Andrew Li
PhD Candidate, Computer Science
University of Toronto
| andrewli[@]cs[.]toronto[.]edu | |
| Google Scholar | |
| CV |
Background
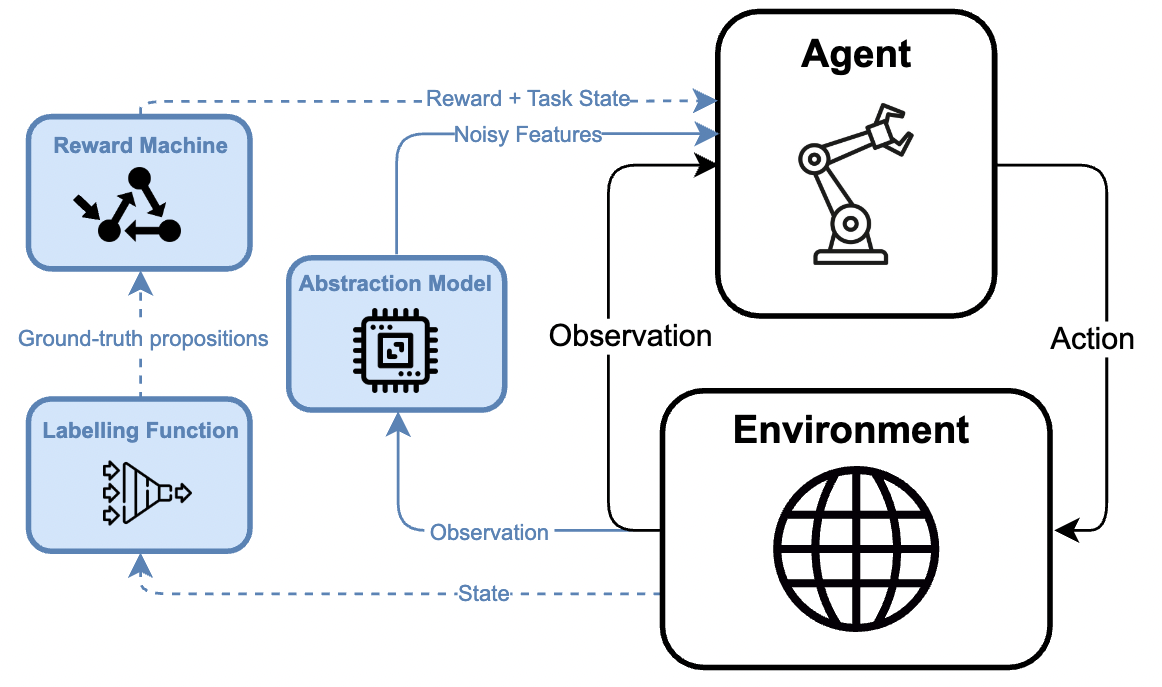
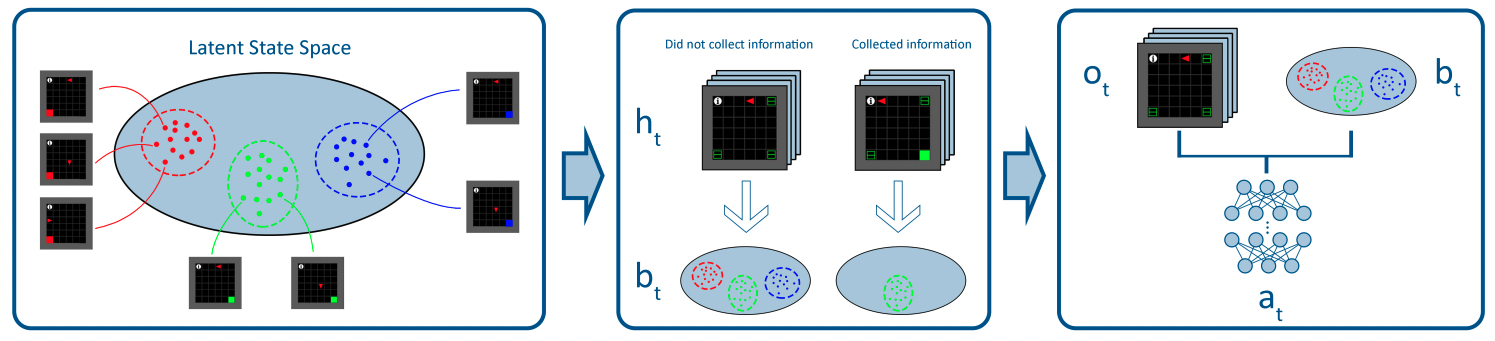
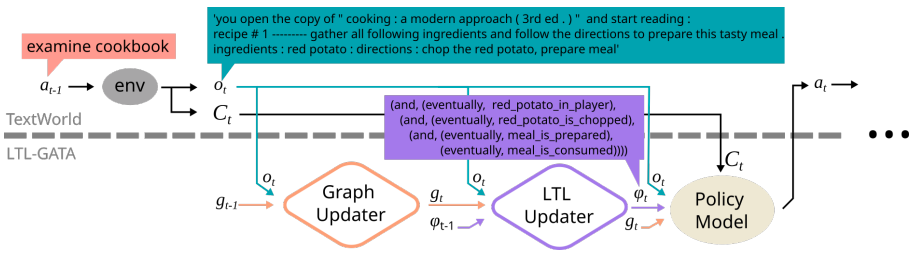
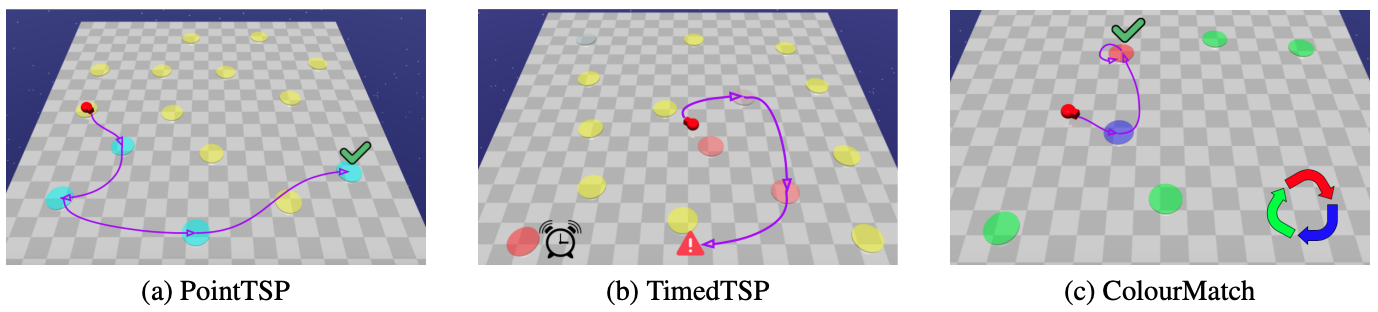
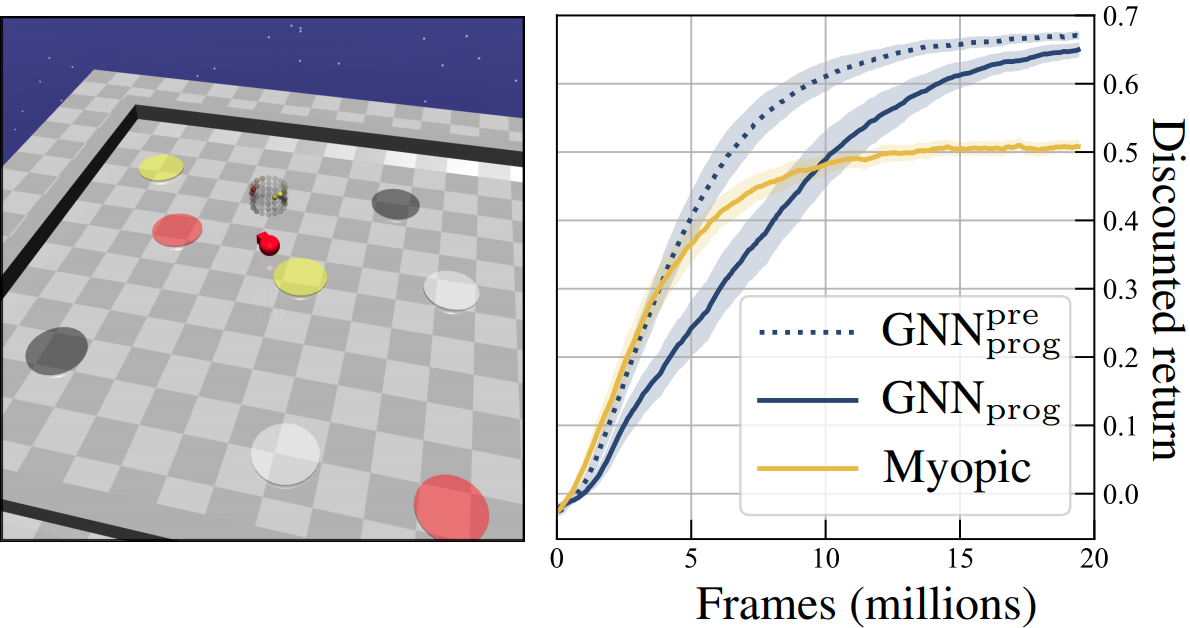
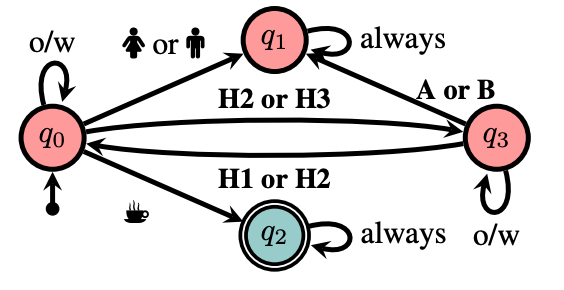
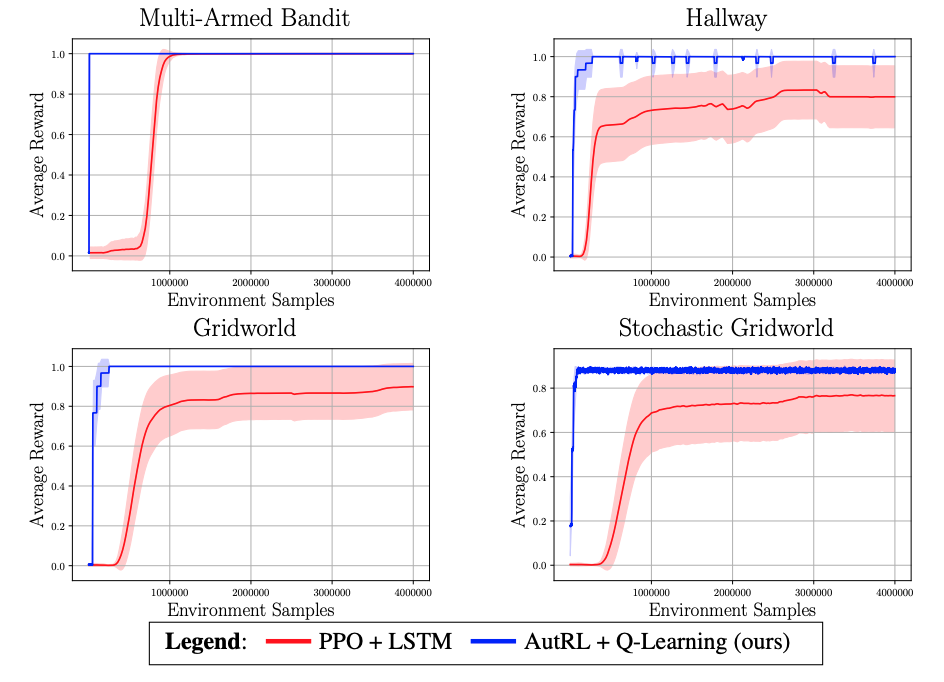
I am a final-year PhD student in Computer Science at the University of Toronto and the Vector Institute for Artificial Intelligence, supervised by Sheila McIlraith. My research interests lie at the intersection of machine learning (particularly reinforcement learning), AI planning, and knowledge representation & reasoning. I aim to develop AI that learns over a long lifetime by acquiring knowledge from its interactions with the world, abstracting knowledge into generalizable concepts, and reasoning at a high-level to robustly handle new situations.
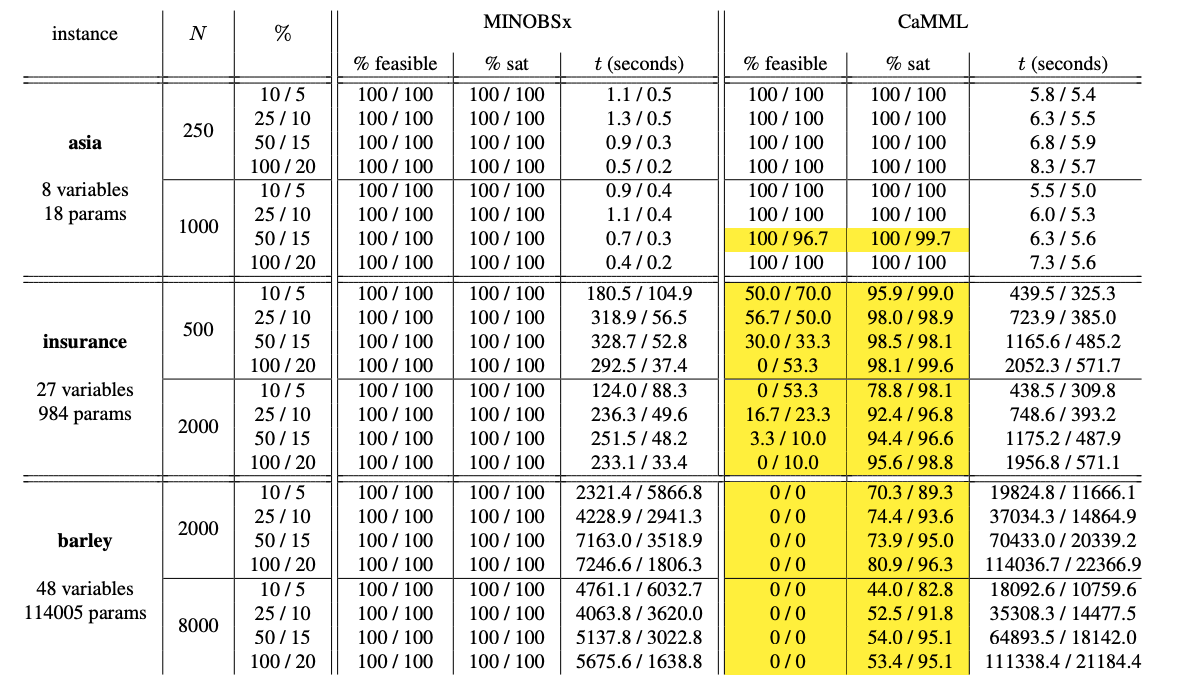
In 2023, I interned at Zoox, where I worked on reinforcement learning for autonomous driving. As an undergrad at the University of Waterloo, I researched combinatorial optimization algorithms for learning Bayesian network structures from data. Before that, I was one of the top competitive programmers in Canada.
Education
-
Candidate for Ph.D. in Computer Science, 2021 - present
University of Toronto -
M.Sc. in Computer Science, 2019 - 2021
University of Toronto -
B.Math. in Computer Science, Combinatorics & Optimization (Double Major), 2015 - 2019
University of Waterloo