
Department of Computer Science
University of Toronto
10 King's College Road, Rm.3302
Toronto, Ontario
Canada, M5S 3G4
r n t o r o [at] c s [dot] t o r o n t o [dot] e d u
Curriculum Vitae
Google Scholar
Semantic Scholar
Bitbucket
|
Rodrigo Toro Icarte Department of Computer Science University of Toronto 10 King's College Road, Rm.3302 Toronto, Ontario Canada, M5S 3G4 r n t o r o [at] c s [dot] t o r o n t o [dot] e d u Curriculum Vitae Google Scholar Semantic Scholar Bitbucket |
Artificial Intelligence (AI) is an aspiration, an idea conceived at the beginning of computer science, that would revolutionize the world if achieved. The ultimate goal of AI is to create agents (i.e., computer programs) that can solve problems in the world as well as humans. To advance this vision, most researchers focus on studying particular aspects of AI independently, such as learning, perception, reasoning, or language. This approach has led to important advances and cutting-edge technologies, but it has a drawback. The agents that result from only considering one aspect of AI have a narrow sense of intelligence. They outperform humans in few concrete tasks (e.g., playing the game of Go) while being useless in other contexts. Building agents that solve problems as well as humans requires a global view of AI. My research embraces this view by incorporating insights from three core aspects of intelligence: knowledge, reasoning, and learning, in service of building general-purpose agents with theoretical guarantees and state-of-the-art performance.
I am a PhD student in the knowledge representation group at the University of Toronto. I am also a member of the Canadian Artificial Intelligence Association and the Vector Institute. My supervisor is Sheila McIlraith. I did my undergrad in Computer Engineering and MSc in Computer Science at Pontificia Universidad Católica de Chile (PUC). My master's degree was co-supervised by Alvaro Soto and Jorge Baier. While I was at PUC, I taught the undergraduate course "Introduction to Computer Programming" [course material].
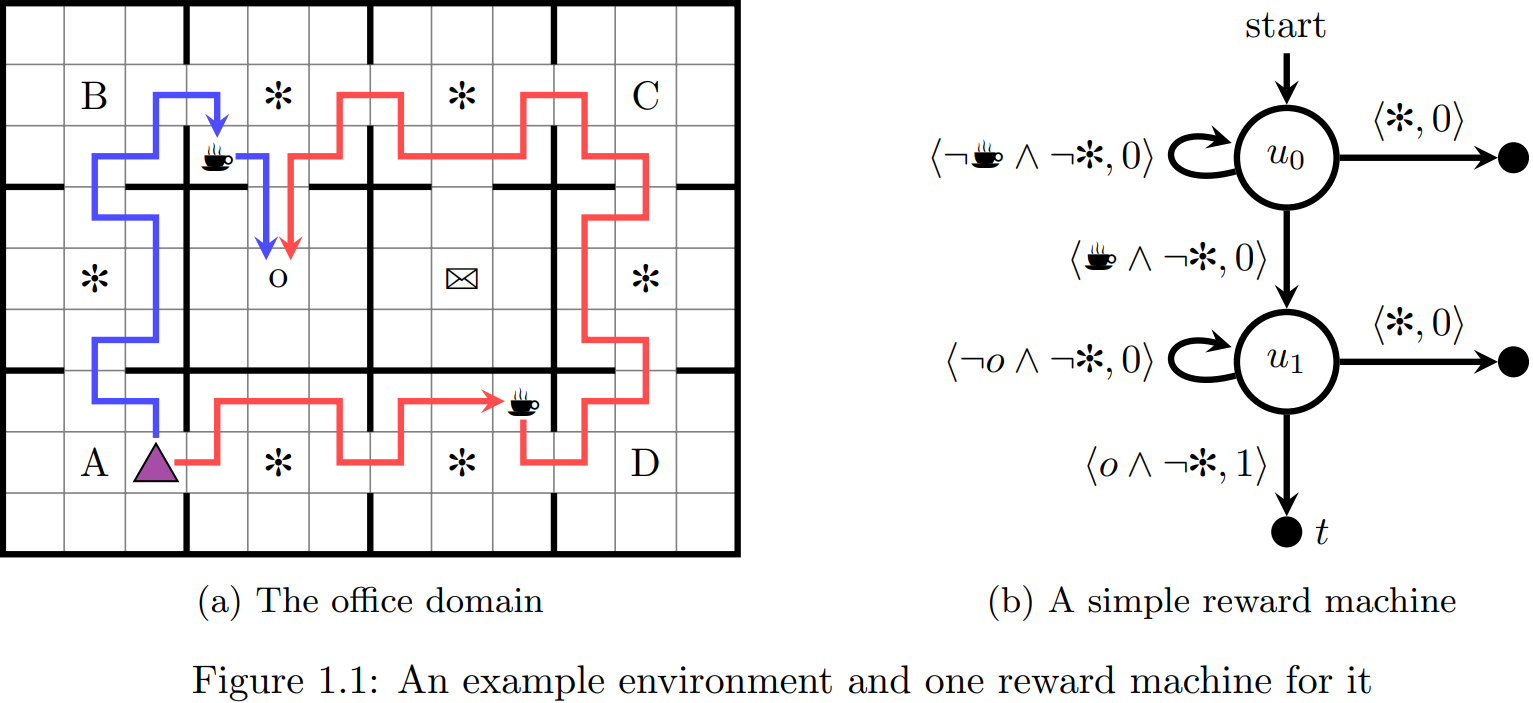 |
Abstract: Reinforcement learning involves the study of how to solve sequential decision-making problems using minimal supervision or prior knowledge. In contrast to most methods for automated decision making, reinforcement learning agents do not require access to a formal description of the problem in order to find optimal solutions. Instead, such agents learn optimal behaviour using a trial-and-error strategy. This learning strategy makes reinforcement learning a strong candidate to tackle real-world problems with complex dynamics. However, there are two core challenges that limit the use of reinforcement learning in the real world: sample efficiency and partial observability. In this dissertation, we tackle these two problems through the creation of reward machines. Reward machines are automata-based representations of a reward function that expose reward structures to the agent. We show that agents can exploit these structures to improve their sample efficiency and their performance under partial observability. In particular, we propose (i) to use decomposition methods and reward shaping to improve sample efficiency based on a given reward machine, and (ii) to use reward machines as external memory and solve partially observable tasks by learning reward machines. In both cases, we provide theoretical and empirical evidence of the benefits of utilizing reward machines to tackle these problems. Finally, we conclude this dissertation with a discussion of the role that reward machines can play in tackling other long-standing problems in reinforcement learning, such as developing agents with interpretable behaviours, providing guarantees that an optimal policy is safe, and creating agents that can understand instructions. Link to the thesis. |
Challenges to Solving Combinatorially Hard Long-Horizon Deep RL Tasks
by A. C. Li, P. Vaezipoor, R. Toro Icarte, and S. A. McIlraith.
 |
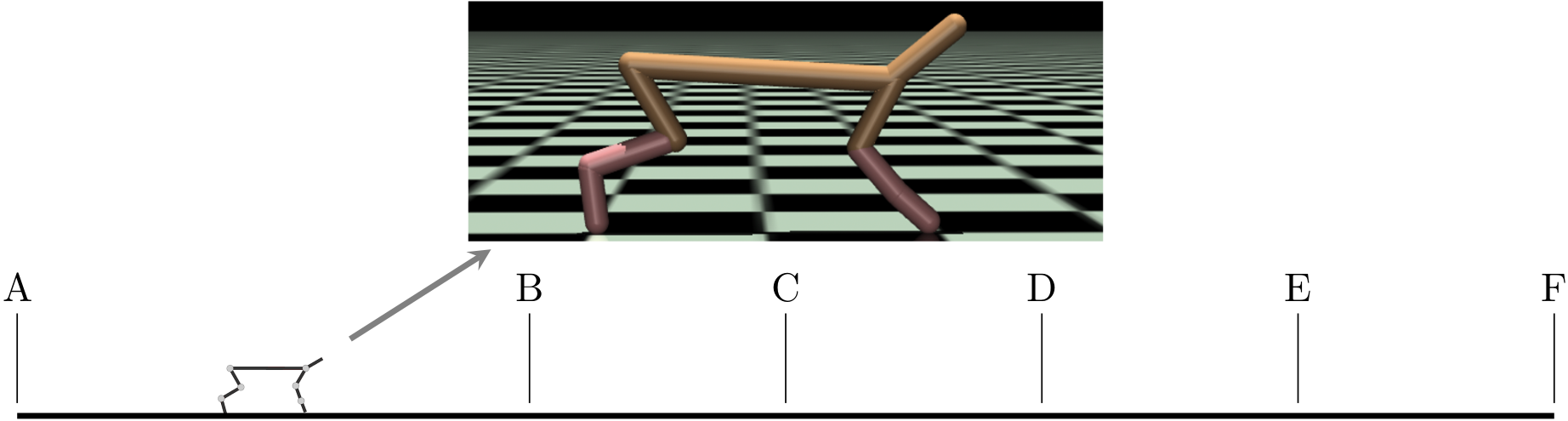
Abstract: Deep reinforcement learning has shown promise in discrete domains requiring complex reasoning, including games such as Chess, Go, and Hanabi. However, this type of reasoning is less often observed in long-horizon, continuous domains with high-dimensional observations, where instead RL research has predominantly focused on problems with simple high-level structure (e.g. opening a drawer or moving a robot as fast as possible). Inspired by combinatorially hard optimization problems, we propose a set of robotics tasks which admit many distinct solutions at the high-level, but require reasoning about states and rewards thousands of steps into the future for the best performance. Critically, while RL has traditionally suffered on complex, long-horizon tasks due to sparse rewards, our tasks are carefully designed to be solvable without specialized exploration. Nevertheless, our investigation finds that standard RL methods often neglect long-term effects due to discounting, while general-purpose hierarchical RL approaches struggle unless additional abstract domain knowledge can be exploited. |
Learning Reward Machines: A Study in Partially Observable Reinforcement Learning
by R. Toro Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith.
 |
Abstract: Reinforcement learning (RL) is a central problem in artificial intelligence. This problem consists of defining artificial agents that can learn optimal behaviour by interacting with an environment -- where the optimal behaviour is defined with respect to a reward signal that the agent seeks to maximize. Reward machines (RMs) provide a structured, automata-based representation of a reward function that enables an RL agent to decompose an RL problem into structured subproblems that can be efficiently learned via off-policy learning. Here we show that RMs can be learned from experience, instead of being specified by the user, and that the resulting problem decomposition can be used to effectively solve partially observable RL problems. We pose the task of learning RMs as a discrete optimization problem where the objective is to find an RM that decomposes the problem into a set of subproblems such that the combination of their optimal memoryless policies is an optimal policy for the original problem. We show the effectiveness of this approach on three partially observable domains, where it significantly outperforms A3C, PPO, and ACER, and discuss its advantages, limitations, and broader potential. |
The Act of Remembering: A Study in Partially Observable Reinforcement Learning
by R. Toro Icarte, R. Valenzano, T. Q. Klassen, P. Christoffersen, A. Farahmand, and S. A. McIlraith.
|
Abstract: Reinforcement Learning (RL) agents typically learn memoryless policies—policies that only consider the last observation when selecting actions. Learning memoryless policies is efficient and optimal in fully observable environments. However, some form of memory is necessary when RL agents are faced with partial observability. In this paper, we study a lightweight approach to tackle partial observability in RL. We provide the agent with an external memory and additional actions to control what, if anything, is written to the memory. At every step, the current memory state is part of the agent's observation, and the agent selects a tuple of actions: one action that modifies the environment and another that modifies the memory. When the external memory is sufficiently expressive, optimal memoryless policies yield globally optimal solutions. Unfortunately, previous attempts to use external memory in the form of binary memory have produced poor results in practice. Here, we investigate alternative forms of memory in support of learning effective memoryless policies. Our novel forms of memory outperform binary and LSTM-based memory in well-established partially observable domains. Link to the paper. |
(IJCAI22) Real-Time Heuristic Search with LTLf Goals
by J. Middleton, R. Toro Icarte, and J. Baier.
 |
Abstract: In Real-Time Heuristic Search (RTHS) we are given a search graph G, a heuristic, and the objective is to find a path from a given start node to a given goal node in G. As such, one does not impose any trajectory constraints on the path, besides reaching the goal. In this paper we consider a version of RTHS in which temporally extended goals can be defined on the form of the path. Such goals are specified in Linear Temporal Logic over Finite Traces (LTLf), an expressive language that has been considered in many other frameworks, such as Automated Planning, Synthesis, and Reinforcement Learning, but has not yet been studied in the context of RTHS. We propose a general automata-theoretic approach for RTHS, whereby LTLf goals are supported as the result of searching over the cross product of the search graph and the automaton for the LTLf goal; specifically, we describe LTL-LRTA*, a version of LSS-LRTA*. Second, we propose an approach to produce heuristics for LTLf goals, based on existing goal-dependent heuristics. Finally, we propose a greedy strategy for RTHS with LTLf goals, which focuses search to make progress over the structure of the automaton; this yields LTL-LRTA*+A. In our experimental evaluation over standard benchmarks we show LTL-LRTA*+A may outperform LTL-LRTA* substantially for a variety of LTLf goals. |
(ApplSci) Solving Task Scheduling Problems in Dew Computing via Deep Reinforcement Learning
by P. Sanabria, T. F. Tapia, R. Toro Icarte, and A. Neyem.
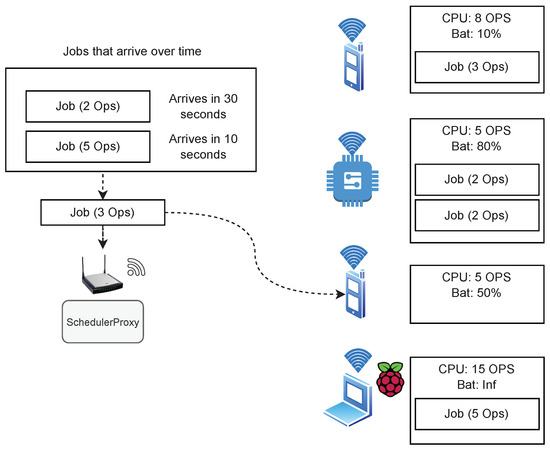 |
Abstract: Due to mobile and IoT devices’ ubiquity and their ever-growing processing potential, Dew computing environments have been emerging topics for researchers. These environments allow resource-constrained devices to contribute computing power to others in a local network. One major challenge in these environments is task scheduling: that is, how to distribute jobs across devices available in the network. In this paper, we propose to distribute jobs in Dew environments using artificial intelligence (AI). Specifically, we show that an AI agent, known as Proximal Policy Optimization (PPO), can learn to distribute jobs in a simulated Dew environment better than existing methods -- even when tested over job sequences that are five times longer than the sequences used during the training. We found that using our technique, we can gain up to 77% in performance compared with using human-designed heuristics. |
(JAIR) Reward Machines: Exploiting Reward Function Structure in Reinforcement Learning
by R. Toro Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith.
 |
Abstract: Reinforcement learning (RL) methods usually treat reward functions as black boxes. As such, these methods must extensively interact with the environment in order to discover rewards and optimal policies. In most RL applications, however, users have to program the reward function and, hence, there is the opportunity to treat reward functions as white boxes instead—to show the reward function's code to the RL agent so it can exploit its internal structures to learn optimal policies faster. In this paper, we show how to accomplish this idea in two steps. First, we propose reward machines (RMs), a type of finite state machine that supports the specification of reward functions while exposing reward function structure. We then describe different methodologies to exploit such structures, including automated reward shaping, task decomposition, and counterfactual reasoning for data augmentation. Experiments on tabular and continuous domains show the benefits of exploiting reward structure across different tasks and RL agents. |
(AAMAS22) Be Considerate: Avoiding Negative Side Effects in Reinforcement Learning
by P. Alizadeh Alamdari, T. Q. Klassen, R. Toro Icarte, and S. A. McIlraith.
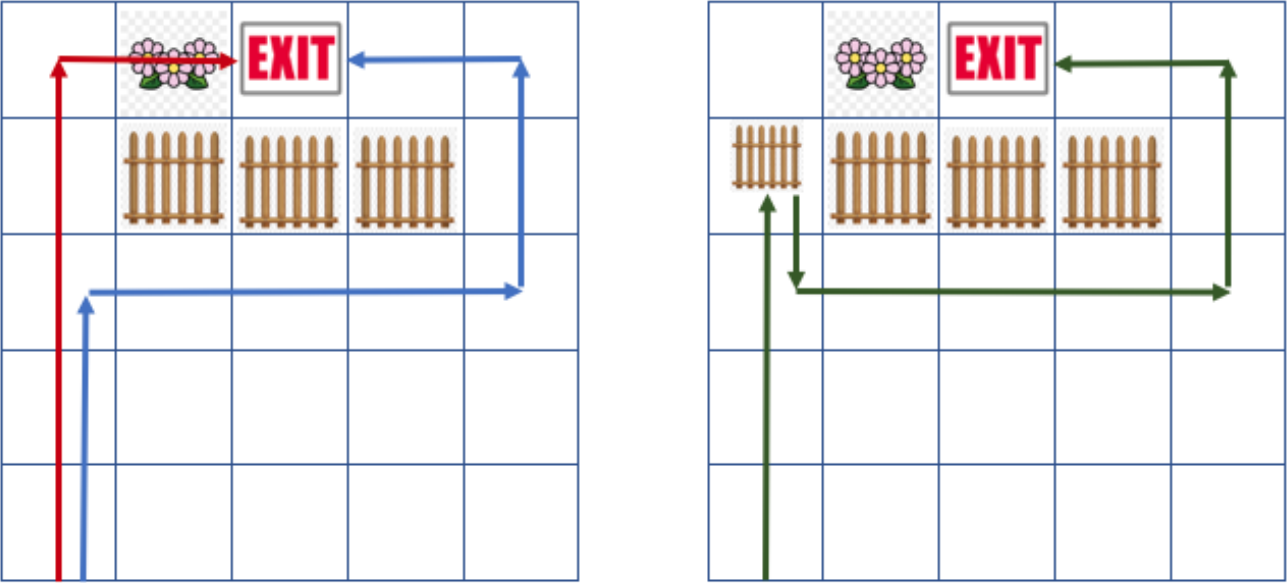 |
Abstract: In sequential decision making -- whether it's realized with or without the benefit of a model -- objectives are often underspecified or incomplete. This gives discretion to the acting agent to realize the stated objective in ways that may result in undesirable outcomes, including inadvertently creating an unsafe environment or indirectly impacting the agency of humans or other agents that typically operate in the environment. In this paper, we explore how to build a reinforcement learning (RL) agent that contemplates the impact of its actions on the wellbeing and agency of others in the environment, most notably humans. We endow RL agents with the ability to contemplate such impact by augmenting their reward based on expectation of future return by others in the environment, providing different criteria for characterizing impact. We further endow these agents with the ability to differentially factor this impact into their decision making, manifesting behaviour that ranges from self-centred to self-less, as demonstrated by experiments in gridworld environments. Link to the paper. |
(ICML21) LTL2Action: Generalizing LTL Instructions for Multi-Task RL
by P. Vaezipoor, A. C. Li, R. Toro Icarte, and S. A. McIlraith.
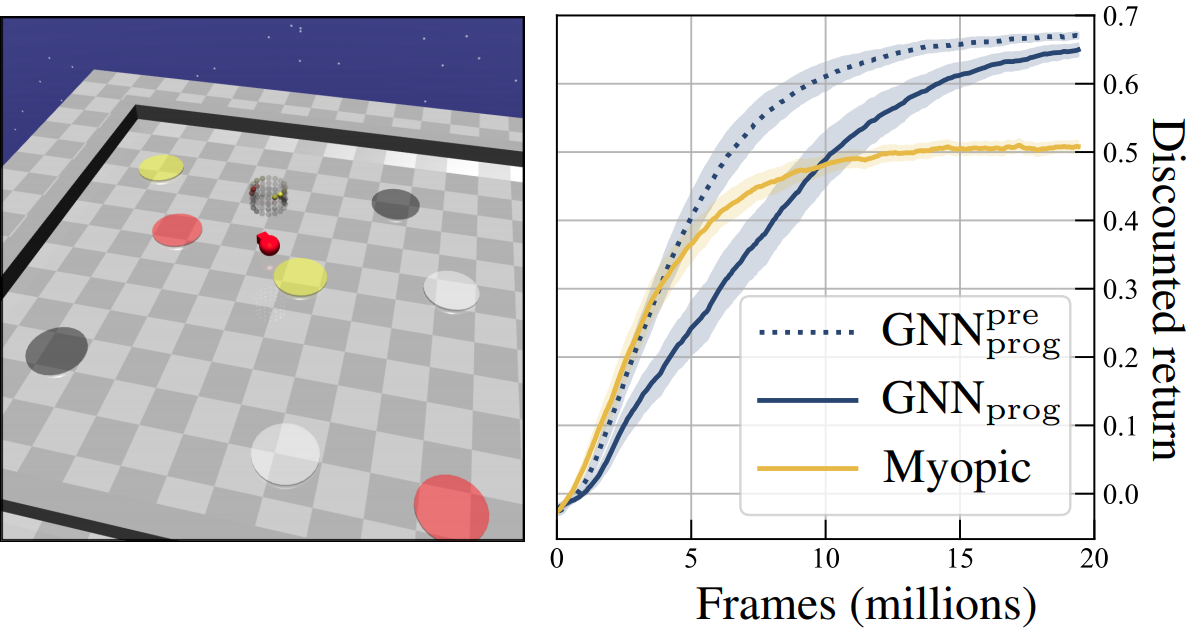 |
Abstract: We address the problem of teaching a deep reinforcement learning (RL) agent to follow instructions in multi-task environments. We employ a well-known formal language -- linear temporal logic (LTL) -- to specify instructions, using a domain-specific vocabulary. We propose a novel approach to learning that exploits the compositional syntax and the semantics of LTL, enabling our RL agent to learn task-conditioned policies that generalize to new instructions, not observed during training. The expressive power of LTL supports the specification of a diversity of complex temporally extended behaviours that include conditionals and alternative realizations. Experiments on discrete and continuous domains demonstrate the strength of our approach in learning to solve (unseen) tasks, given LTL instructions. |
(AAAI21) Interpretable Sequence Classification via Discrete Optimization
by M. Shvo, A. C. Li, R. Toro Icarte, and S. A. McIlraith.
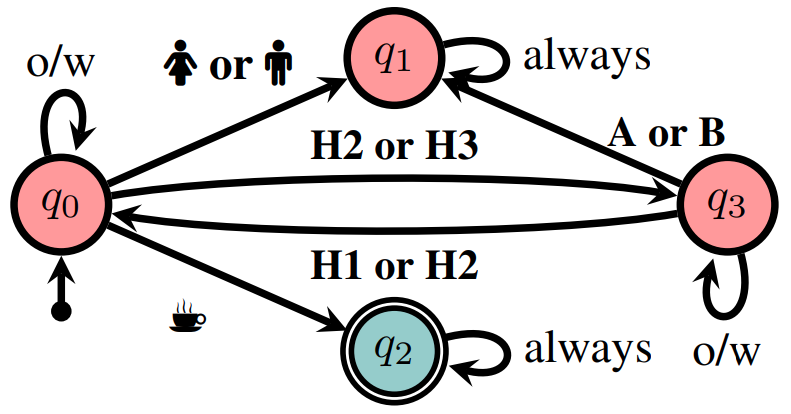 |
Abstract: Sequence classification is the task of predicting a class label given a sequence of observations. In many applications such as healthcare monitoring or intrusion detection, early classification is crucial to prompt intervention. In this work, we learn sequence classifiers that favour early classification from an evolving observation trace. While many state-of-the-art sequence classifiers are neural networks, and in particular LSTMs, our classifiers take the form of finite state automata and are learned via discrete optimization. Our automata-based classifiers are interpretable—supporting explanation, counterfactual reasoning, and human-in-the-loop modification—and have strong empirical performance. Experiments over a suite of goal recognition and behaviour classification datasets show our learned automata-based classifiers to have comparable test performance to LSTM-based classifiers, with the added advantage of being interpretable. Link to the paper. |
(CCAI21) AppBuddy: Learning to Accomplish Tasks in Mobile Apps via Reinforcement Learning
by M. Shvo, Z. Hu, R. Toro Icarte, I. Mohomed, A. Jepson, and S. A. McIlraith.
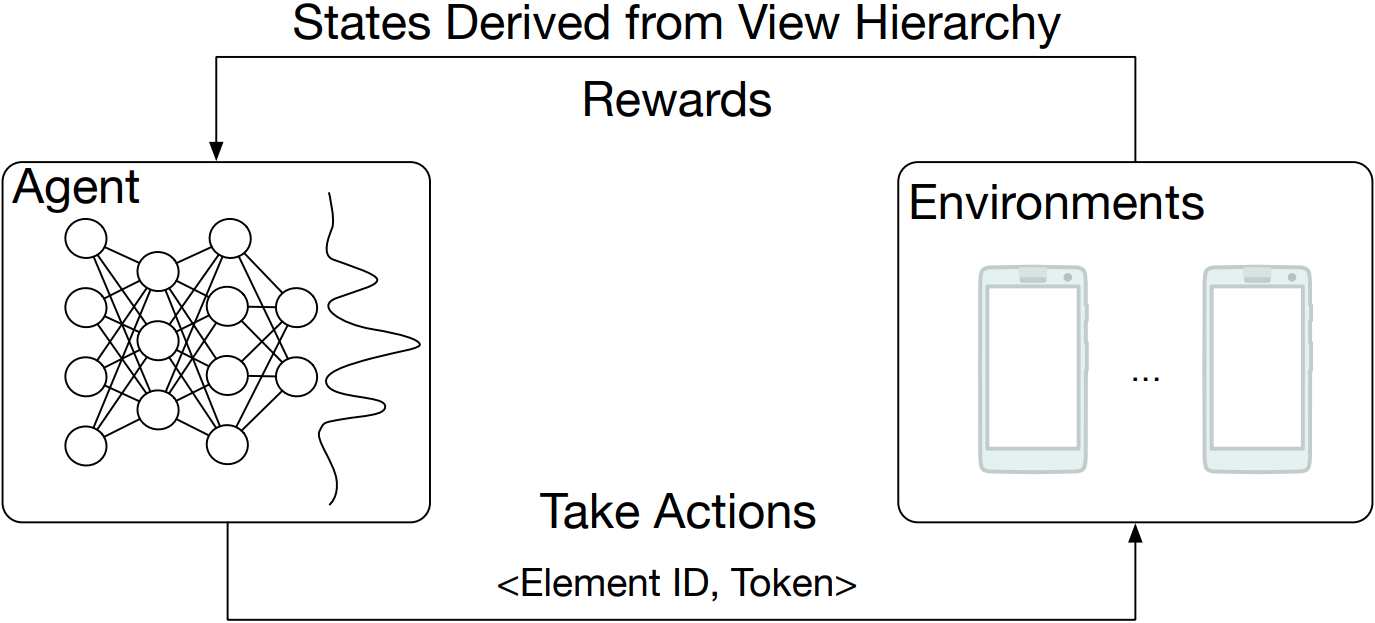 |
Abstract: Human beings, even small children, quickly become adept at figuring out how to use applications on their mobile devices. Learning to use a new app is often achieved via trial-and-error, accelerated by transfer of knowledge from past experiences with like apps. The prospect of building a smarter smartphone - one that can learn how to achieve tasks using mobile apps - is tantalizing. In this paper we explore the use of Reinforcement Learning (RL) with the goal of advancing this aspiration. We introduce an RL-based framework for learning to accomplish tasks in mobile apps. RL agents are provided with states derived from the underlying representation of on-screen elements, and rewards that are based on progress made in the task. Agents can interact with screen elements by tapping or typing. Our experimental results, over a number of mobile apps, show that RL agents can learn to accomplish multi-step tasks, as well as achieve modest generalization across different apps. More generally, we develop a platform which addresses several engineering challenges to enable an effective RL training environment. Our AppBuddy platform is compatible with OpenAI Gym and includes a suite of mobile apps and benchmark tasks that supports a diversity of RL research in the mobile app setting. Link to the paper. |
(ICAPS20) Symbolic Plans as High-Level Instructions for Reinforcement Learning
by L. Illanes, X. Yan, R. Toro Icarte, and S. A. McIlraith.
|
Abstract: Reinforcement learning (RL) agents seek to maximize the cumulative reward obtained when interacting with their environment. Users define tasks or goals for RL agents by designing specialized reward functions such that maximization aligns with task satisfaction. This work explores the use of high-level symbolic action models as a framework for defining final-state goal tasks and automatically producing their corresponding reward functions. We also show how automated planning can be used to synthesize high-level plans that can guide hierarchical RL (HRL) techniques towards efficiently learning adequate policies. We provide a formal characterization of taskable RL environments and describe sufficient conditions that guarantee we can satisfy various notions of optimality (e.g., minimize total cost, maximize probability of reaching the goal). In addition, we do an empirical evaluation that shows that our approach converges to near-optimal solutions faster than standard RL and HRL methods and that it provides an effective framework for transferring learned skills across multiple tasks in a given environment. Link to the paper.
News: This paper won the best paper award at the KR2ML workshop at NeurIPS20 (sponsored by Amazon Science)! [paper].
Preliminary version: (RLDM19) Symbolic Planning and Model-Free Reinforcement Learning: Training Taskable Agents [paper, poster]. |
(NeurIPS19) Learning Reward Machines for Partially Observable Reinforcement Learning
by R. Toro Icarte, E. Waldie, T. Q. Klassen, R. Valenzano, M. P. Castro, and S. A. McIlraith.
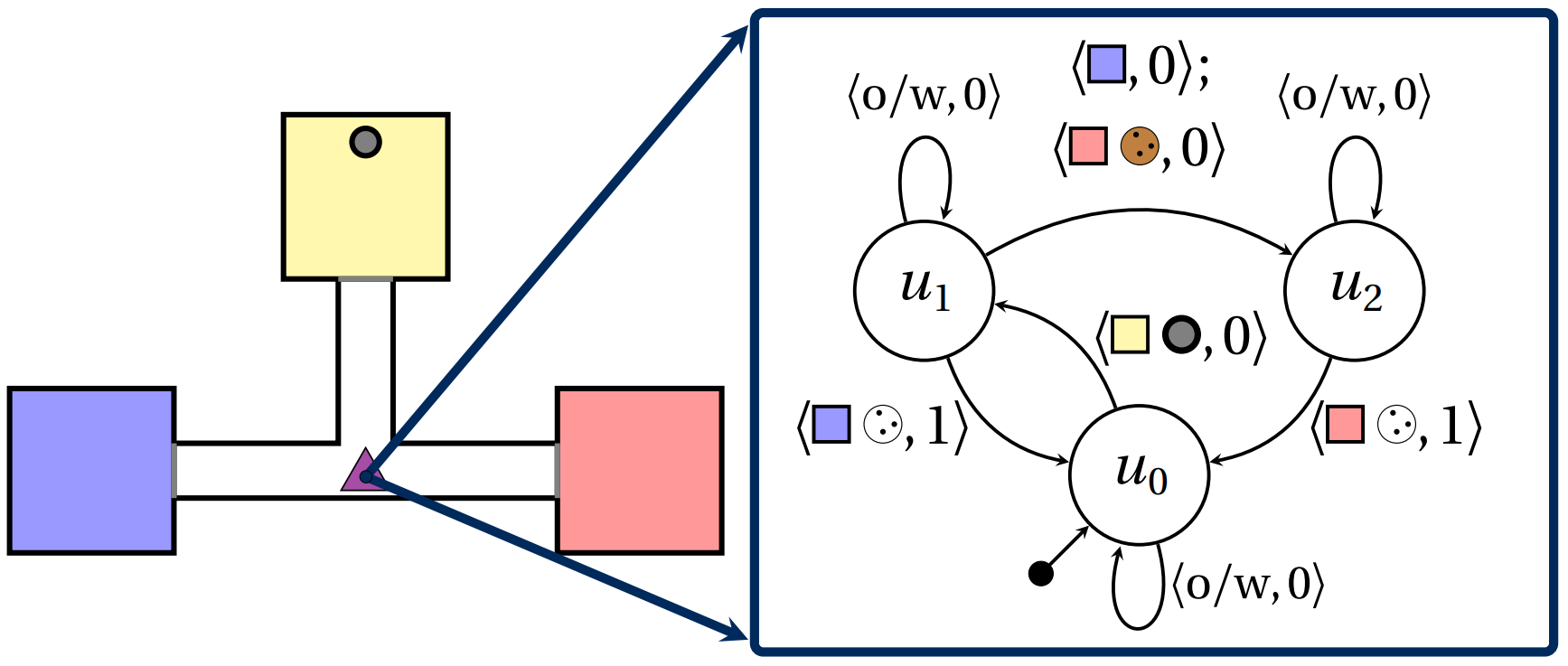 |
Abstract: Reward Machines (RMs), originally proposed for specifying problems in Reinforcement Learning (RL), provide a structured, automata-based representation of a reward function that allows an agent to decompose problems into subproblems that can be efficiently learned using off-policy learning. Here we show that RMs can be learned from experience, instead of being specified by the user, and that the resulting problem decomposition can be used to effectively solve partially observable RL problems. We pose the task of learning RMs as a discrete optimization problem where the objective is to find an RM that decomposes the problem into a set of subproblems such that the combination of their optimal memoryless policies is an optimal policy for the original problem. We show the effectiveness of this approach on three partially observable domains, where it significantly outperforms A3C, PPO, and ACER, and discuss its advantages, limitations, and broader potential. Link to the paper, code, slides, poster, and video.
News 1: Our work has been accepted for spotlight presentation at NeurIPS! Preliminary version: (RLDM19) Searching for Markovian Subproblems to Address Partially Observable Reinforcement Learning [paper, poster]. |
(CP19) Training Binarized Neural Networks using MIP and CP
by R. Toro Icarte, L. Illanes, M. P. Castro, A. Cire, S. A. McIlraith, and J. C. Beck.
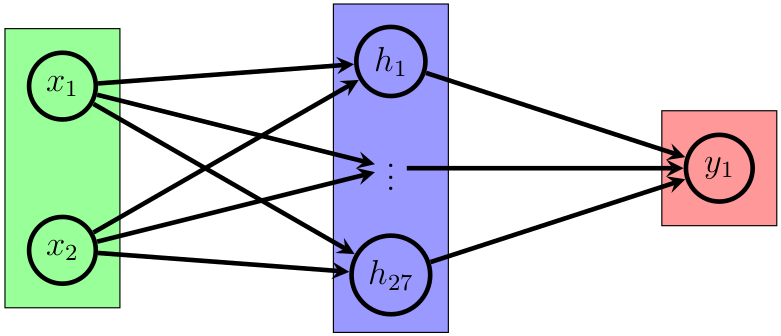 |
Abstract: Binarized Neural Networks (BNNs) are an important class of neural network characterized by weights and activations restricted to the set {-1,+1}. BNNs provide simple compact descriptions and as such have a wide range of applications in low-power devices. In this paper, we investigate a model-based approach to training BNNs using constraint programming (CP), mixed-integer programming (MIP), and CP/MIP hybrids. We formulate the training problem as finding a set of weights that correctly classify the training set instances while optimizing objective functions that have been proposed in the literature as proxies for generalizability. Our experimental results on the MNIST digit recognition dataset suggest that—when training data is limited—the BNNs found by our hybrid approach generalize better than those obtained from a state-of-the-art gradient descent method. More broadly, this work enables the analysis of neural network performance based on the availability of optimal solutions and optimality bounds. |
(IJCAI19) LTL and Beyond: Formal Languages for Reward Function Specification in Reinforcement Learning
by A. Camacho, R. Toro Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith.
 |
Abstract: In Reinforcement Learning (RL), an agent is guided by the rewards it receives from the reward function. Unfortunately, it may take many interactions with the environment to learn from sparse rewards, and it can be challenging to specify reward functions that reflect complex reward-worthy behavior. We propose using reward machines (RMs), which are automata-based representations that expose reward function structure, as a normal form representation for reward functions. We show how specifications of reward in various formal languages, including LTL and other regular languages, can be automatically translated into RMs, easing the burden of complex reward function specification. We then show how the exposed structure of the reward function can be exploited by tailored q-learning algorithms and automated reward shaping techniques in order to improve the sample efficiency of reinforcement learning methods. Experiments show that these RM-tailored techniques significantly outperform state-of-the-art (deep) RL algorithms, solving problems that otherwise cannot reasonably be solved by existing approaches. |
(ICML18) Using Reward Machines for High-Level Task Specification and Decomposition in Reinforcement Learning
by R. Toro Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith.
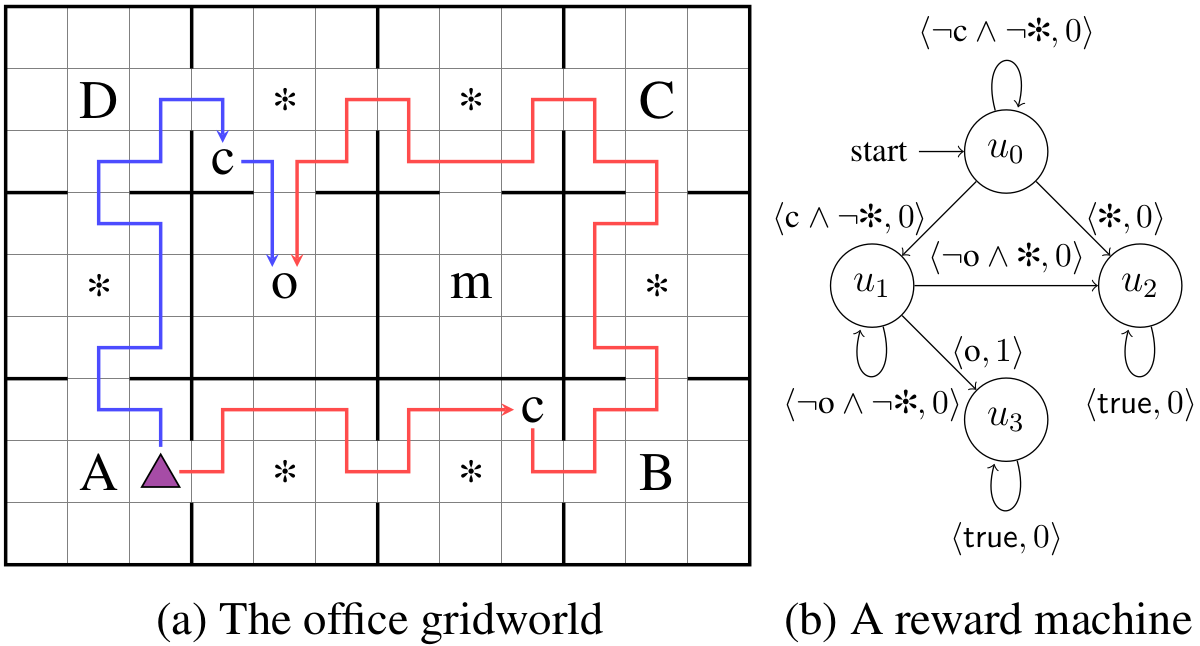 |
Abstract: In this paper we propose Reward Machines—a type of finite state machine that supports the specification of reward functions while exposing reward function structure to the learner and supporting decomposition. We then present Q-Learning for Reward Machines (QRM), an algorithm which appropriately decomposes the reward machine and uses off-policy q-learning to simultaneously learn subpolicies for the different components. QRM is guaranteed to converge to an optimal policy in the tabular case, in contrast to Hierarchical Reinforcement Learning methods which might converge to suboptimal policies. We demonstrate this behavior experimentally in two discrete domains. We also show how function approximation methods like neural networks can be incorporated into QRM, and that doing so can find better policies more quickly than hierarchical methods in a domain with a continuous state space. Link to the paper, slides, poster, bibtex, code, and video. News: We were selected to give a long talk at ICML! |
(AAMAS18) Teaching Multiple Tasks to an RL Agent using LTL
by R. Toro Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith.
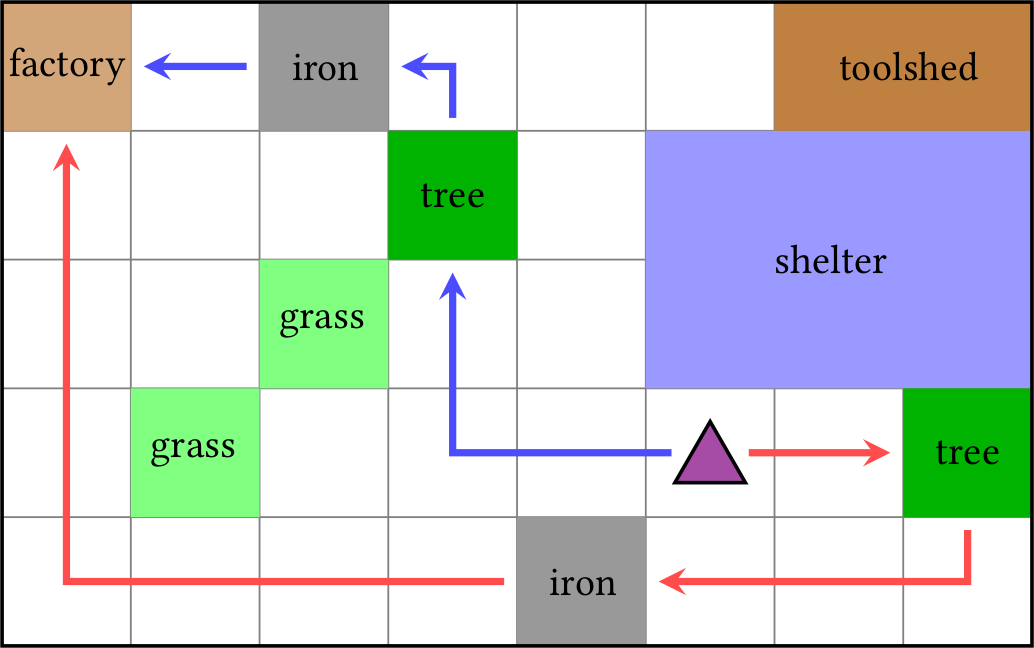 |
Abstract: This paper examines the problem of how to teach multiple tasks to an agent that learns using Reinforcement Learning (RL). To this end, we propose the use of Linear Temporal Logic (LTL) as a compelling language for teaching multiple tasks to an RL agent in a manner that supports composition of learned skills. We also propose a novel algorithm that exploits LTL progression and off-policy RL to speed up learning without compromising convergence guarantees. Experiments over randomly generated Minecraft-like grids illustrate our superior performance relative to the state of the art. Link to the paper, slides, poster, bibtex, and code. News: I presented this work at the learning by instruction workshop at NeurIPS 2018 [slides]. |
(CCAI18) Advice-Based Exploration in Model-Based Reinforcement Learning
by R. Toro Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith.
|
Abstract: A reason that current machine learning approaches still fall short of human performance in many areas may lie in the way problems are defined for them. When people try to reach their goals, they often are not limited to figuring out what to do based only on observing the environment, but can also make use of other things, like linguistically expressed advice from other people. We believe that human advice can also benefit artificial agents, and can play a major role in enabling them to solve harder problems. Method: In this project, we look for ways to use advice when solving MDPs. The advice language includes temporal operators that allow us to recommend, for instance, to "get the key and then go to the door", "collect all the cookies", or "avoid nails and holes". We have experimented using Model-Free and Model-Based Reinforcement Learning. In the video, the agent (green dot) is able to escape from a maze by learning from experience and human advice. To escape from the maze, the agent has to collect the keys (yellow dots) to open the doors (brown square), while avoiding nails (gray dots) and holes (blue dots) and, hopefully, collecting cookies (brown dots). Preliminary version: (RLDM17) Using Advice in Model-Based Reinforcement Learning [paper, poster]. |
(IJCAI17) How a General-Purpose Commonsense Ontology can Improve Performance of Learning-Based Image Retrieval
by R. Toro Icarte, J. Baier, C. Ruz, and A. Soto.
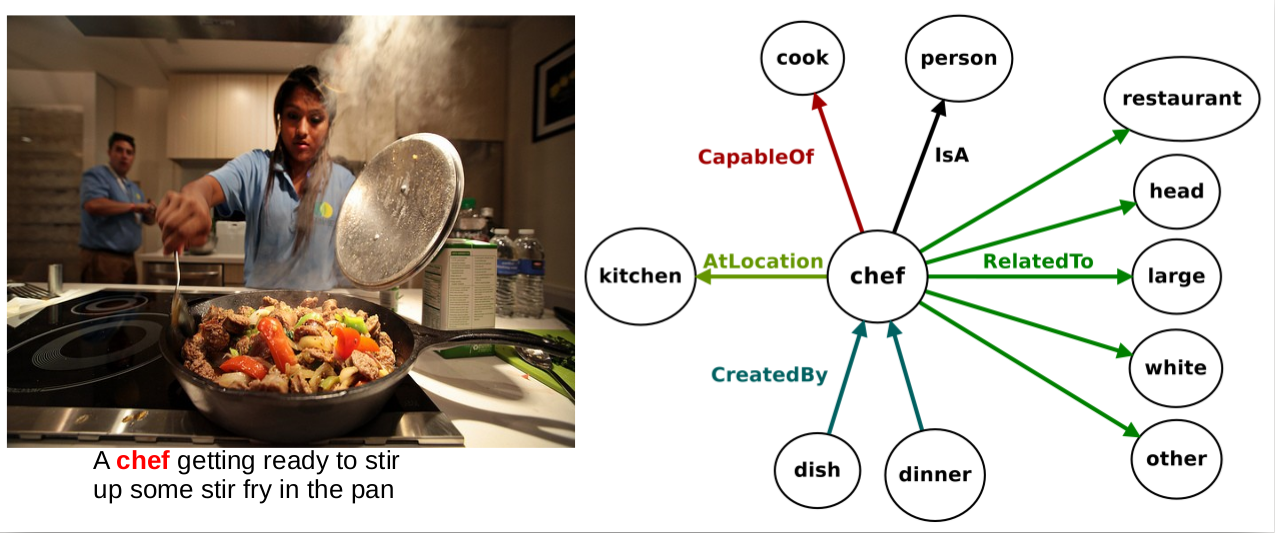 |
Abstract: The knowledge representation community has invested great efforts in building general-purpose ontologies which contain large amounts of commonsense knowledge on various aspects of the world. Among the thousands of assertions contained in them, many express relations that can be regarded as relevant to visual inference; e.g., "a ball is used by a football player", "a tennis player is located at a tennis court". In general, current state-of-the-art approaches for visual recognition do not exploit these rule-based knowledge sources. In this project, we study the question of whether or not general-purpose ontologies—specifically, MIT’s ConceptNet ontology—could play a role in state-of-the-art vision systems. |