
|
|
|
|
|
ShapeMatcher 5 |
||||||||||
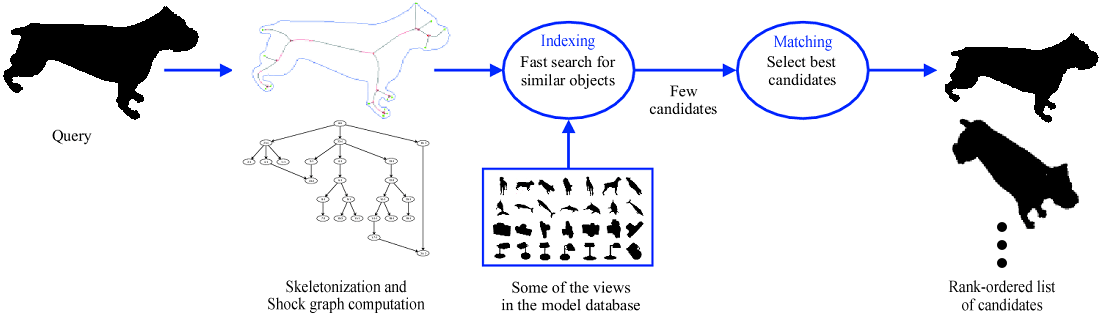
A Shape Indexer and Matcher for Object RecognitionShapeMatcher 5 is a console application for experimenting with shape matching using skeletons. It computes skeletons and shock graphs from segmented image regions and stores them in a shape database that can be later used for efficient indexing and matching operations.
Multiples databases can be created at different levels of details (by varying parameter values) and used for shape classification. ShapeMatcher 5 produces both text and graphical outputs. In future releases, it will also produce a more consistent XML output for all the operations, such as computing skeletons, matching shapes, and many others that you can discover with a bit of patience. The focus of the current implementation of ShapeMacther has been on correctness rather than speed. Close to real-time performance can be achieved in a commercial implementation. DownloadBinariesShapeMatcher 6.0.1 for Windows [May 14, 2008] Source CodeThe ShapeMatcher code is written in C++. All but one of the external libraries required to compile the code are included in the zip file below. The missing library is LEDA, which is a commercial library with good implementations of graph data structures. It is also possible to get a free version of LEDA 6.0, which does not inlcude all the necessary graph algorithms to compile the code. It should however be possible to add the missing algorithms (with some effort). ShapeMatcher 7.1.1 source code for both Linux (gcc) and Windows (Visual C++) [file uploaded on June 1, 2010] Test Images
Step-By-Step TutorialHere is a quick tutorial on how to use the basic features of ShapeMatcher 5. DocumentationShapeMatcher 5 is a command-line program with a large number of parameters and functions. A brief help file and the list of available commands can be found here and some extra comments here. Useful commands and screenshots with their outputc: create database from a directory with ppm files.
a: add new shapes to an existing database.
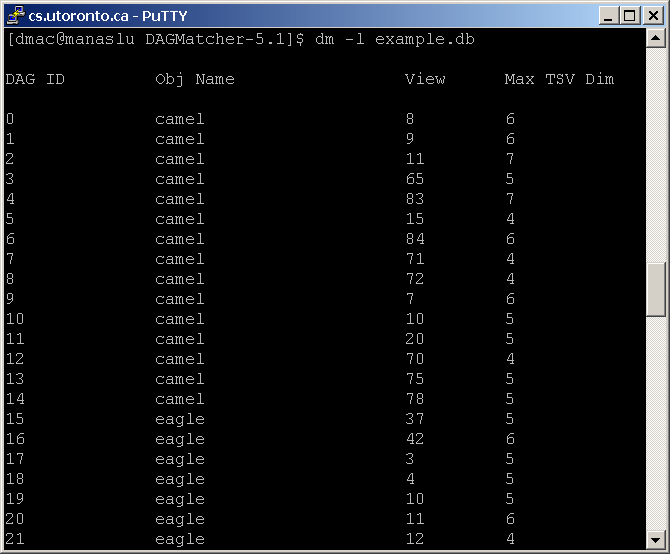
l: list the shapes in the database.
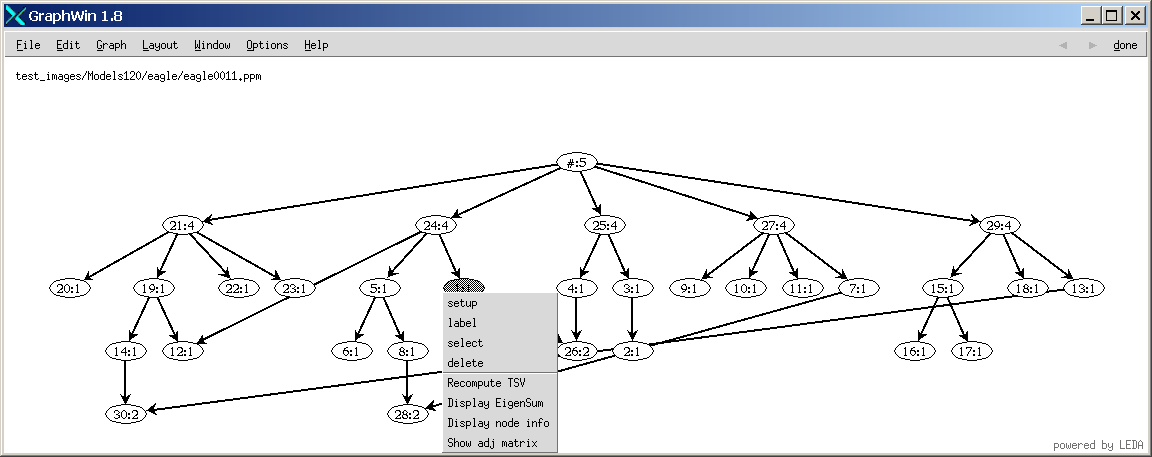
v: view the skeleton and shock graph of a shape in the database.
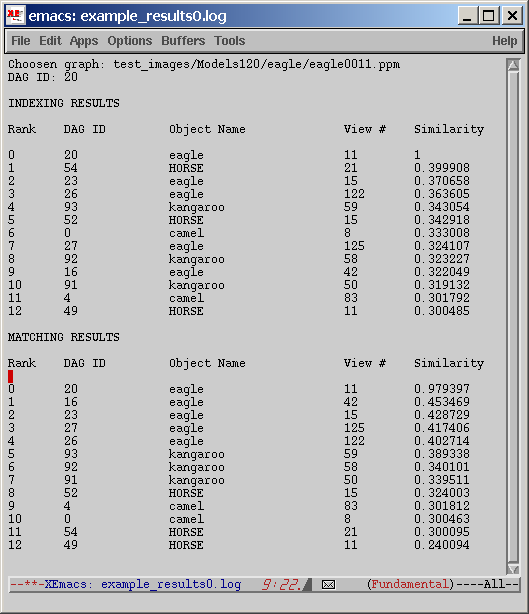
m: match shapes in one database against shapes in other database.
FAQ1. Can this approach deal with noise due to segmentation errors? Yes. ShapeMatcher 5 can handle bumps and indentations on the shape boundary. However, if the amount of noise is large, there is an option that can be used to produce more stable results: "-doExtSimp 1" [default value]. This option adds a simplification step that can deal with large amouns of noise. See the readme.txt file in the tarball for details. e.g., > sm -doExtSimp 1 -bndryWeight 500 -tsTau2 20 -c example.db test_images/Models120The "bndryWeight" option controls the trade-off between reconstruction error and representational simplicity. "tsTau2=nn" is independent of the external simplicication command, but it has a similar effect with a light computational overhead. It is useful to combine both options. Note that "tsTau2>0" shortens the resulting skeleton branches while doExtSimp=1 does not. NOTE: type "test_images\Models120" in Windows. 2. The skeletonization step is slow. Can it run faster? Yes, if the external [branches] simplification step is turned off. Just add -doExtSimp 0 in the command line. 3. What about partial occlusion? Yes. The shock graph representation used by ShapeMatcher 5 can handle partial occlusion. 4. Do shock graphs represent shape holes? No. Holes within a shape are filled in. Two shapes with different number/kind of holes would look identical to the matcher. 5. Is this approach scale invariant? Yes, but the current implementation is not. ShapeMatcher 5 can only deal with minor scale differences. If you need to handle large variations in the scale of the query and the model shapes, you would need to normalize their sizes first. For example, a method that may work for some objects would be to make the shapes fit a fixed-size bounding box. Note that this simple strategy can fail with articulated objects (e.g., a person with the arms extended would define a large bounding box.) 6. What type of skeletons are computed? There are two options for the skeletonization algorithm used: the Flux-based skeletons developed at McGill University by Pavel Dimitrov, Carlos Phillips and Kaleem Siddiqi and the A* Fast Marching Method skeletons developed by Alex Telea at Technische Universiteit Eindhoven. To use the flux skeletons use option -skelcode 2 and for the AFMM skeletons use -skelcode 3 [the default]. Currently, these are the only two options. In a future release we will include Voronoi skeletons (-skelcode 1) for comparison/teaching purposes. 7. How can I contribute to the project? Send me an email. There are lots of things to do, such as improving the graph indexing and matching mechanism, completing the documentation, and running parts of the code in the GPU. More infoIndexing and Matching for View-Based 3-D Object Recognition Using Shock Graphs |
||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}