|
Yuhao Zhou,
Makarand Tapaswi,
Sanja Fidler, We are interested in enabling automatic 4D cinema by parsing physical and special effects from untrimmed movies. These include effects such as physical interactions, water splashing, light, and shaking, and are grounded to either a character in the scene or the camera. We collect a new dataset referred to as the Movie4D dataset which annotates over 9K effects in 63 movies. We propose a Conditional Random Field model atop a neural network that brings together visual and audio information, as well as semantics in the form of person tracks. Our model further exploits correlations of effects between different characters in the clip as well as across movie threads. We propose effect detection and classification as two tasks, and present results along with ablation studies on our dataset, paving the way towards 4D cinema in everyone's homes. |
|

|

|
|
|
|
Paper |
|
|
Citation: |

|
Qualitative Result Demo |
|
|
Here is one example clip taken from the movie Thor II: The Dark World.
GT is the label made by human annotators; U is the prediction made by neural network; CRF is the result from Conditional Random Field. |
|
|
Here is another clip taken from the movie Iron Man III. This clip doesn't contain scenes that do not have as many effects as in the previous example. And we can still see that the model can properly ignore the parts where human don't perceive as a strong effect. |
|
|
|
|
Method |
|
|
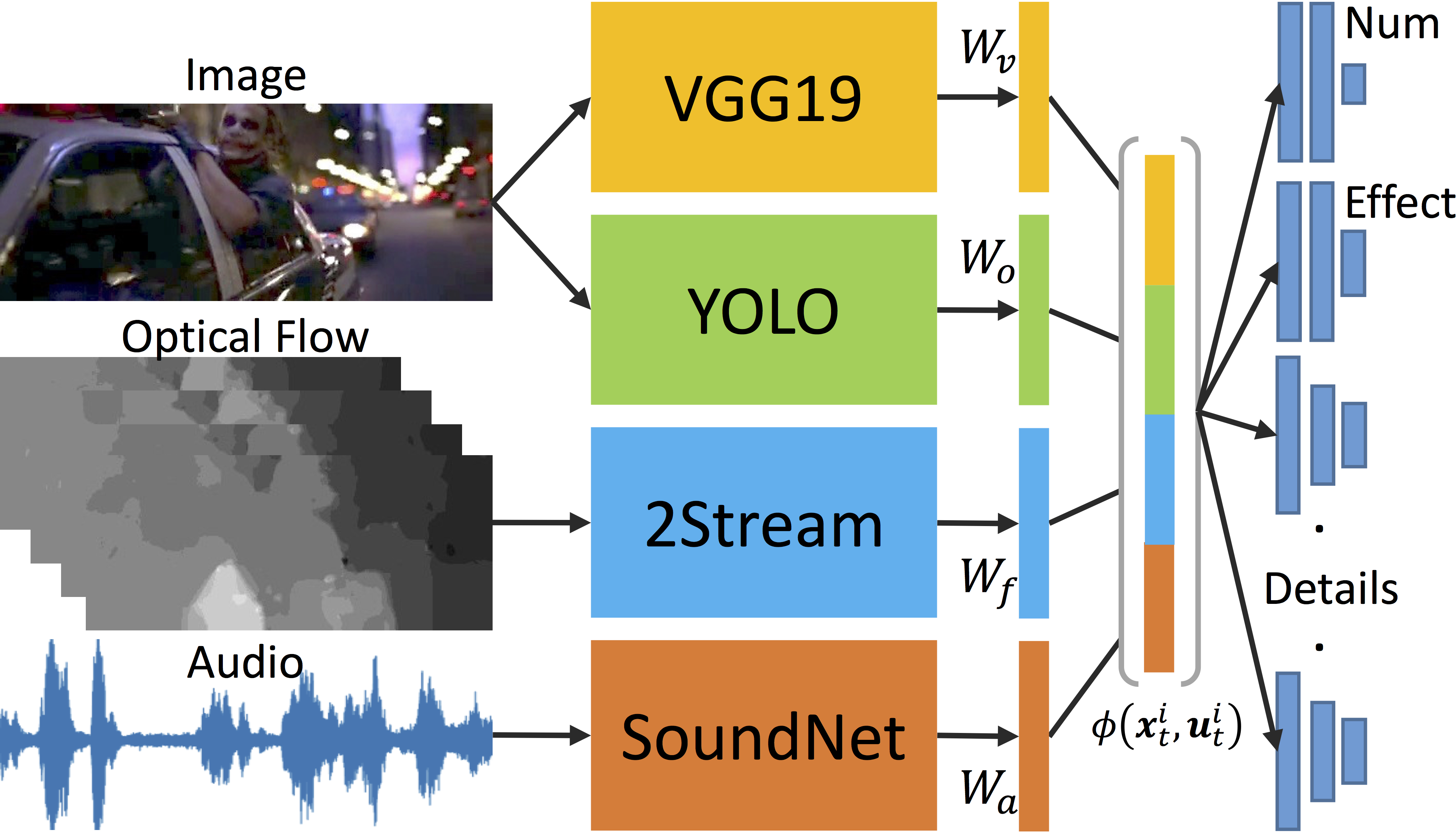
We proposed a 4-stream neural architecture for obtaining the unaries, and a Condition Random Field to exploit the relationship between shots. The model to the right is our neural architecture for obtaining all the unaires. It combines visual information (image, optical flow, and object detection) and acoustic information (audio) to make the prediction. The figure below shows how the condition random field combine different shots and person tracking to improve the result on top of the neural network. |
|
|
|
|
|
|
Acknowledgement |
|
|
The research is supported by NSERC. We thank NVIDIA for GPU donation. We thank Relu Patrascu for infrastructure support, and UpWork annotators for data annotation. |
|
|
Credits: University of Toronto: Yuhao Zhou, Makarand Tapaswi, Sanja Fidler |
|