Introduction:
Many collections of data exhibit a common underlying structure: they consist of a number of parts or factors, each with a range of possible states. When data are represented as vectors, parts manifest themselves as subsets of the data dimensions that take on values in a coordinated fashion.
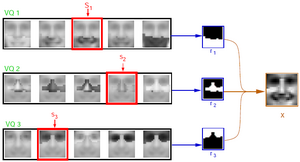
In this project, we propose a form of probabilistic model for simultaneously learning both the parts and the states (or range of apperances) of each part. We provide details for two of these models: Multiple Cause Vector Quantization (MCVQ, pictured on the right) learns a discrete model of states, and Multiple Cause Factor Analysis (MCFA) learns a continuous model.
These models can be applied to learning the parts of objects (such as faces) in images, and collaborative filtering of movie ratings. For an introduction to MCVQ and MCFA, please see our JMLR article linked below.
Papers:
- Learning Parts-Based Representations of Data
David Ross and Richard Zemel. Journal of Machine Learning Research, 7(Nov):2369-2397, 2006. [PDF] - Multiple Cause Vector Quantization
David Ross and Richard Zemel
In S. Becker, S. Thrun, and K. Obermayer, editors, Advances in Neural Information Processing Systems 15, MIT Press, 2003. [PS.GZ] [PDF]
- Learning Parts-Based Representations of Data
David Ross, University of Toronto, M.Sc. Thesis, 2003. [PS.GZ] [PDF]
Code:
- MCVQ and MCFA code, written in Matlab, is available here. mcvq_mcfa_2006-11-09.zip
- Parallel MCVQ: I've written a version of MCVQ that can be distributed across multiple CPUs, via MPI. In addition to speeding it up, this allows you to run MCVQ on larger (possibly sparse) datasets that wouldn't otherwise fit in memory. Code can be found here: mcvq_mpi.m. It also requires a modified version of MatlabMPI.
- If you're looking for any other MCVQ/MCFA code (for example, code for an experiment in one of the papers) and it doesn't seem to be available above, please email me.
Presentations:
- NIPS-2002 Poster
This is the poster corresponding to the above paper. Unfortunately the notation is a little bit different, but the translation should be easy enough. Poster: [PS.GZ] [PDF] References: [PS.GZ] [PDF] - ML Group Meeting Talk
This is a talk I gave on October 22, 2002, at the Machine Learning group meeting. It covers the basics of the model, as presented in the NIPS paper, as well as extensions and elaborations that Rich and I were investigating (circa 2002). [PS.GZ] [PDF] - IRIS Poster & Abstract
The very first description of MCVQ was given at the 2002 Precarn IRIS conference in Calgary. (It was also the first piece of research I ever produced.) Here you can find the abstract [PS.GZ] [PDF] and the poster [PS.GZ] [PDF]
Performance Results:
- Results
These are the results of a series of cross-validation experiments that I performed, to analyze how the reconstruction performance of MCVQ varies, depending on the number of vector quantizers, and the number of vectors per VQ. (This is very old.)