex |
|
|
Residual Flows for Invertible Generative Modeling
Invertible residual networks provide transformations where only Lipschitz conditions rather than architectural constraints are needed for enforcing invertibility. We give a tractable unbiased estimate of the log density, and improve these models in other ways. The resulting approach, called Residual Flows, achieves state-of-the-art performance on density estimation amongst flow-based models. Ricky Tian Qi Chen, Jens Behrmann, David Duvenaud, Jörn-Henrik JacobsenNeural Information Processing Systems, 2019. paper | code | slides | bibtex |
|
|
Invertible Residual Networks
We show that standard ResNet architectures can be made invertible, allowing the same model to be used for classification, density estimation, and generation. Our approach only requires adding a simple normalization step during training. Invertible ResNets define a generative model which can be trained by maximum likelihood on unlabeled data. To compute likelihoods, we introduce a tractable approximation to the Jacobian log-determinant of a residual block. Our empirical evaluation shows that invertible ResNets perform competitively with both stateof-the-art image classifiers and flow-based generative models, something that has not been previously achieved with a single architecture. Jens Behrmann, Will Grathwohl, Ricky Tian Qi Chen, David Duvenaud, Jörn-Henrik JacobsenInternational Conference on Machine Learning, 2019. paper | code | slides | bibtex |
|
|
Self-Tuning Networks: Bilevel Optimization of Hyperparameters using Structured Best-Response Functions
Hyperparameter optimization can be formulated as a bilevel optimization problem, where the optimal parameters on the training set depend on the hyperparameters. We adapt regularization hyperparameters for neural networks by fitting compact approximations to the best-response function, which maps hyperparameters to optimal weights and biases. We show how to construct scalable best-response approximations for neural networks by modeling the best-response as a single network whose hidden units are gated conditionally on the regularizer. Matthew MacKay, Paul Vicol, Jonathan Lorraine, David Duvenaud, Roger GrosseInternational Conference on Learning Representations, 2019. paper | code | slides | bibtex |
|
|
FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models
Training normalized generative models such as Real NVP or Glow requires restricting their architectures to allow cheap computation of Jacobian determinants. Alternatively, if the transformation is specified by an ordinary differential equation, then the Jacobian's trace can be used. We use Hutchinson's trace estimator to give a scalable unbiased estimate of the log-density. The result is a continuous-time invertible generative model with unbiased density estimation and one-pass sampling, while allowing unrestricted neural network architectures. We demonstrate our approach on high-dimensional density estimation, image generation, and variational inference, improving the state-of-the-art among exact likelihood methods with efficient sampling. Will Grathwohl, Ricky Tian Qi Chen, Jesse Bettencourt, Ilya Sutskever, David DuvenaudInternational Conference on Learning Representations, 2019. Oral presentation. paper | slides | code | bibtex |
|
|
Explaining Image Classifiers by Counterfactual Generation
When an image classifier makes a prediction, which parts of the image are relevant and why? We can rephrase this question to ask: which parts of the image, if they were not seen by the classifier, would most change its decision? Producing an answer requires marginalizing over images that could have been seen but weren't. We can sample plausible image in-fills by conditioning a generative model on the rest of the image. We then optimize to find the image regions that most change the classifier's decision after in-fill. Our approach contrasts with ad-hoc in-filling approaches, such as blurring or injecting noise, which generate inputs far from the data distribution, and ignore informative relationships between different parts of the image. Our method produces more compact and relevant saliency maps, with fewer artifacts compared to previous methods. Chun-Hao Chang, Elliot Creager, Anna Goldenberg, David DuvenaudInternational Conference on Learning Representations, 2019. paper | code | slides | bibtex |

|
Stochastic Hyperparameter Optimization Through Hypernetworks
Models are usually tuned by nesting optimization of model weights inside the optimization of hyperparameters. We collapse this nested optimization into joint stochastic optimization of weights and hyperparameters. Our method trains a neural net to output approximately optimal weights as a function of hyperparameters. This method converges to locally optimal weights and hyperparameters for sufficiently large hypernetworks. We compare this method to standard hyperparameter optimization strategies and demonstrate its effectiveness for tuning thousands of hyperparameters. Jonathan Lorraine, David Duvenaudpaper | bibtex | slides | code |
|
|
Neural Ordinary Differential Equations
We introduce a new family of deep neural network models. Instead of specifying a discrete sequence of hidden layers, we parameterize the derivative of the hidden state using a neural network. The output of the network is computed using a black-box differential equation solver. These continuous-depth models have constant memory cost, adapt their evaluation strategy to each input, and can explicitly trade numerical precision for speed. We demonstrate these properties in continuous-depth residual networks and continuous-time latent variable models. We also construct continuous normalizing flows, a generative model that can train by maximum likelihood, without partitioning or ordering the data dimensions. For training, we show how to scalably backpropagate through any ODE solver, without access to its internal operations. This allows end-to-end training of ODEs within larger models. Ricky Tian Qi Chen, Yulia Rubanova, Jesse Bettencourt, David DuvenaudNeural Information Processing Systems, 2018. Best paper award. paper | bibtex | slides | talk | code |

|
Isolating Sources of Disentanglement in Variational Autoencoders
Variational autoencoders can be regularized to produce disentangled representations, in which each latent dimension has a distinct meaning. However, existing regularization schemes also hurt the model's ability to model the data. We show a simple method to regularize only the part that causes disentanglement. We also give a principled, classifier-free measure of disentanglement called the mutual information gap. Ricky Tian Qi Chen, Xuechen Li, Roger Grosse, David DuvenaudNeural Information Processing Systems, 2018. Oral presentation. paper | bibtex | slides | code |

|
Noisy Natural Gradient as Variational Inference
Bayesian neural nets combine the flexibility of deep learning with uncertainty estimation, but are usually approximated using a fully-factorized Guassian. We show that natural gradient ascent with adaptive weight noise implicitly fits a variational Gassuain posterior. This insight allows us to train full-covariance, fully factorized, or matrix-variate Gaussian variational posteriors using noisy versions of natural gradient, Adam, and K-FAC, respectively, allowing us to scale to modern-size convnets. Our noisy K-FAC algorithm makes better predictions and has better-calibrated uncertainty than existing methods. This leads to more efficient exploration in active learning and reinforcement learning. Guodong Zhang, Shengyang Sun, David Duvenaud, Roger GrosseInternational Conference on Machine Learning, 2018 paper | bibtex | video | code |
|
|
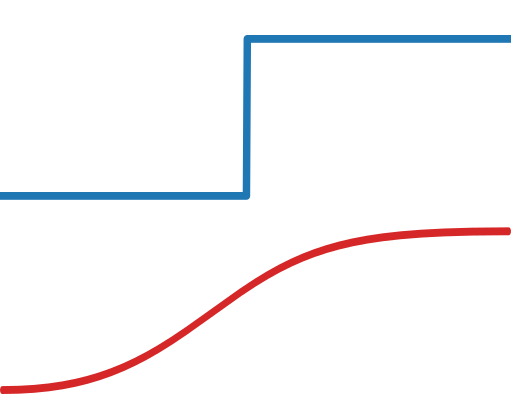
Inference Suboptimality in Variational Autoencoders
Amortized inference allows latent-variable models to scale to large datasets. The quality of approximate inference is determined by two factors: a) the capacity of the variational distribution to match the true posterior and b) the ability of the recognition net to produce good variational parameters for each datapoint. We show that the recognition net giving bad variational parameters is often a bigger problem than using a Gaussian approximate posterior, because the generator can adapt to it. |
|
Backpropagation through the Void: Optimizing control variates for black-box gradient estimation
We learn low-variance, unbiased gradient estimators for any function of random variables. We backprop through a neural net surrogate of the original function, which is optimized to minimize gradient variance during the optimization of the original objective. We train discrete latent-variable models, and do continuous and discrete reinforcement learning with an adaptive, action-conditional baseline. Will Grathwohl, Dami Choi, Yuhuai Wu, Geoff Roeder, David DuvenaudInternational Conference on Learning Representations, 2018 paper | code | slides | bibtex |
|
|
Automatic chemical design using a data-driven continuous representation of molecules
We develop a molecular autoencoder, which converts discrete representations of molecules to and from a continuous representation. This allows gradient-based optimization through the space of chemical compounds. Continuous representations also let us generate novel chemicals by interpolating between molecules. Rafa Gómez-Bombarelli, Jennifer Wei, David Duvenaud, José Miguel Hernández-Lobato, Benjamín Sánchez-Lengeling, Sheberla, Dennis, Jorge Aguilera-Iparraguirre, Timothy Hirzel, Ryan P. Adams, Alán Aspuru-GuzikAmerican Chemical Society Central Science, 2018 paper | bibtex | slides | code |
|
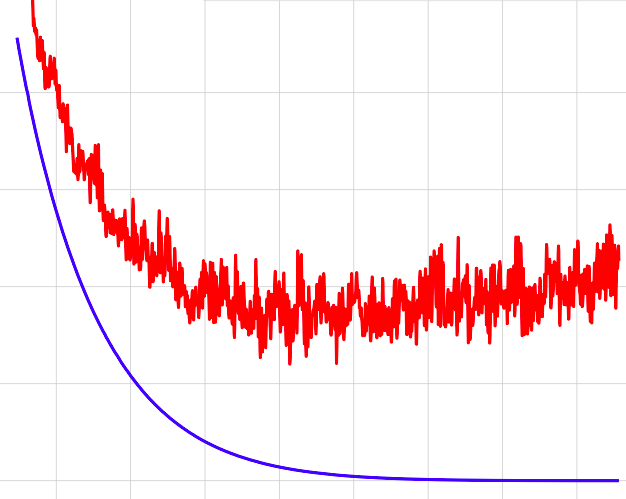
Sticking the landing: Simple, lower-variance gradient estimators for variational inference
We give a simple recipe for reducing the variance of the gradient of the variational evidence lower bound.
The entire trick is just removing one term from the gradient.
Removing this term leaves an unbiased gradient estimator whose variance approaches zero as the approximate posterior approaches the exact posterior.
We also generalize this trick to mixtures and importance-weighted posteriors.
Neural Information Processing Systems, 2017 paper | bibtex | code |
|
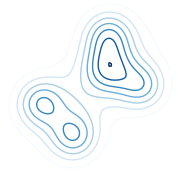
Reinterpreting importance-weighted autoencoders
The standard interpretation of importance-weighted autoencoders is that they maximize a tighter, multi-sample lower bound than the standard evidence lower bound. We give an alternate interpretation: it optimizes the standard lower bound, but using a more complex distribution, which we show how to visualize. Chris Cremer, Quaid Morris, David DuvenaudICLR Workshop track, 2017 paper | bibtex |

|
Composing graphical models with neural networks for structured representations and fast inference
We propose a general modeling and inference framework that combines the complementary strengths of probabilistic graphical models and deep learning methods. Our model family composes latent graphical models with neural network observation likelihoods. All components are trained simultaneously. We use this framework to automatically segment and categorize mouse behavior from raw depth video. Matthew Johnson, David Duvenaud, Alex Wiltschko, Bob Datta, Ryan P. AdamsNeural Information Processing Systems, 2016 paper | video | code | slides | bibtex |
|
Probing the Compositionality of Intuitive Functions
How do people learn about complex functional structure? We propose that humans use compositionality: complex structure is decomposed into simpler building blocks. We formalize this idea using a grammar over Gaussian process kernels. We show that people prefer compositional extrapolations, and argue that this is consistent with broad principles of human cognition. Eric Shulz, Joshua B. Tenenbaum, David Duvenaud, Maarten Speekenbrink, Samuel J. GershmanNeural Information Processing Systems, 2016 paper | video | bibtex |
|
|
Autograd: Reverse-mode differentiation of native Python
Autograd automatically differentiates native Python and Numpy code. It can handle loops, ifs, recursion and closures, and it can even take derivatives of its own derivatives. It uses reverse-mode differentiation (a.k.a. backpropagation), which means it's efficient for gradient-based optimization. Check out the tutorial and the examples directory. Dougal Maclaurin, David Duvenaud, Matthew Johnsoncode | bibtex | slides |
|
Early Stopping as Nonparametric Variational Inference
Stochastic gradient descent samples from a nonparametric distribution, implicitly defined by the transformation of the initial distribution by an optimizer. We track the loss of entropy during optimization to get a scalable estimate of the marginal likelihood. This Bayesian interpretation of SGD gives a theoretical foundation for popular tricks such as early stopping and ensembling. We evaluate our marginal likelihood estimator on neural network models. David Duvenaud, Dougal Maclaurin, Ryan P. AdamsArtificial Intelligence and Statistics, 2016 paper | slides | code | bibtex |
|
|
Convolutional Networks on Graphs for Learning Molecular Fingerprints
We introduce a convolutional neural network that operates directly on graphs, allowing end-to-end learning of the entire feature pipeline. This architecture generalizes standard molecular fingerprints. These data-driven features are more interpretable, and have better predictive performance on a variety of tasks. Related work led to our Nature Materials paper. David Duvenaud, Dougal Maclaurin, Jorge Aguilera-Iparraguirre, Rafa Gómez-Bombarelli, Timothy Hirzel, Alán Aspuru-Guzik, Ryan P. AdamsNeural Information Processing Systems, 2015 pdf | slides | code | bibtex |
|
|
Gradient-based Hyperparameter Optimization through Reversible Learning
Tuning hyperparameters of learning algorithms is hard because gradients are usually unavailable. We compute exact gradients of the validation loss with respect to all hyperparameters by differentiating through the entire training procedure. This lets us optimize thousands of hyperparameters, including step-size and momentum schedules, weight initialization distributions, richly parameterized regularization schemes, and neural net architectures. Dougal Maclaurin, David Duvenaud, Ryan P. AdamsInternational Conference on Machine Learning, 2015 pdf | slides | code | bibtex |
|
|
Probabilistic ODE Solvers with Runge-Kutta Means
We show that some standard differential equation solvers are equivalent to Gaussian process predictive means, giving them a natural way to handle uncertainty. This work is part of the larger probabilistic numerics research agenda, which interprets numerical algorithms as inference procedures so they can be better understood and extended. Michael Schober, David Duvenaud, Philipp HennigNeural Information Processing Systems, 2014. Oral presentation. pdf | slides | bibtex |

|
PhD Thesis: Automatic Model Construction with Gaussian Processes
|
|
|
Automatic Construction and Natural-Language Description of Nonparametric Regression Models
We wrote a program which automatically writes reports summarizing automatically constructed models. A prototype for the automatic statistician project. James Robert Lloyd, David Duvenaud, Roger Grosse, Joshua B. Tenenbaum, Zoubin GhahramaniAssociation for the Advancement of Artificial Intelligence (AAAI), 2014 pdf | code | bibtex |

|
Avoiding Pathologies in Very Deep Networks
To suggest better neural network architectures, we analyze the properties of different priors on compositions of functions. We study deep Gaussian processes, a type of infinitely-wide, deep neural net. We also examine infinitely deep covariance functions. Finally, we show that you get additive covariance if you do dropout on Gaussian processes. David Duvenaud, Oren Rippel, Ryan P. Adams, Zoubin GhahramaniArtificial Intelligence and Statistics, 2014 pdf | code | slides | video of 50-layer warping | video of 50-layer density | bibtex |
|
|
Warped Mixtures for Nonparametric Cluster Shapes
If you fit a mixture of Gaussians to a single cluster that is curved or heavy-tailed, your model will report that the data contains many clusters! To fix this problem, we warp a latent mixture of Gaussians into nonparametric cluster shapes. The low-dimensional latent mixture model summarizes the properties of the high-dimensional density manifolds describing the data. Tomoharu Iwata, David Duvenaud, Zoubin GhahramaniUncertainty in Artificial Intelligence, 2013 pdf | code | slides | talk | bibtex |
|
|
Structure Discovery in Nonparametric Regression through Compositional Kernel Search
How could an AI do statistics? To search through an open-ended class of structured, nonparametric regression models, we introduce a simple grammar which specifies composite kernels. These structured models often allow an interpretable decomposition of the function being modeled, as well as long-range extrapolation. Many common regression methods are special cases of this large family of models. David Duvenaud, James Robert Lloyd, Roger Grosse, Joshua B. Tenenbaum, Zoubin GhahramaniInternational Conference on Machine Learning, 2013 pdf | code | short slides | long slides | bibtex |
|
|
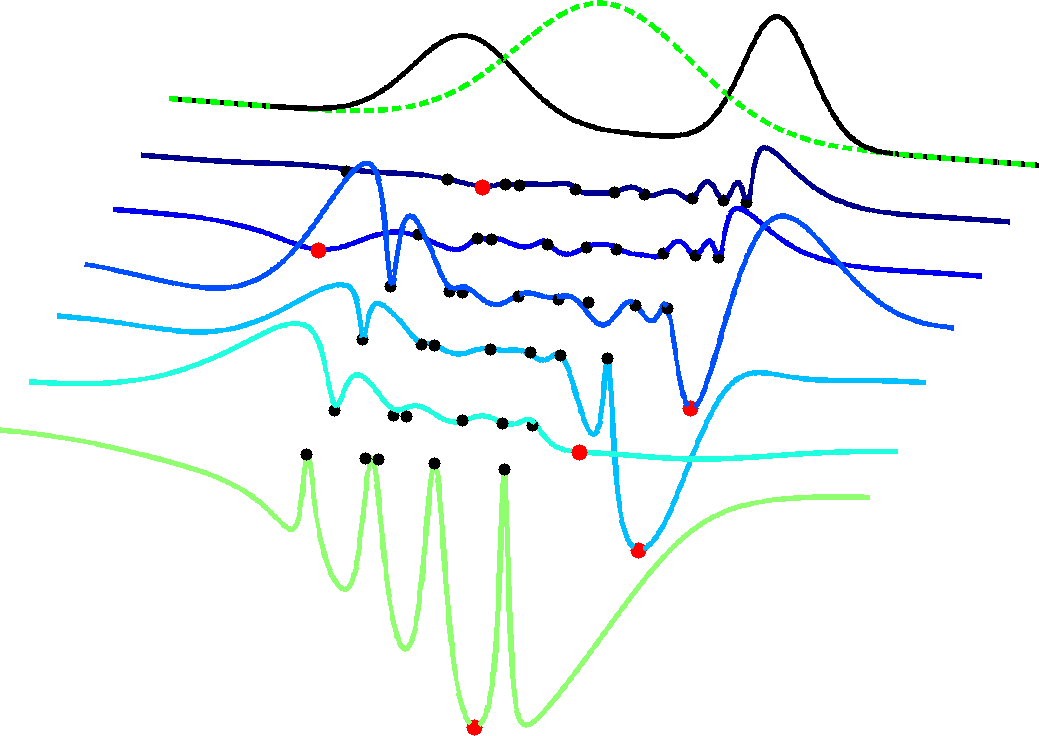
HarlMCMC Shake
Two short animations illustrate the differences between a Metropolis-Hastings (MH) sampler and a Hamiltonian Monte Carlo (HMC) sampler, to the tune of the Harlem shake. This inspired several followup videos - benchmark your MCMC algorithm on these distributions! by Tamara Broderick and David Duvenaudvideo | code |
|
Active Learning of Model Evidence using Bayesian Quadrature
Instead of the usual Monte-Carlo based methods for computing integrals of likelihood functions, we instead construct a surrogate model of the likelihood function, and infer its integral conditioned on a set of evaluations. This allows us to evaluate the likelihood wherever is most informative, instead of running a Markov chain. This means fewer evaluations to estimate integrals. Michael Osborne, David Duvenaud, Roman Garnett, Carl Rasmussen, Stephen Roberts, Zoubin GhahramaniNeural Information Processing Systems, 2012 pdf | code | slides | related talk | bibtex |
|
Optimally-Weighted Herding is Bayesian Quadrature
We prove several connections between a numerical integration method that minimizes a worst-case bound (herding), and a model-based way of estimating integrals (Bayesian quadrature). It turns out that both optimize the same criterion, and that Bayesian Quadrature does this optimally. Ferenc Huszár and David DuvenaudUncertainty in Artificial Intelligence, 2012. Oral presentation. pdf | code | slides | talk | bibtex |

|
Additive Gaussian Processes
When functions have additive structure, we can extrapolate further than with standard Gaussian process models. We show how to efficiently integrate over exponentially-many ways of modeling a function as a sum of low-dimensional functions. David Duvenaud, Hannes Nickisch, Carl RasmussenNeural Information Processing Systems, 2011 pdf | code | slides | bibtex |
|
Multiscale Conditional Random Fields for Semi-supervised Labeling and Classification
How can we take advantage of images labeled only by what objects they contain?
By combining information across different scales, we use image-level labels (such as Canadian Conference on Computer and Robot Vision, 2011 pdf | code | slides | bibtex |