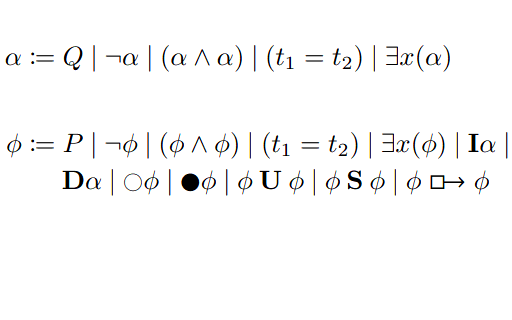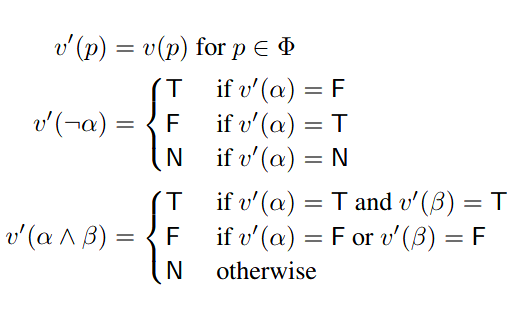Remembering to Be Fair: Non-Markovian Fairness in Sequential Decision Making
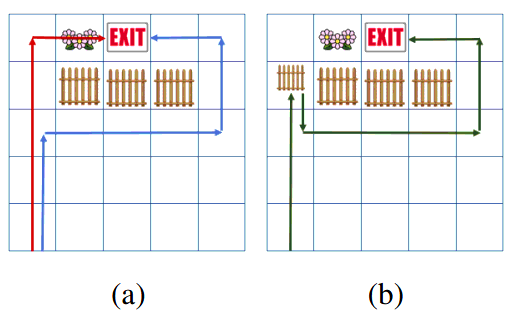
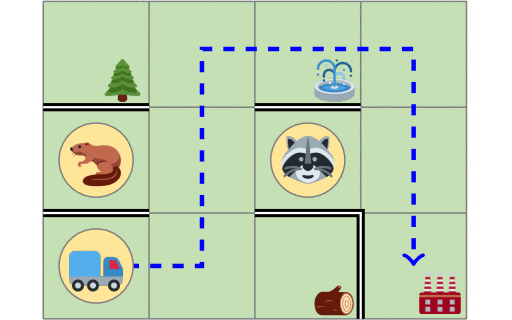
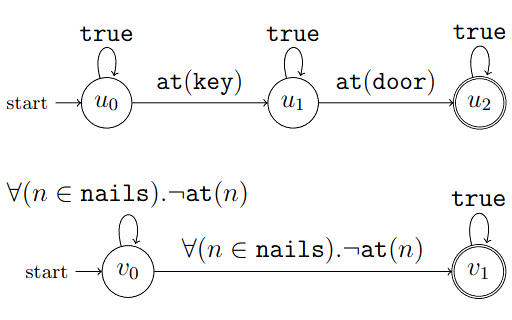
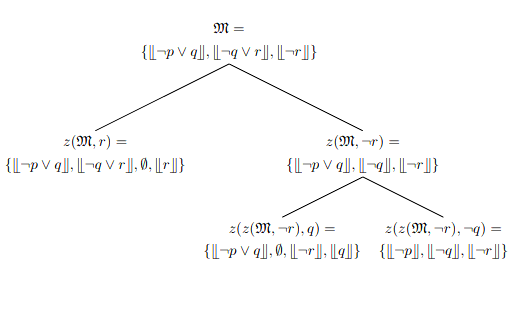
We introduce ways of evaluating fairness over time, and also the FairQCM algorithm, which can automatically augment its training data to improve sample efficiency in the synthesis of fair policies via reinforcement learning. Parand A. Alamdari, Toryn Q. Klassen, Elliot Creager, and Sheila A. McIlraith ICML 2024
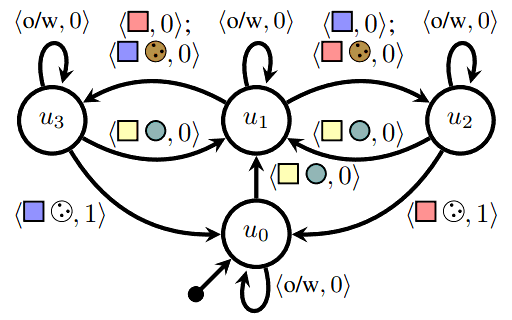
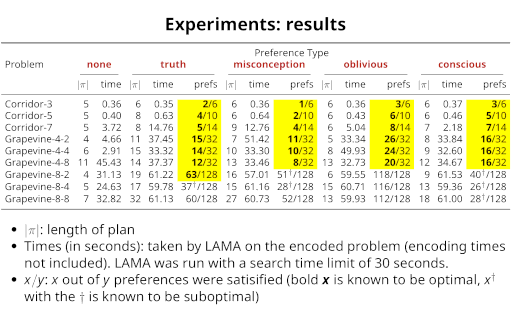
We investigate automated planning with epistemic preferences, i.e., soft goals over the knowledge or beliefs of agents. Toryn Q. Klassen, Christian Muise, and Sheila A. McIlraith KR 2023
We introduce the notion of epistemic side effects, potentially undesirable changes made to knowledge or beliefs by an AI system in pursuit of an underspecified objective, and describe a way to sometimes avoid them in reinforcement learning. Toryn Q. Klassen, Parand A. Alamdari, and Sheila A. McIlraith AAMAS 2023 (Blue Sky Ideas Track)
Resolving Misconceptions about the Plans of Agents via Theory of Mind
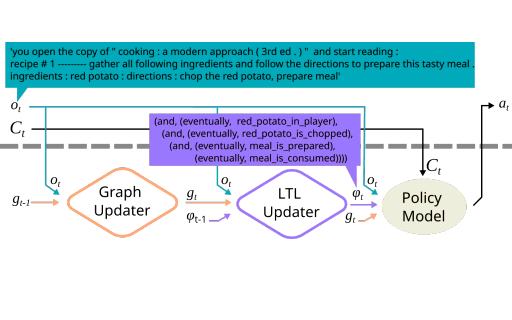
We explore using epistemic planning to resolve discrepancies between agents' beliefs about the validity of plans Maayan Shvo, Toryn Q. Klassen, and Sheila A. McIlraith ICAPS 2022
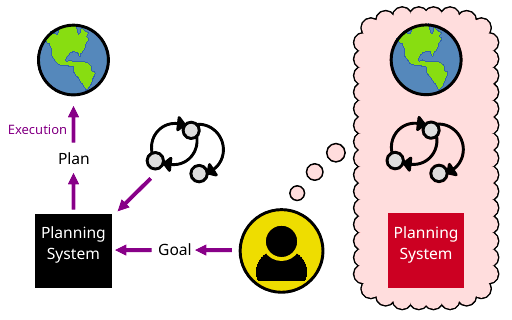
In this position paper, we consider the threat in symbolic planning of plans having undesirable side effects as result of being found for underspecified objectives. We discuss how the risk may be amplified by the use of learned planning models, but also how the learned models may provide features that help ameliorate the risk. Toryn Q. Klassen, Sheila A. McIlraith, and Christian Muise ICAPS 2022 Workshop on Reliable Data-Driven Planning and Scheduling
AI systems may cause negative side effects because their given objectives don't capture everything that they should not do. We consider how to avoid side effects in the context of symbolic planning, including by finding plans that don't interfere with possible goals or plans of other agents. Toryn Q. Klassen, Sheila A. McIlraith, Christian Muise, and Jarvis Xu AAAI 2022
Reward Machines: Exploiting Reward Function Structure in Reinforcement Learning
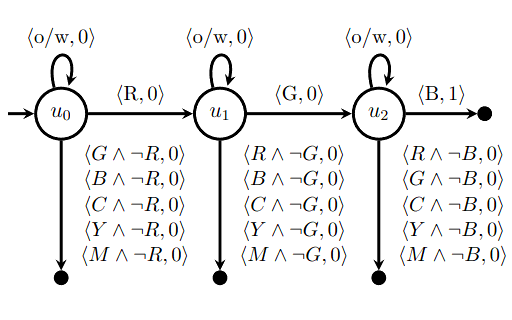
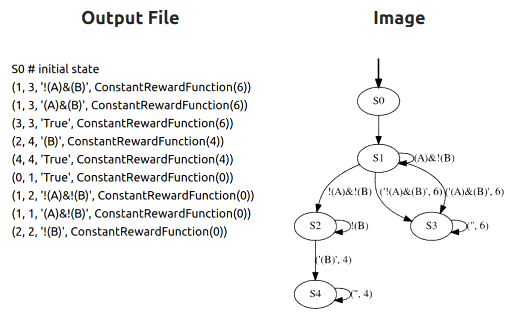
This is the expanded version of our ICML 2018 paper that introduced reward machines, which give structured representations of reward functions. This paper uses a slightly different definition and introduces the CRM algorithm, a simpler variant of the QRM algorithm from the original paper. Rodrigo Toro Icarte, Toryn Q. Klassen, Richard Valenzano, and Sheila A. McIlraith JAIR, Volume 73, 2022
Representing Plausible Beliefs about States, Actions, and Processes
This thesis deals with the topic of modelling an agent’s beliefs about a dynamic world in a way that allows for changes in beliefs, including retracting of beliefs. It elaborates on work from the KR 2018 and KR 2020 papers below, and also covers knowing how to achieve goals in the presence of environmental processes. Toryn Q. Klassen PhD thesis, University of Toronto, 2021
In the task of plan recognition, an observer infers the plan and goal of an actor. We introduce the notion of epistemic plan recognition, which uses epistemic logic to model the observer in a plan recognition setting, represent agent beliefs, and allow for the recognition of epistemic goals. Maayan Shvo, Toryn Q. Klassen, Shirin Sohrabi, and Sheila A. McIlraith AAMAS 2020
LTL and Beyond: Formal Languages for Reward Function Specification in Reinforcement Learning
This paper describes how to convert specifications of reward functions written in LTL and other formal languages into reward machines, and how to apply automated reward-shaping to reward machines. Alberto Camacho, Rodrigo Toro Icarte, Toryn Q. Klassen, Richard Valenzano, and Sheila A. McIlraith IJCAI 2019
Specifying Plausibility Levels for Iterated Belief Change in the Situation Calculus
This paper describes a qualitative model of plausibility based on counting the extensions of certain predicates. Toryn Q. Klassen, Sheila A. McIlraith, and Hector J. Levesque KR 2018
Using Reward Machines for High-Level Task Specification and Decomposition in Reinforcement Learning
We introduce reward machines -- a form of automaton that gives a structured description of a reward function. This structure can be exploited by reinforcement learning algorithms to learn faster (analogously to how the structure of formulas was used in the AAMAS 2018 paper below). Rodrigo Toro Icarte, Toryn Q. Klassen, Richard Valenzano, and Sheila A. McIlraith ICML 2018
Advice-Based Exploration in Model-Based Reinforcement Learning
Linear temporal logic (LTL) formulas and a heuristic are used to guide exploration during reinforcement learning. Note that the slides have embedded videos that may not play on some systems. Rodrigo Toro Icarte, Toryn Q. Klassen, Richard Valenzano, and Sheila A. McIlraith Canadian AI 2018
Towards Representing What Readers of Fiction Believe
We use a temporal modal logic to describe a reader's beliefs about the reading process. We also discuss some ideas on how to model how a reader "carries over" real-world knowledge into fictional stories. Toryn Q. Klassen, Hector J. Levesque, and Sheila A. McIlraith Commonsense 2017
Towards Tractable Inference for Resource-Bounded Agents
This paper, written during my master's program, considers a formal model of belief that was meant to avoid attributing unlimited reasoning power to agents. Toryn Q. Klassen, Sheila A. McIlraith, and Hector J. Levesque Commonsense 2015
This theory paper about properties of hash functions resulted from my undergraduate research in theoretical computer science. Toryn Q. Klassen and Philipp Woelfel LATIN 2012