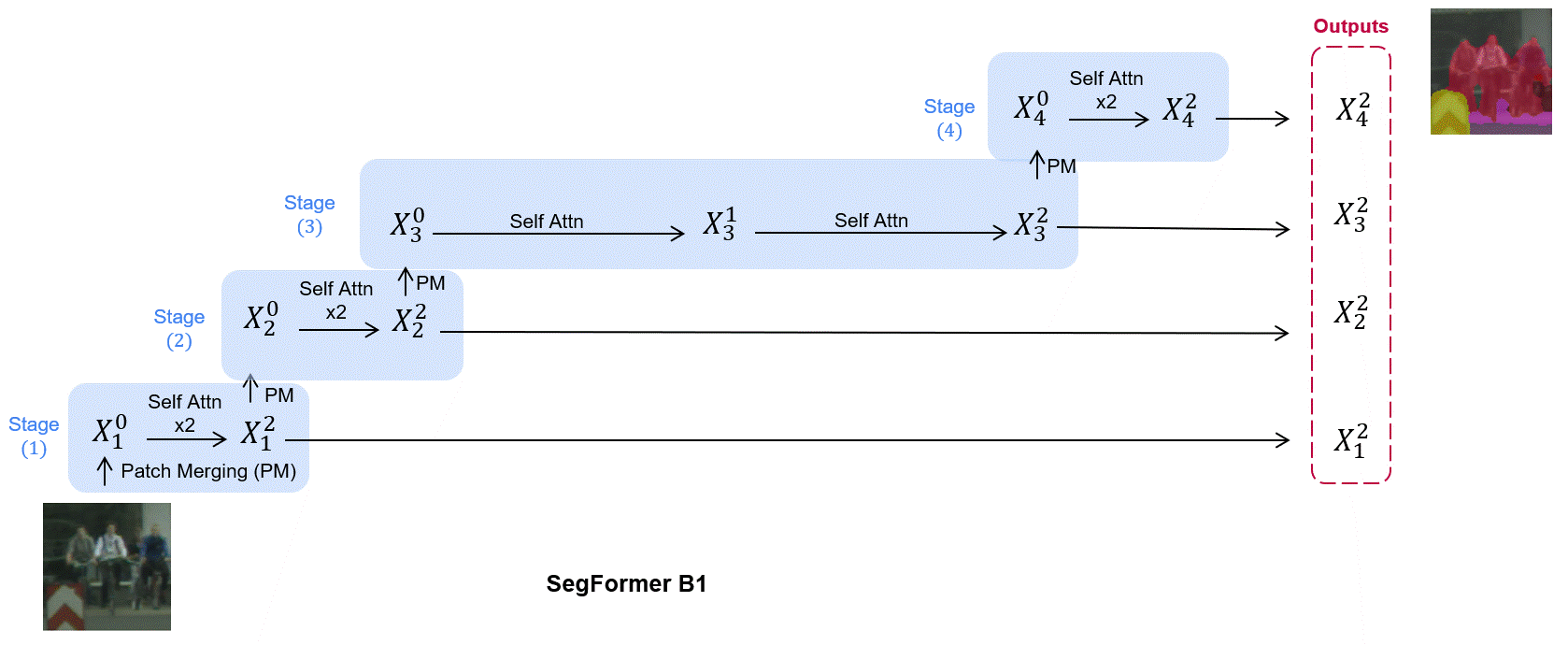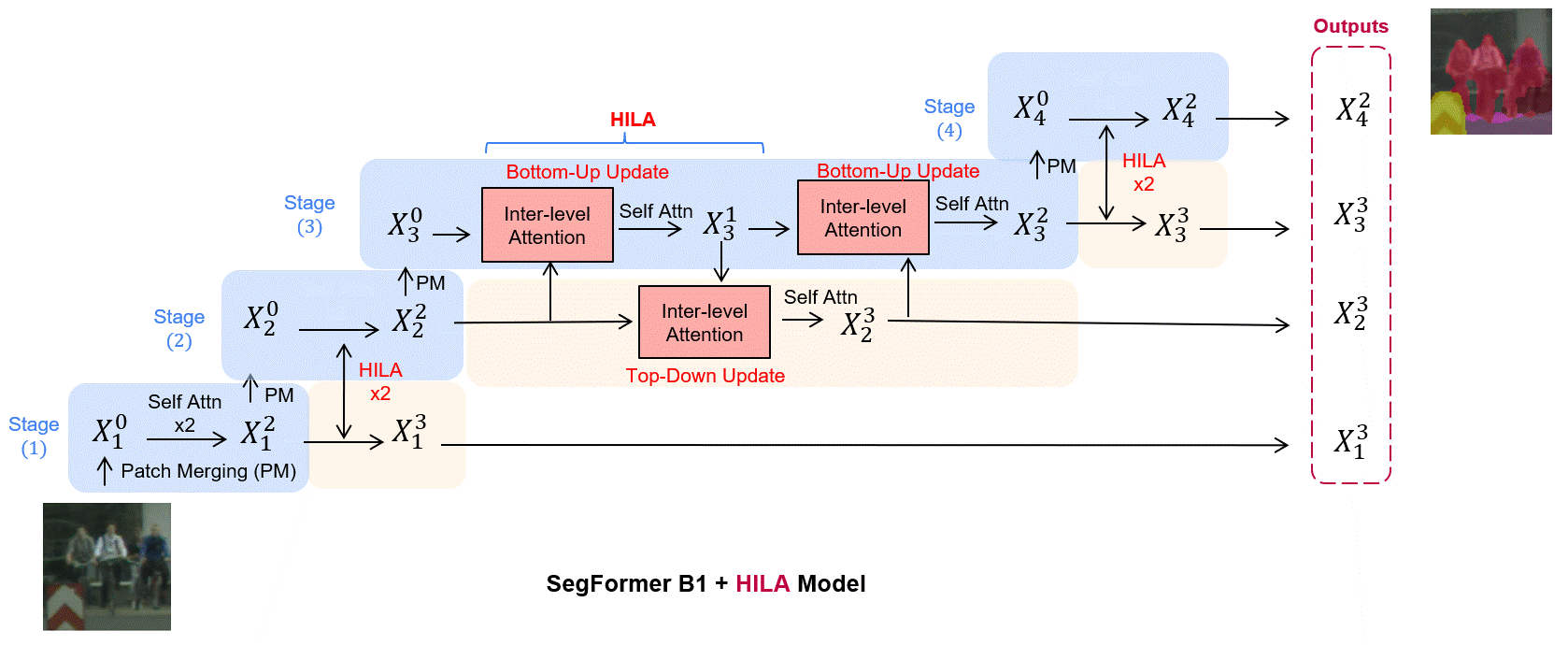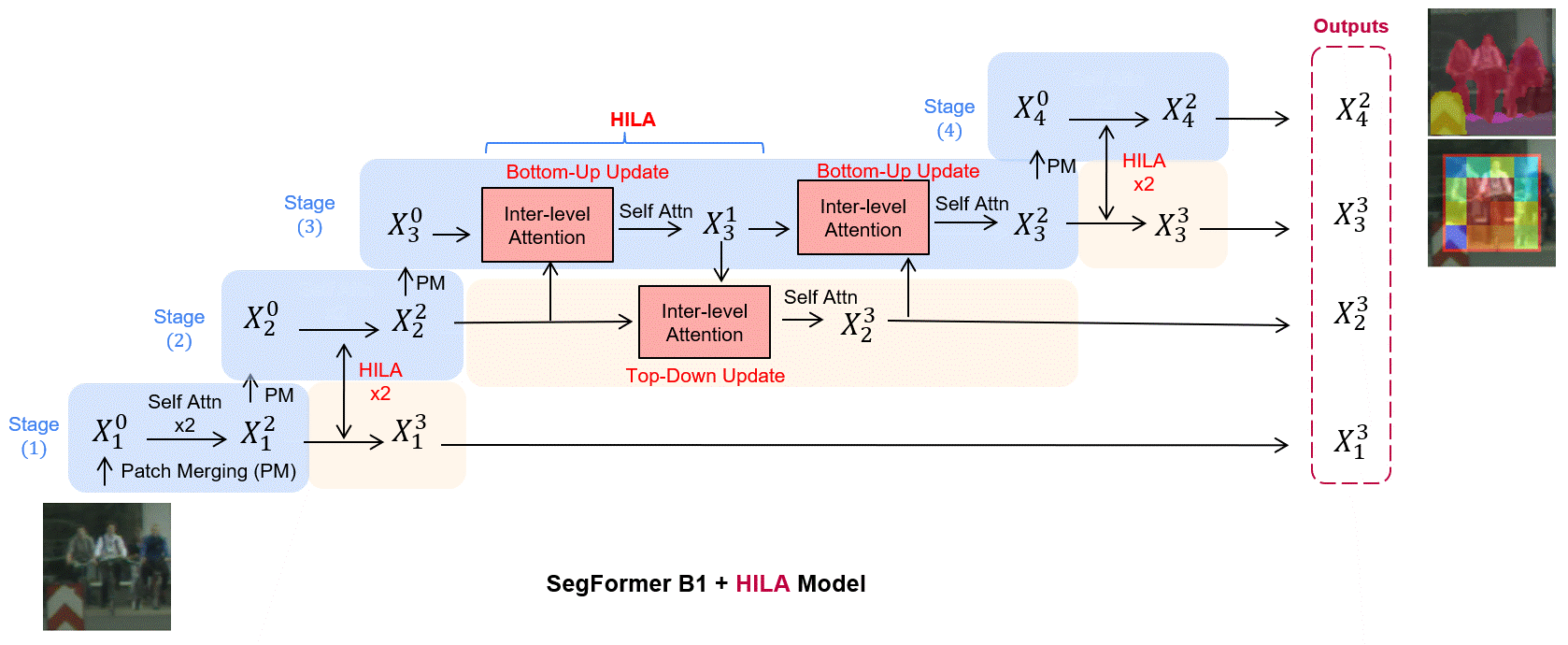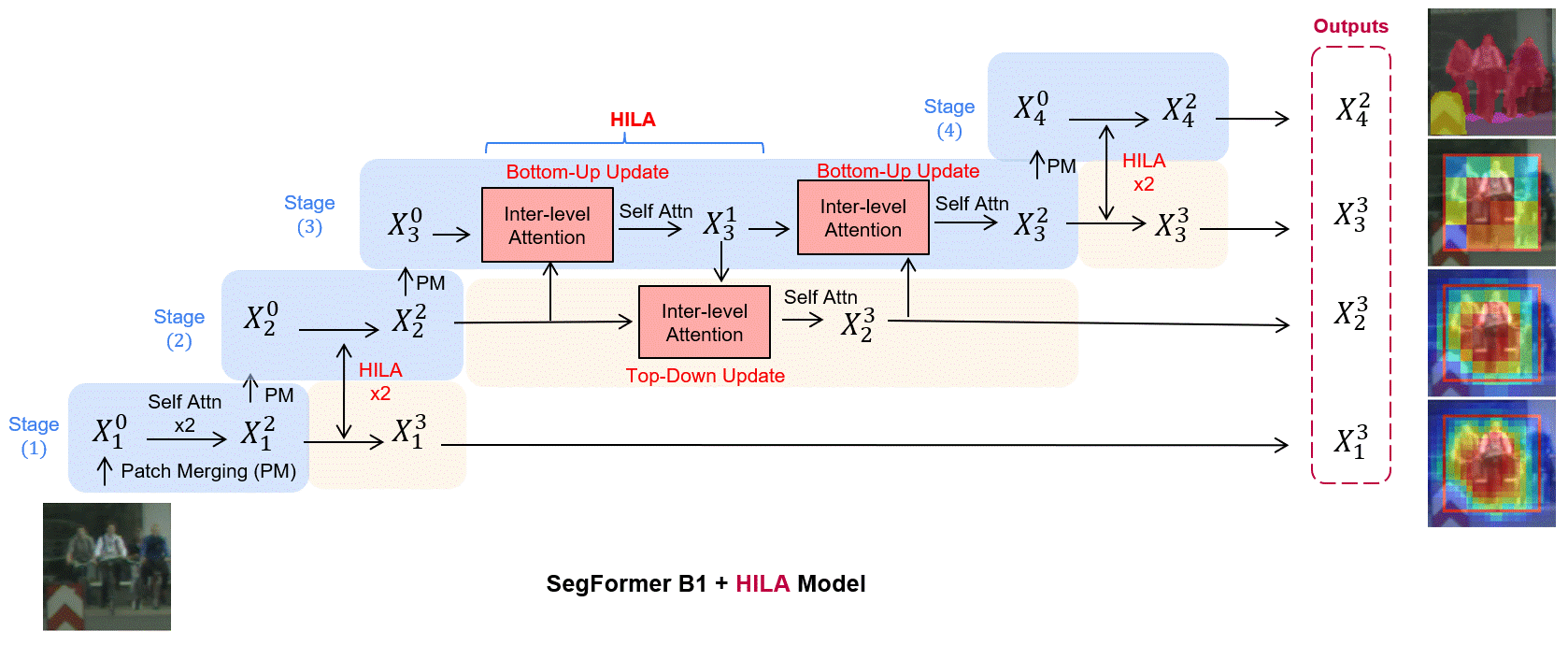
Existing transformer-based image backbones typically propagate feature information in one direction from lower to higher-levels.
This may not be ideal since the localization ability to delineate accurate object boundaries, is most prominent in the lower, high-resolution
feature maps, while the semantics that can disambiguate image signals
belonging to one object vs. another, typically emerges in a higher level
of processing. We present Hierarchical Inter-Level Attention (HILA), an
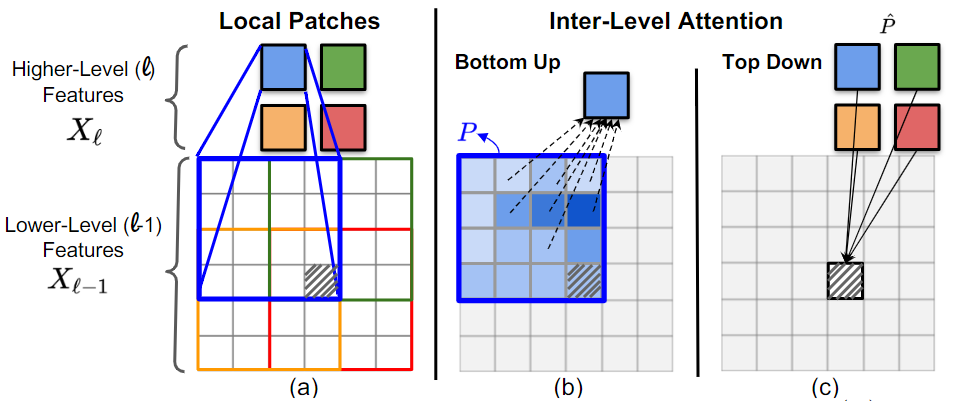
attention-based method that captures Bottom-Up and Top-Down Updates between features of different levels. HILA extends hierarchical vision transformer architectures by adding local connections between features of higher and lower levels to the backbone encoder. In each iteration, we construct a hierarchy by having higher-level features compete
for assignments to update lower-level features belonging to them, iteratively resolving object-part relationships. These improved lower-level
features are then used to re-update the higher-level features. HILA can
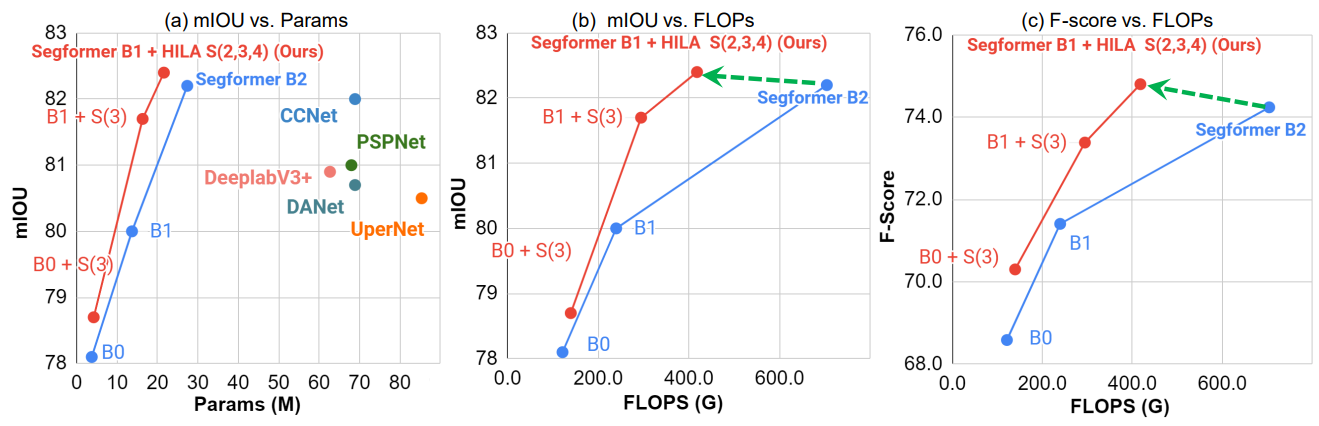
be integrated into the majority of hierarchical architectures without requiring any changes to the base model. We add HILA into SegFormer
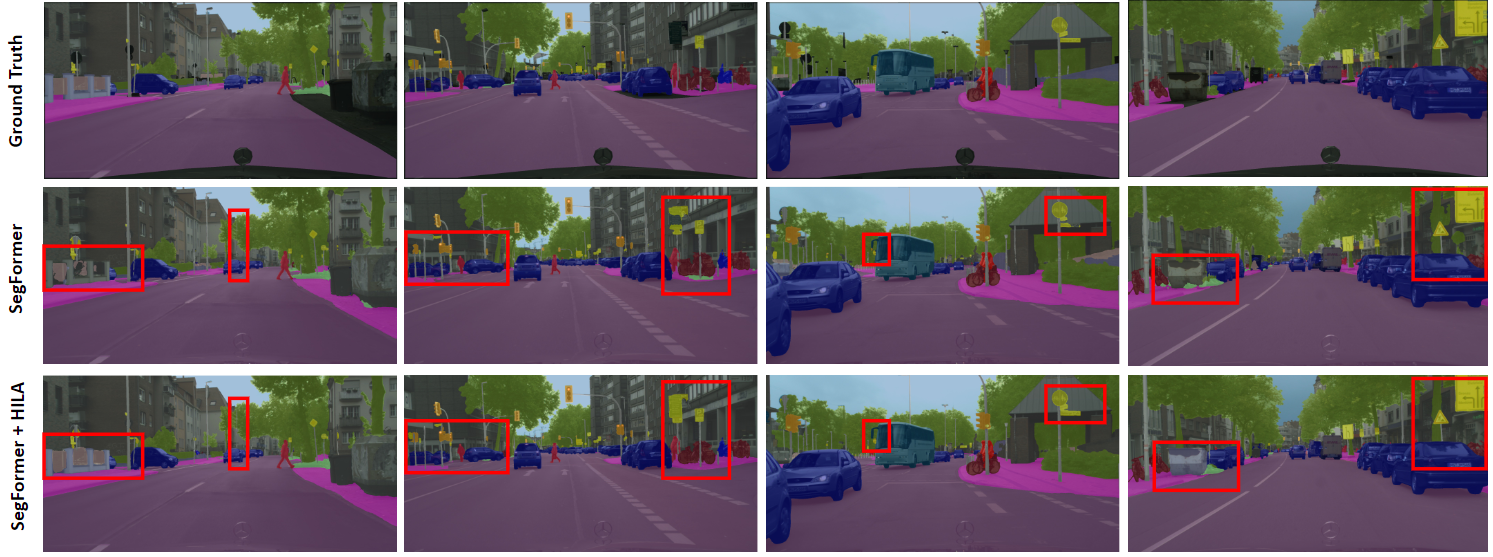
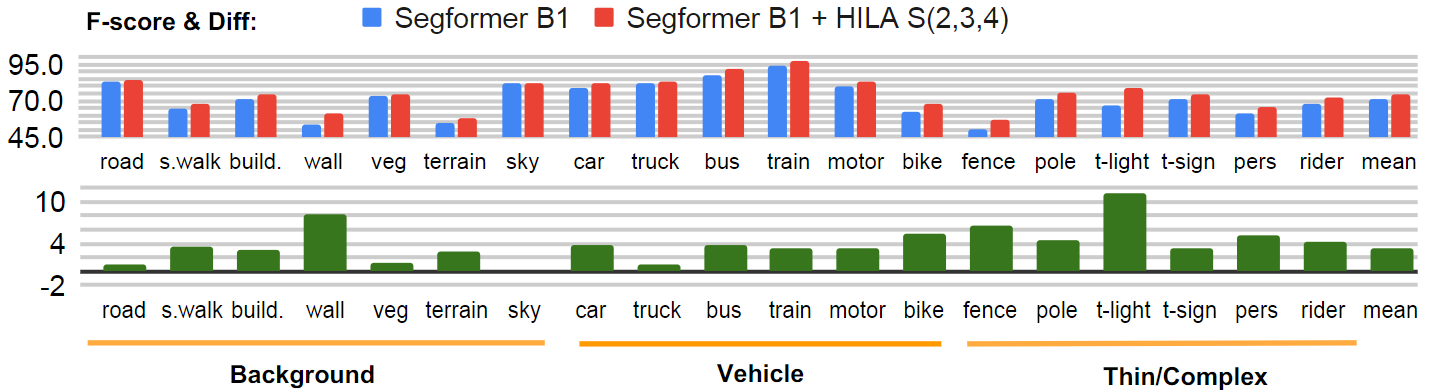
and the Swin Transformer and show notable improvements in accuracy
in semantic segmentation with fewer parameters and FLOPS.
|