Publications
Journal Articles
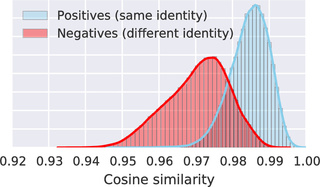
Video Face Clustering with Self-Supervised Representation Learning
Vivek Sharma, Makarand Tapaswi, M. Saquib Sarfraz and Rainer Stiefelhagen
IEEE Transactions on Biometrics
(T-BIOM
vol. 2 (2), pp. 145-157),
2020.
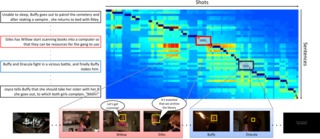
Aligning Plot Synopses to Videos for Story-based Retrieval
Makarand Tapaswi, Martin Bäuml and Rainer Stiefelhagen
International Journal of Multimedia Information Retrieval
(IJMIR
vol. 4 (1), pp. 3-16),
2015.
Conference Proceedings
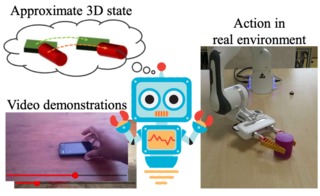
Learning Object Manipulation Skills via Approximate State Estimation from Real Videos
Vladimir Petrik*, Makarand Tapaswi*, Ivan Laptev and Josef Sivic
Conference on Robot Learning
(CoRL
Poster, Acceptance rate=34%),
Virtual,
Nov 2020.
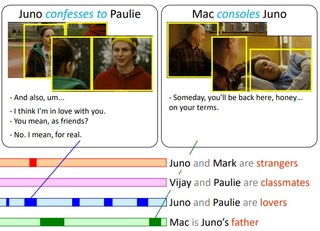
Learning Interactions and Relationships between Movie Characters
Anna Kukleva, Makarand Tapaswi and Ivan Laptev
Conference on Computer Vision and Pattern Recognition
(CVPR
Oral, Acceptance rate=5.0%),
Virtual,
Jun 2020.
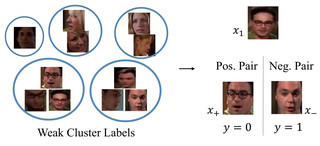
Clustering based Contrastive Learning for Improving Face Representations
Vivek Sharma, Makarand Tapaswi, Saquib Sarfraz and Rainer Stiefelhagen
IEEE International Conference on Automatic Face and Gesture Recognition
(FG
Poster, Acceptance rate=44.0%),
Buenos Aires, Argentina,
May 2020.
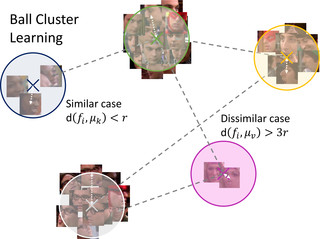
Video Face Clustering with Unknown Number of Clusters
Makarand Tapaswi, Marc T. Law and Sanja Fidler
International Conference on Computer Vision
(ICCV
Poster, Acceptance rate=25.0%),
Seoul, Korea,
Oct 2019.

HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev and Josef Sivic
International Conference on Computer Vision
(ICCV
Poster, Acceptance rate=25.0%),
Seoul, Korea,
Oct 2019.
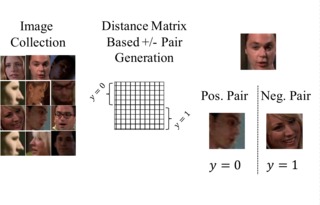
Self-Supervised Learning of Face Representations for Video Face Clustering
Vivek Sharma, Makarand Tapaswi, Saquib Sarfraz and Rainer Stiefelhagen
IEEE International Conference on Automatic Face and Gesture Recognition
(FG
Oral, Acceptance rate=20.1%),
Best Paper Award
Lille, France,
May 2019.
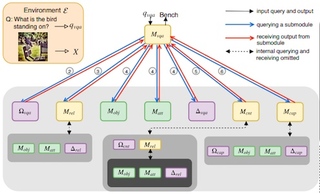
Visual Reasoning by Progressive Module Networks
Seung Wook Kim, Makarand Tapaswi and Sanja Fidler
International Conference on Learning Representations
(ICLR
Poster, Acceptance rate=32.9%),
New Orleans, LA, USA,
May 2019.
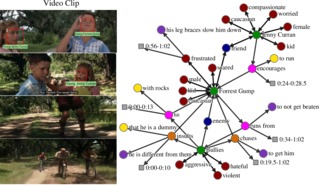
MovieGraphs: Towards Understanding Human-Centric Situations from Videos
Paul Vicol, Makarand Tapaswi, Lluis Castrejon and Sanja Fidler
Conference on Computer Vision and Pattern Recognition
(CVPR
Spotlight, Acceptance rate=8.7%),
Salt Lake City, UT, USA,
Jun. 2018.
PDF Project DOI arXiv spotlight suppl. material

Now You Shake Me: Towards Automatic 4D Cinema
Yuhao Zhou, Makarand Tapaswi and Sanja Fidler
Conference on Computer Vision and Pattern Recognition
(CVPR
Spotlight, Acceptance rate=8.7%),
Salt Lake City, UT, USA,
Jun. 2018.
PDF Project DOI spotlight suppl. material
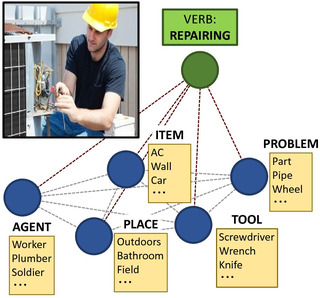
Situation Recognition with Graph Neural Networks
Ruiyu Li, Makarand Tapaswi, Renjie Liao, Jiaya Jia, Raquel Urtasun and Sanja Fidler
International Conference on Computer Vision
(ICCV
Poster, Acceptance rate=28.9%),
Venice, Italy,
Oct. 2017.
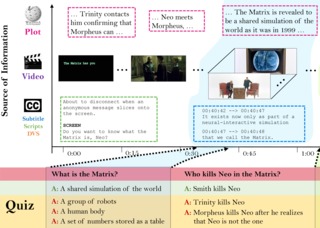
MovieQA: Understanding Stories in Movies through Question-Answering
Makarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun and Sanja Fidler
Conference on Computer Vision and Pattern Recognition
(CVPR
Spotlight, Acceptance rate=9.7%),
Las Vegas, NV, USA,
Jun. 2016.
PDF Project DOI arXiv code spotlight presentation poster-1 poster-2
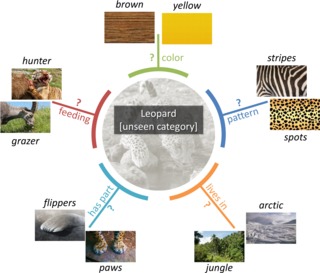
Recovering the Missing Link: Predicting Class-Attribute Associations for Unsupervised Zero-Shot Learning
Ziad Al-Halah, Makarand Tapaswi and Rainer Stiefelhagen
Conference on Computer Vision and Pattern Recognition
(CVPR
Poster, Acceptance rate=29.9%),
Las Vegas, NV, USA,
Jun. 2016.

Naming TV Characters by Watching and Analyzing Dialogs
Monica-Laura Haurilet, Makarand Tapaswi, Ziad Al-Halah and Rainer Stiefelhagen
Winter Conference on Applications of Computer Vision
(WACV
Acceptance rate=42.3%),
Lake Placid, NY, USA,
Mar. 2016.

Accio: A Data Set for Face Track Retrieval in Movies Across Age
Esam Ghaleb, Makarand Tapaswi, Ziad Al-Halah, Hazım Kemal Ekenel and Rainer Stiefelhagen
International Conference on Multimedia Retrieval
(ICMR
Short paper, Poster, Acceptance rate=40.5%),
Shanghai, China,
Jun. 2015.
PDF DOI poster face tracks features (9GB+)
Book2Movie: Aligning Video scenes with Book chapters
Makarand Tapaswi, Martin Bäuml and Rainer Stiefelhagen
Conference on Computer Vision and Pattern Recognition
(CVPR
Poster, Acceptance rate=28.4%),
Boston, MA, USA,
Jun. 2015.
PDF Project DOI data set ext. abstract poster-1 poster-2 suppl. material
Improved Weak Labels using Contextual Cues for Person Identification in Videos
Makarand Tapaswi, Martin Bäuml and Rainer Stiefelhagen
International Conference on Automatic Face and Gesture Recognition
(FG
Poster, Acceptance rate=38.0%),
Ljubljana, Slovenia,
May 2015.
Total Cluster: A person agnostic clustering method for broadcast videos
Makarand Tapaswi, Omkar M. Parkhi, Esa Rahtu, Eric Sommerlade, Rainer Stiefelhagen and Andrew Zisserman
Indian Conference on Computer Vision, Graphics and Image Processing
(ICVGIP
Oral, Acceptance rate=9.4%),
Bangalore, India,
Dec. 2014.

Cleaning up after a Face Tracker: False Positive Removal
Makarand Tapaswi, Cemal Çağrı Çörez, Martin Bäuml, Hazım Kemal Ekenel and Rainer Stiefelhagen
International Conference on Image Processing
(ICIP
Poster, Acceptance rate=43.2%),
Paris, France,
Oct. 2014.
A Time Pooled Track Kernel for Person Identification
Martin Bäuml, Makarand Tapaswi and Rainer Stiefelhagen
Conference on Advanced Video and Signal-based Surveillance
(AVSS
Oral, Acceptance rate=22.5%),
Seoul, Korea,
Aug. 2014.
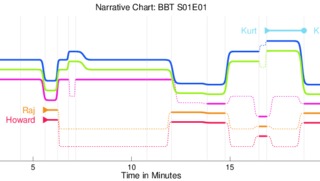
StoryGraphs: Visualizing Character Interactions as a Timeline
Makarand Tapaswi, Martin Bäuml and Rainer Stiefelhagen
Conference on Computer Vision and Pattern Recognition
(CVPR
Poster, Acceptance rate=29.9%),
Columbus, OH, USA,
Jun. 2014.
PDF Project DOI code poster-1 poster-2 suppl. material

Story-based Video Retrieval in TV series using Plot Synopses
Makarand Tapaswi, Martin Bäuml and Rainer Stiefelhagen
International Conference on Multimedia Retrieval
(ICMR
Oral Full paper, Acceptance rate=19.1%),
Glasgow, Scotland,
Apr. 2014.
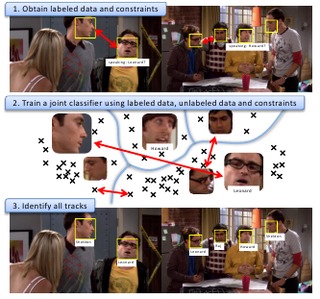
Semi-supervised Learning with Constraints for Person Identification in Multimedia Data
Martin Bäuml, Makarand Tapaswi and Rainer Stiefelhagen
Conference on Computer Vision and Pattern Recognition
(CVPR
Poster, Acceptance rate=25.2%),
Portland, OR, USA,
Jun. 2013.
PDF Project DOI poster-1 poster-2
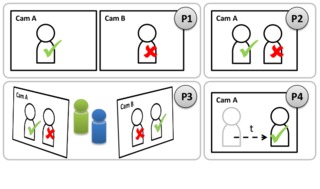
Contextual Constraints for Person Retrieval in Camera Networks
Martin Bäuml, Makarand Tapaswi, Arne Schumann and Rainer Stiefelhagen
Conference on Advanced Video and Signal-based Surveillance
(AVSS
Oral, Acceptance rate=17.8%),
Beijing, China,
Sep. 2012.
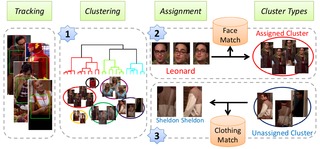
``Knock! Knock! Who is it?'' Probabilistic Person Identification in TV series
Makarand Tapaswi, Martin Bäuml and Rainer Stiefelhagen
Conference on Computer Vision and Pattern Recognition
(CVPR
Poster, Acceptance rate=24.0%),
Providence, RI, USA,
Jun. 2012.
PDF Project DOI poster-1 poster-2 suppl. material
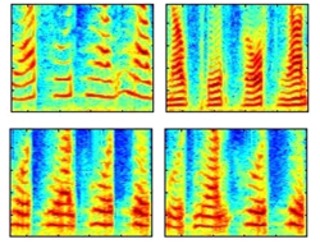
Direct modeling of spoken passwords for text-dependent speaker recognition by compressed time-feature representations
Amitava Das and Makarand Tapaswi
International Conference on Acoustics, Speech, and Signal Processing
(ICASSP
Poster),
Dallas, TX, USA,
Mar. 2010.
Workshops
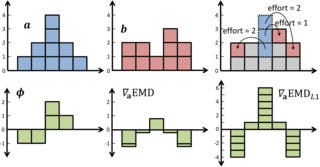
A Closed-form Gradient for the 1D Earth Mover's Distance for Spectral Deep Learning on Biological Data
Manuel Martinez, Makarand Tapaswi, Rainer Stiefelhagen
ICML 2016 Workshop on Computational Biology
(CompBio@ICML16
),
New York, NY, USA,
Jun. 2016.
KIT at MediaEval 2015 -- Evaluating Visual Cues for Affective Impact of Movies Task
Marin Vlastelica Pogančić, Sergey Hayrapetyan, Makarand Tapaswi, Rainer Stiefelhagen
Proceedings of the MediaEval2015 Multimedia Benchmark Workshop
(MediaEval2015
),
Wurzen, Germany,
Sep. 2015.
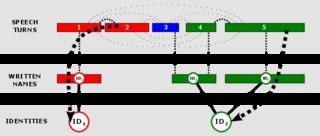
QCompere @ Repere 2013
Hervé Bredin, Johann Poignant, Guillaume Fortier, Makarand Tapaswi, Viet Bac Le, Anindya Roy, Claude Barras, Sophie Rosset, Achintya Sarkar, Hua Gao, Alexis Mignon, Jakob Verbeek, Laurent Besacier, Georges Quénot, Hazım Kemal Ekenel, Rainer Stiefelhagen
Workshop on Speech, Language and Audio in Multimedia
(SLAM
Oral),
Marseille, France,
Aug. 2013.
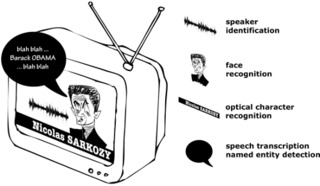
Fusion of Speech, Faces and Text for Person Identification in TV Broadcast
Hervé Bredin, Johann Poignant, Makarand Tapaswi, Guillaume Fortier, Viet Bac Le, Thibault Napoleon, Hua Gao, Claude Barras, Sophie Rosset, Laurent Besacier, Jakob Verbeek, Georges Quénot, Frédéric Jurie, Hazım Kemal Ekenel
Workshop on Information Fusion in Computer Vision for Concept Recognition (held with ECCV 2012)
(IFCVCR
Poster),
Florence, Italy,
Oct. 2012.
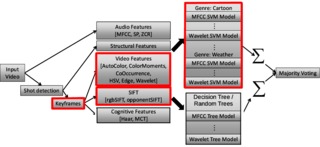
KIT at MediaEval2012 - Content-based Genre Classification with Visual Cues
Tomas Semela, Makarand Tapaswi, Hazım Kemal Ekenel, Rainer Stiefelhagen
Proceedings of the MediaEval2012 Multimedia Benchmark Workshop
(MediaEval2012
),
Pisa, Italy,
Oct. 2012.
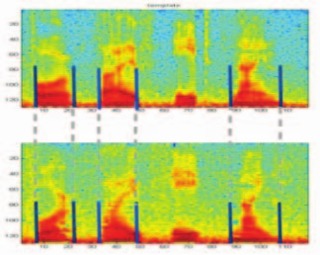
Multilingual spoken-password based user authentication in emerging economies using cellular phone networks
Amitava Das, Ohil K. Manyam, Makarand Tapaswi and Veeresh Taranalli
Workshop on Spoken Language Technology
(SLT
Oral),
Goa, India,
Dec. 2008.
Disclaimer
This publication material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.