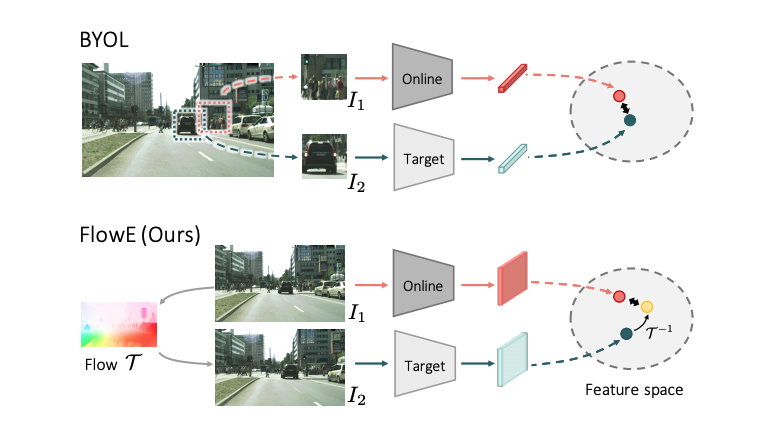
 |
Self-Supervised Representation Learning from Flow Equivariance
Yuwen Xiong,
Mengye Ren,
Wenyuan Zeng,
Raquel Urtasun
International Conference on Computer Vision (ICCV),
Montreal, 2021
show abstract
/
paper
Self-supervised learning from video streams of complex scenes.
Self-supervised representation learning is able to learn semantically meaningful features; however,
much of its recent success relies on multiple crops of an image with very few objects. Instead of
learning view-invariant representation from simple images, humans learn representations in a complex
world with changing scenes by observing object movement, deformation, pose variation, and ego motion.
Motivated by this ability, we present a new self-supervised learning representation framework that can
be directly deployed on a video stream of complex scenes with many moving objects. Our framework
features a simple flow equivariance objective that encourages the network to predict the features of
another frame by applying a flow transformation to the features of the current frame. Our
representations, learned from high-resolution raw video, can be readily used for downstream tasks on
static images. Readout experiments on challenging semantic segmentation, instance segmentation, and
object detection benchmarks show that we are able to outperform representations obtained from previous
state-of-the-art methods including SimCLR and BYOL.
|
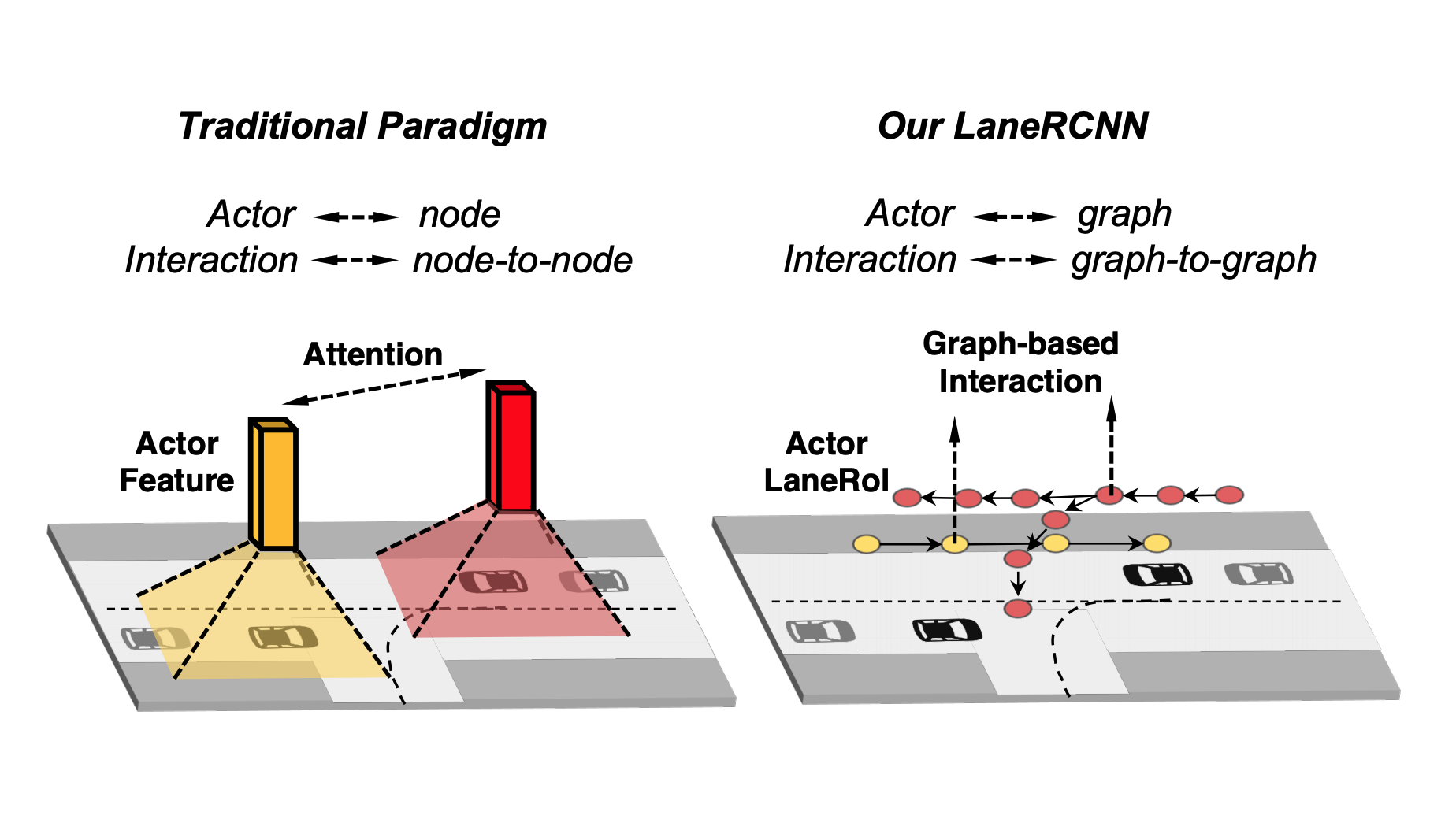 |
LaneRCNN: Distributed Representations for Graph-Centric Motion
Forecasting
Wenyuan Zeng,
Ming Liang,
Renjie Liao,
Raquel Urtasun
International Conference on Intelligent Robots and Systems (IROS),
Prague, 2021
Ranked 1st place on Argoverse
Motion
Forecasting Leaderboard (Nov-16 2020).
show abstract
/
paper
Graph-centric motion forecasting model for autonomous driving.
Forecasting the future behaviors of dynamic actors is an important task in many robotics applications
such as self-driving. It is extremely challenging as actors have latent intentions and their
trajectories are governed by complex interactions between the other actors, themselves, and the maps.
In this paper, we propose LaneRCNN, a graph-centric motion forecasting model. Importantly, relying on
a specially designed graph encoder, we learn a local lane graph representation per actor (LaneRoI) to
encode its past motions and the local map topology. We further develop an interaction module which
permits efficient message passing among local graph representations within a shared global lane graph.
Moreover, we parameterize the output trajectories based on lane graphs, a more amenable prediction
parameterization. Our LaneRCNN captures the actor-to-actor and the actor-to-map relations in a
distributed and map-aware manner. We demonstrate the effectiveness of our approach on the large-scale
Argoverse Motion Forecasting Benchmark. We achieve the 1st place on the leaderboard and significantly
outperform previous best results.
|
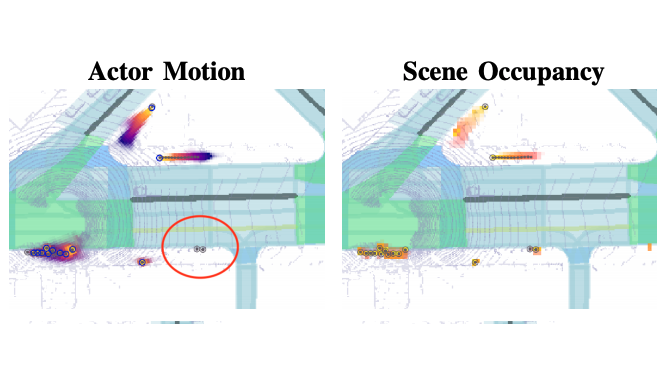 |
Safety-Oriented Pedestrian Motion and Scene Occupancy Forecasting
Katie Luo*,
Sergio Casas*,
Xinchen Yan,
Yuwen Xiong,
Wenyuan Zeng,
Raquel Urtasun
International Conference on Intelligent Robots and Systems (IROS),
Prague, 2021
show abstract
/
paper
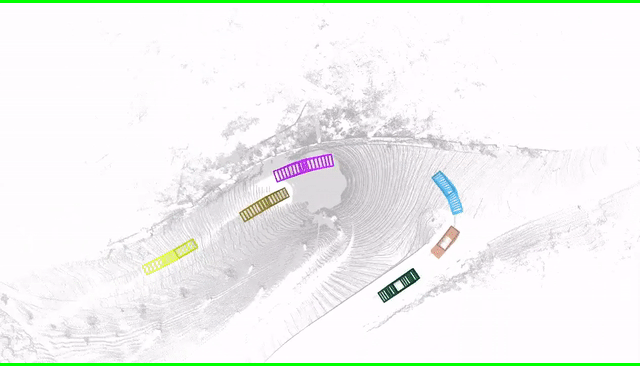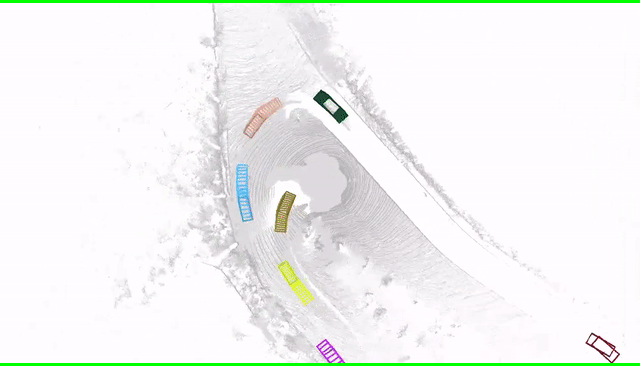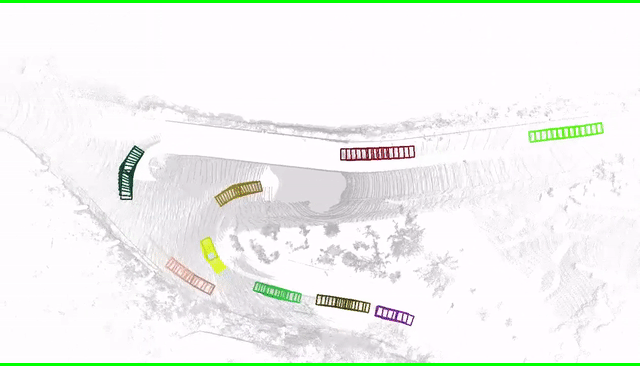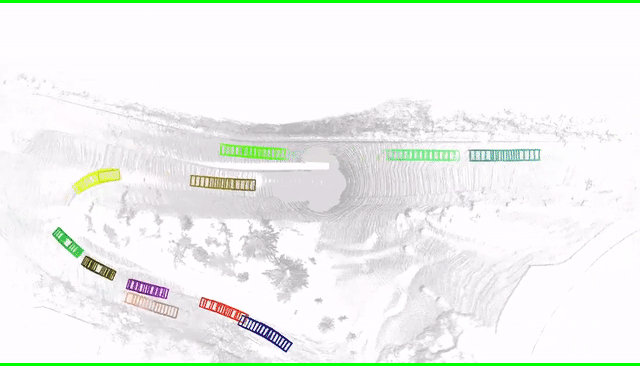
Hybrid instance-based and instance-free approach to pedestrian behavior prediction.
In this paper, we address the important problem in self-driving of forecasting multi-pedestrian motion
and their shared scene occupancy map, critical for safe navigation. Our contributions are two-fold.
First, we advocate for predicting both the individual motions as well as the scene occupancy map in
order to effectively deal with missing detections caused by postprocessing, e.g., confidence
thresholding and non-maximum suppression. Second, we propose a Scene-Actor Graph Neural Network
(SA-GNN) which preserves the relative spatial information of pedestrians via 2D convolution, and
captures the interactions among pedestrians within the same scene, including those that have not been
detected, via message passing. On two large-scale real-world datasets, nuScenes and ATG4D, we showcase
that our scene-occupancy predictions are more accurate and better calibrated than those from
state-of-the-art motion forecasting methods, while also matching their performance in pedestrian
motion forecasting metrics.
|
 |
Auto4D: Learning to Label 4D Objects from Sequential Point Clouds
Bin Yang,
Min Bai,
Ming Liang,
Wenyuan Zeng,
Raquel Urtasun
Technical Report, 2021
show abstract
/
paper
Improve low-quality object tracks with fixed sizes and smoother motions.
In the past few years we have seen great advances in object perception (particularly in 4D space-time
dimensions) thanks to deep learning methods. However, they typically rely on large amounts of
high-quality labels to achieve good performance, which often require time-consuming and expensive work
by human annotators. To address this we propose an automatic annotation pipeline that generates
accurate object trajectories in 3D space (i.e., 4D labels) from LiDAR point clouds. The key idea is to
decompose the 4D object label into two parts: the object size in 3D that's fixed through time for
rigid objects, and the motion path describing the evolution of the object's pose through time. Instead
of generating a series of labels in one shot, we adopt an iterative refinement process where online
generated object detections are tracked through time as the initialization. Given the cheap but noisy
input, our model produces higher quality 4D labels by re-estimating the object size and smoothing the
motion path, where the improvement is achieved by exploiting aggregated observations and motion cues
over the entire trajectory. We validate the proposed method on a large-scale driving dataset and show
a 25% reduction of human annotation efforts. We also showcase the benefits of our approach in the
annotator-in-the-loop setting.
|
 |
Network Automatic Pruning: Start NAP and Take a Nap
Wenyuan Zeng,
Yuwen Xiong,
Raquel Urtasun
Technical Report, 2021
show abstract
/
paper
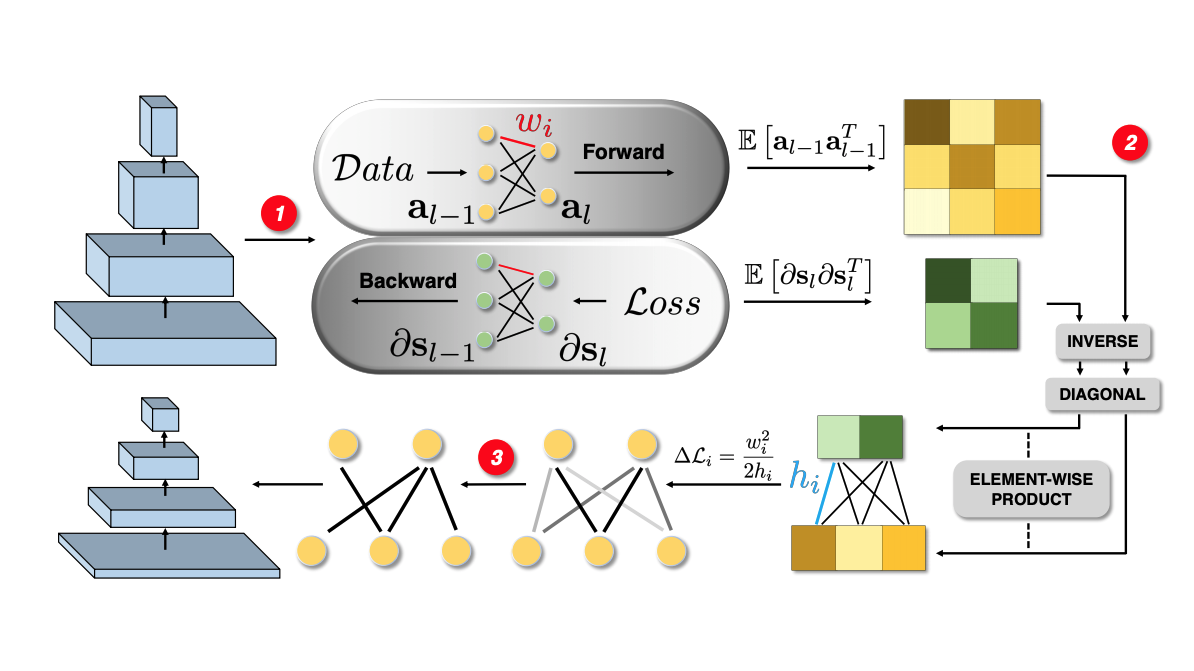
Automatic pruning your network with almost no hyper-parameter tunning.
Network pruning can significantly reduce the computation and memory footprint of large neural
networks. To achieve a good trade-off between model size and performance, popular pruning techniques
usually rely on hand-crafted heuristics and require manually setting the compression ratio for each
layer. This process is typically time-consuming and requires expert knowledge to achieve good results.
In this paper, we propose NAP, a unified and automatic pruning framework for both fine-grained and
structured pruning. It can find out unimportant components of a network and automatically decide
appropriate compression ratios for different layers, based on a theoretically sound criterion. Towards
this goal, NAP uses an efficient approximation of the Hessian for evaluating the importances of
components, based on a Kronecker-factored Approximate Curvature method. Despite its simpleness to use,
NAP outperforms previous pruning methods by large margins. For fine-grained pruning, NAP can compress
AlexNet and VGG16 by 25x, and ResNet-50 by 6.7x without loss in accuracy on ImageNet. For structured
pruning (e.g. channel pruning), it can reduce flops of VGG16 by 5.4x and ResNet-50 by 2.3x with only
1% accuracy drop. More importantly, this method is almost free from hyper-parameter tuning and
requires no expert knowledge. You can start NAP and then take a nap!
|
 |
Permute, Quantize, and Fine-tune: Efficient Compression of Neural
Networks
Julieta Martinez*,
Jashan
Shewakramani*,
Ting Wei Liu*,
Ioan Andrei Bârsan,
Wenyuan Zeng,
Raquel Urtasun
Computer Vision and Pattern Recognition
(CVPR), 2021.
Oral Presentation
show abstract
/
paper
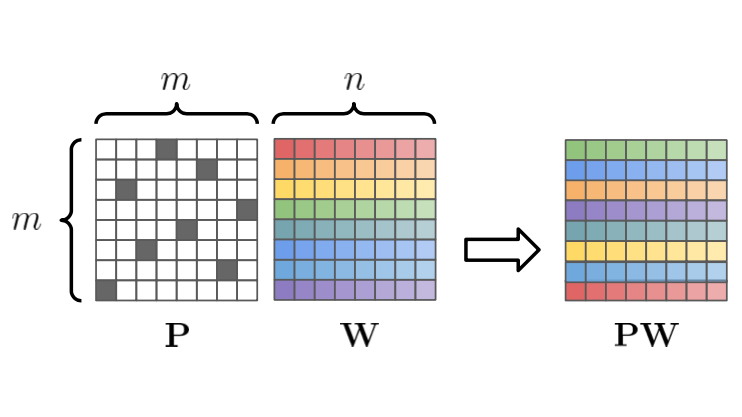
Boosting compression ratios with permute, quantize and then fine-tune.
Compressing large neural networks is an important step for their deployment in resource-constrained
computational platforms. In this context, vector quantization is an appealing framework that expresses
multiple parameters using a single code, and has recently achieved state-of-the-art network
compression on a range of core vision and natural language processing tasks. Key to the success of
vector quantization is deciding which parameter groups should be compressed together. Previous work
has relied on heuristics that group the spatial dimension of individual convolutional filters, but a
general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate
modern architectures), linear layers (which have no notion of spatial dimension), and convolutions
(when more than one filter is compressed to the same codeword). In this paper we make the observation
that the weights of two adjacent layers can be permuted while expressing the same function. We then
establish a connection to rate-distortion theory and search for permutations that result in networks
that are easier to compress. Finally, we rely on an annealed quantization algorithm to better compress
the network and achieve higher final accuracy. We show results on image classification, object
detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to
the current state of the art.
|
 |
Perceive, Attend, and Drive: Learning Spatial Attention for Safe
Self-Driving
Bob Wei*,
Mengye Ren*,
Wenyuan Zeng,
Ming Liang,
Bin Yang,
Raquel Urtasun
International Conference on Robotics and Automation
(ICRA), Xi'an, 2021.
show abstract
/
paper
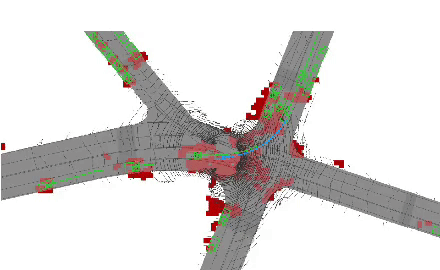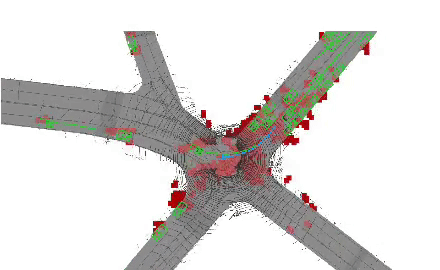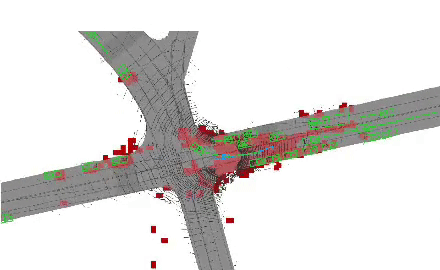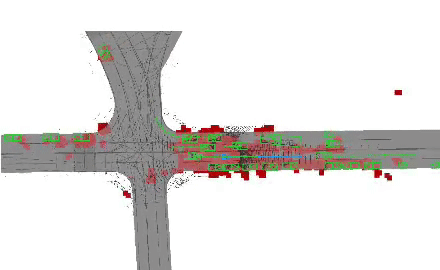
End-to-end neural motion planner with adaptive attention.
In this paper, we propose an end-to-end self-driving network featuring a sparse attention module that
learns to automatically attend to important regions of the input. The attention module specifically
targets motion planning, whereas prior literature only applied attention in perception tasks. Learning
an attention mask directly targeted for motion planning significantly improves the planner safety by
performing more focused computation. Furthermore, visualizing the attention improves interpretability
of end-to-end self-driving.
|
 |
Deep Structured Reactive Planning
Jerry Liu,
Wenyuan Zeng,
Raquel Urtasun
Ersin Yumer
International Conference on Robotics and Automation
(ICRA), Xi'an, 2021.
show abstract
/
paper
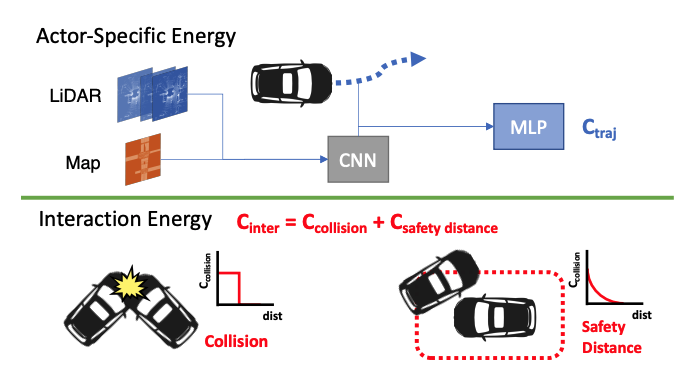
Joint prediction and planning with reactive behaviors.
An intelligent agent operating in the real-world must balance achieving its goal with maintaining the
safety and comfort of not only itself, but also other participants within the surrounding scene. This
requires jointly reasoning about the behavior of other actors while deciding its own actions as these
two processes are inherently intertwined - a vehicle will yield to us if we decide to proceed first at
the intersection but will proceed first if we decide to yield. However, this is not captured in most
self-driving pipelines, where planning follows prediction. In this paper we propose a novel
data-driven, reactive planning objective which allows a self-driving vehicle to jointly reason about
its own plans as well as how other actors will react to them. We formulate the problem as an
energy-based deep structured model that is learned from observational data and encodes both the
planning and prediction problems. Through simulations based on both real-world driving and
synthetically generated dense traffic, we demonstrate that our reactive model outperforms a
non-reactive variant in successfully completing highly complex maneuvers (lane merges/turns in
traffic) faster, without trading off collision rate.
|
 |
DSDNet: Deep Structured self-Driving Network
Wenyuan Zeng,
Shenlong Wang,
Renjie Liao,
Yun Chen,
Bin Yang,
Raquel Urtasun
European Conference Computer Vision
(ECCV), Glasgow, 2020.
show abstract
/
paper
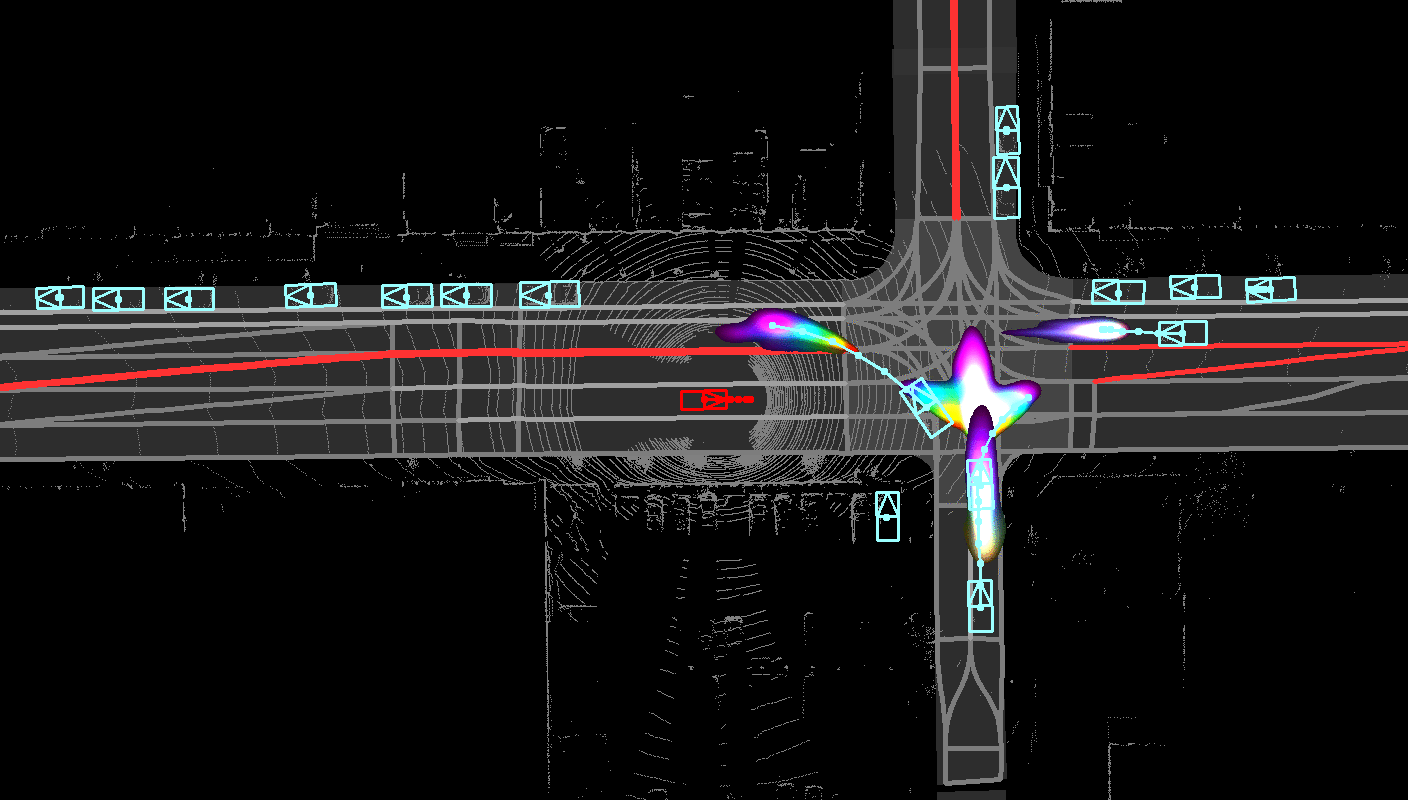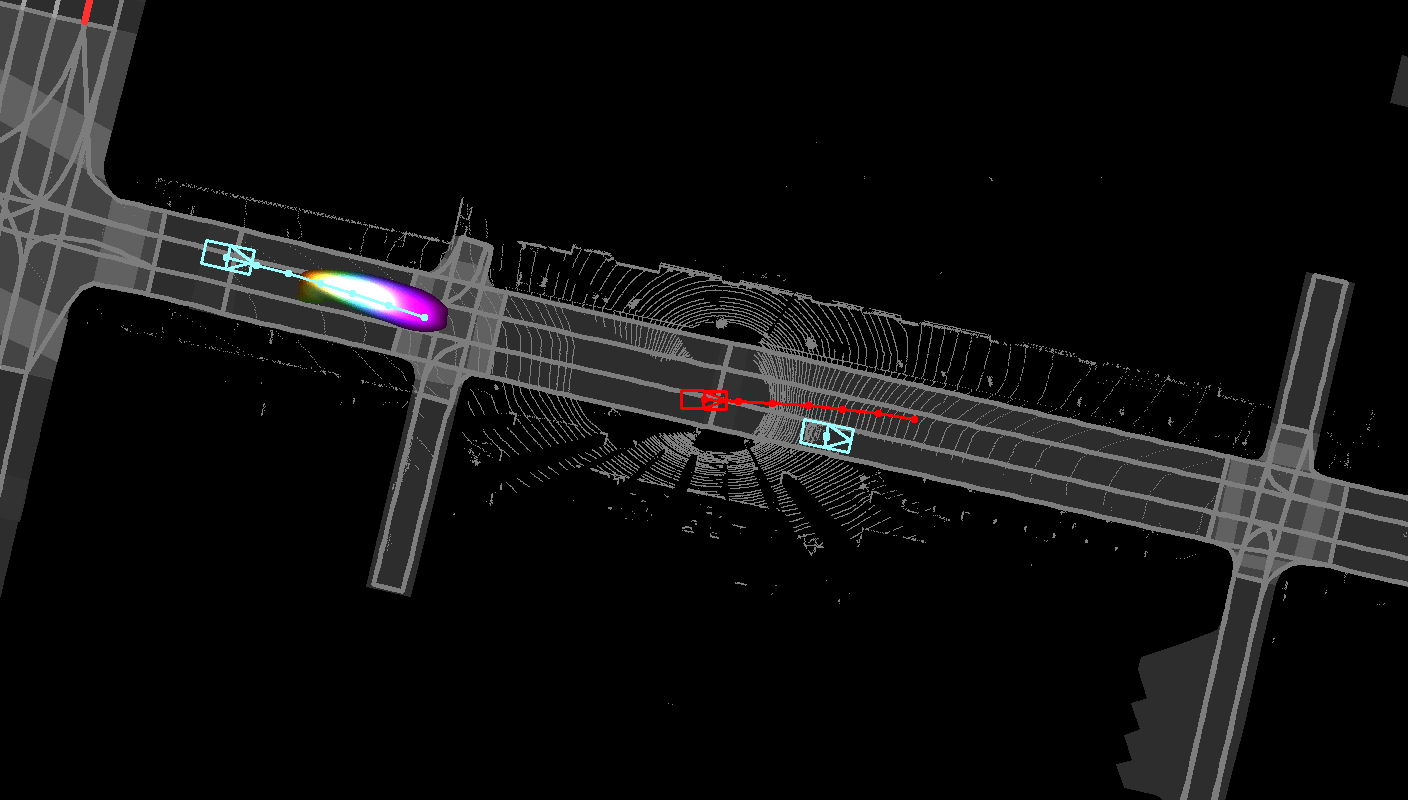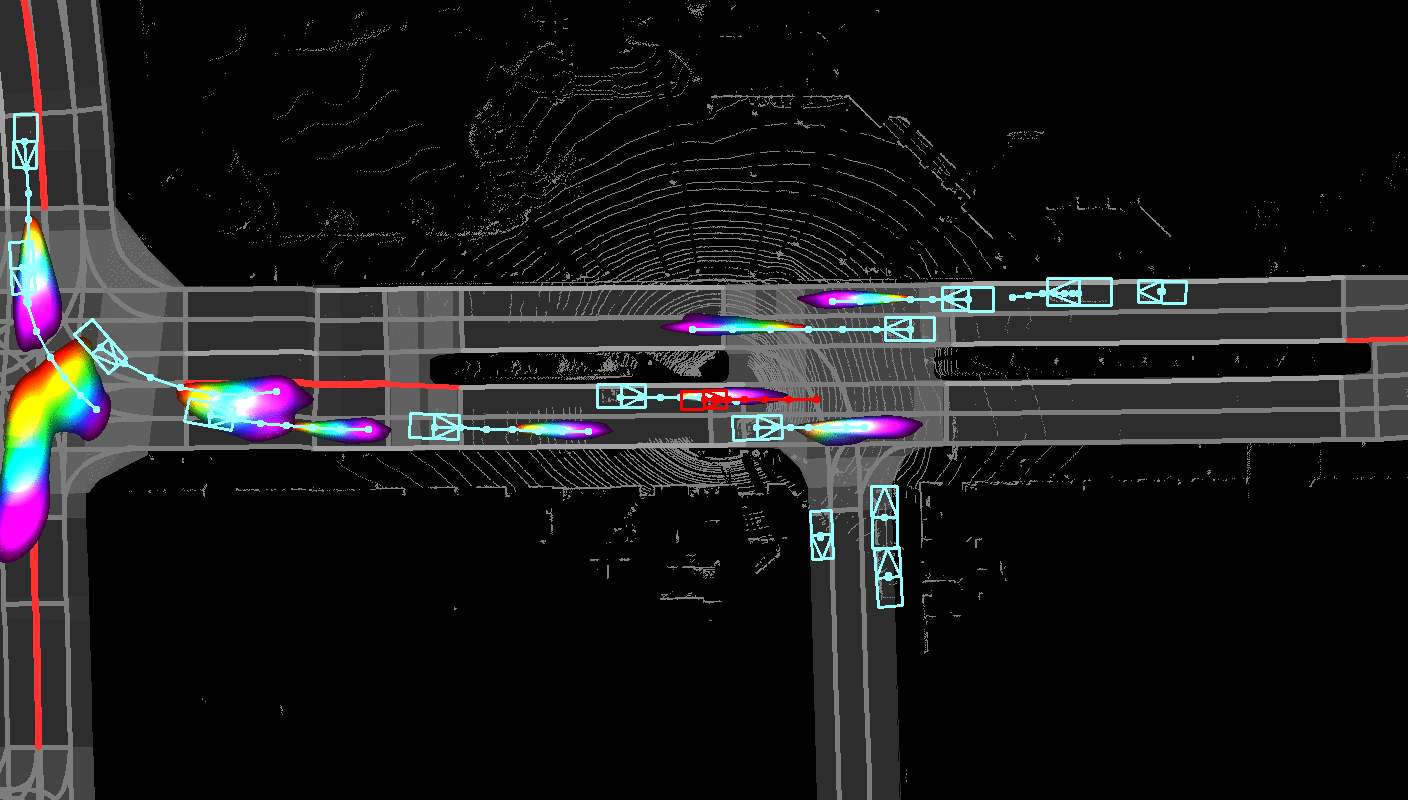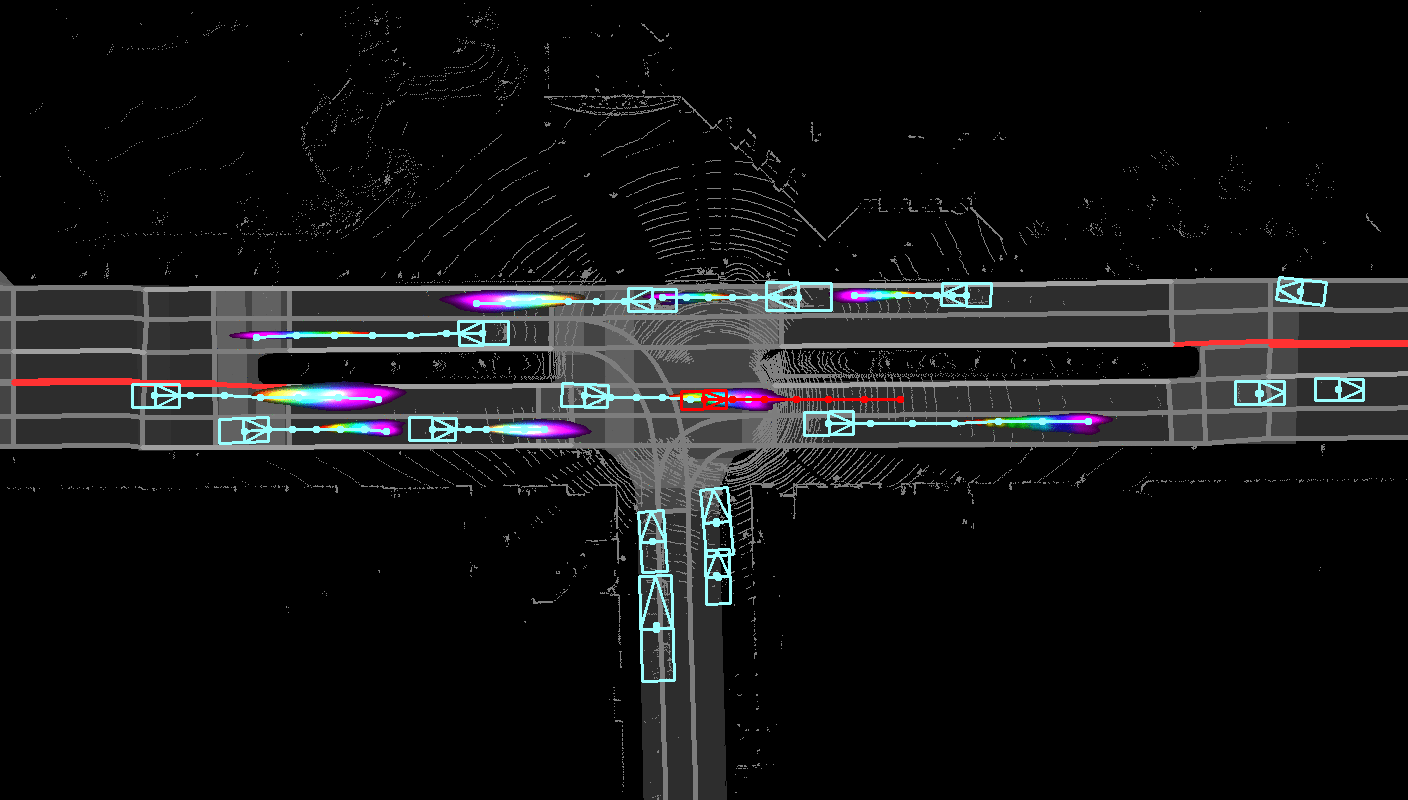
Unified framework for multi-modal social consistent
prediction and safe planning under uncertainties.
In this paper, we propose the Deep Structured self-Driving Network (DSDNet),
which performs object detection, motion prediction, and motion planning with
a single neural network. Towards this goal, we develop a deep structured
energy based model which considers the interactions between actors and produces
socially consistent multimodal future predictions. Furthermore, DSDNet explicitly
exploits the predicted future distributions of actors to plan a safe maneuver
by using a structured planning cost. Our sample-based formulation allows us to
overcome the difficulty in probabilistic inference of continuous random variables.
Experiments on a number of large-scale self driving datasets demonstrate that
our model significantly outperforms the state-of-the-art.
|

|
V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction
Tsun-Hsuan Wang,
Sivabalan Manivasagam,
Ming Liang,
Bin Yang,
Wenyuan Zeng,
Raquel Urtasun
European Conference Computer Vision
(ECCV), Glasgow, 2020.
Oral Presentation
show abstract
/
paper
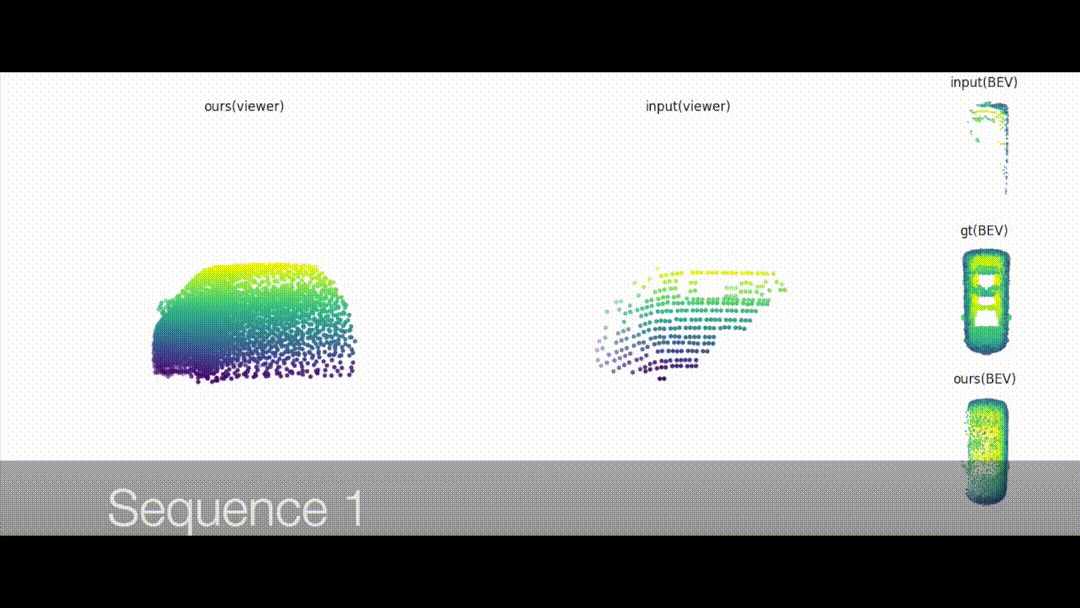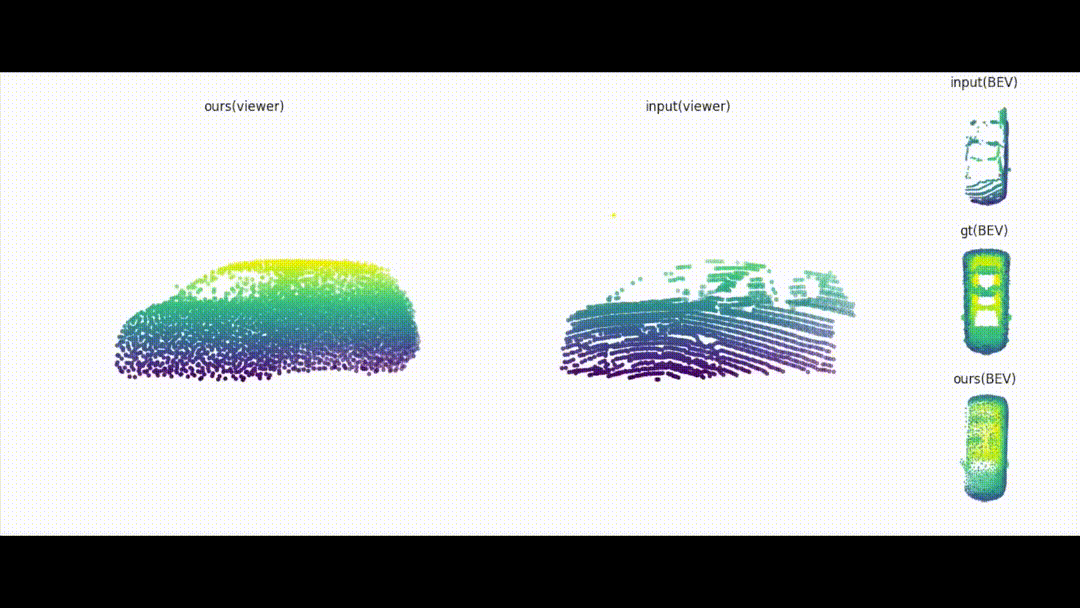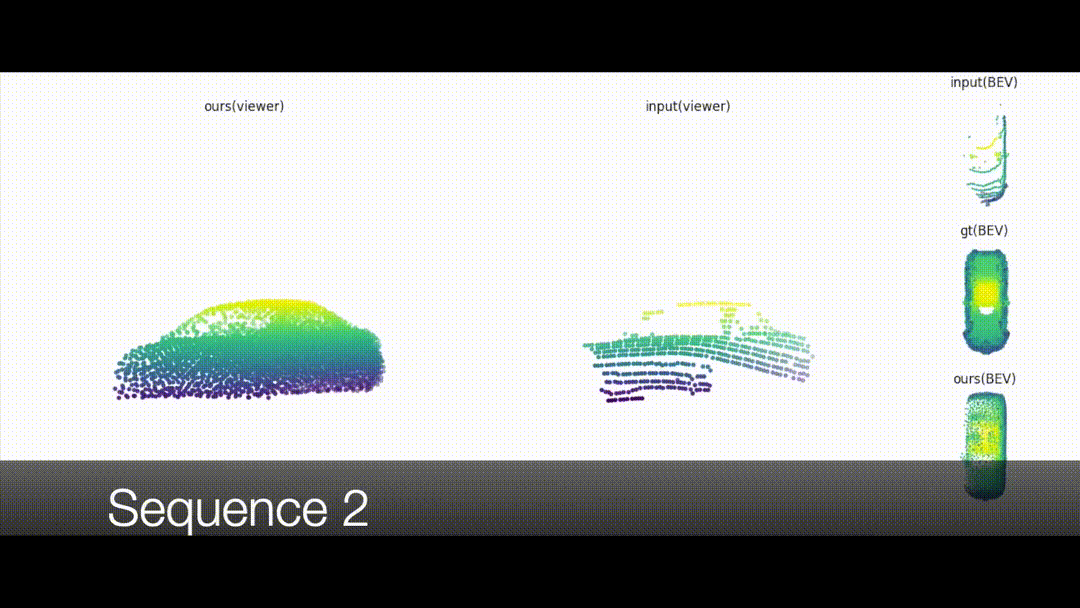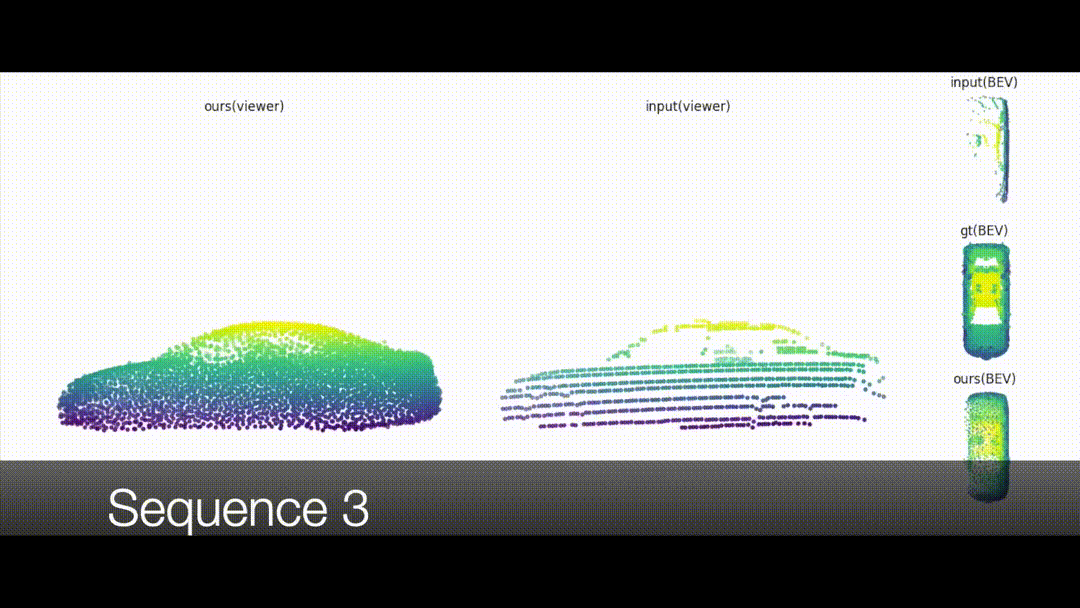
Vehicle to vehicle communication network for self-driving.
In this paper, we explore the use of vehicle-to-vehicle (V2V) communication
to improve the perception and motion forecasting performance of self-driving vehicles.
By intelligently aggregating the information received from multiple nearby vehicles,
we can observe the same scene from different viewpoints. This allows us to see through
occlusions and detect actors at long range, where the observations are very sparse or
non-existent. We also show that our approach of sending compressed deep feature map
activations achieves high accuracy while satisfying communication bandwidth requirements.
|
|
Weakly-supervised 3D Shape Completion in the Wild
Jiayuan
Gu,
Wei-Chiu Ma,
Sivabalan Manivasagam,
Wenyuan Zeng,
Zihao Wang,
Yuwen Xiong,
Hao Su,
Raquel Urtasun
European Conference Computer Vision
(ECCV), Glasgow, 2020.
Spotlight Presentation
show abstract
/
paper
Learning 3D shape reconstruction from unaligned and noisy partial
point clouds.
3D shape completion for real data is important but challenging, since partial point clouds
acquired by real-world sensors are usually sparse, noisy and unaligned. Different from previous
methods, we address the problem of learning 3D complete shape from unaligned and real-world partial
point clouds. To this end, we propose an unsupervised method to estimate both 3D canonical shape and
6-DoF pose for alignment, given multiple partial observations associated with the same instance. The
network jointly optimizes canonical shapes and poses with multi-view geometry constraints during
training, and can infer the complete shape given a single partial point cloud. Moreover, learned pose
estimation can facilitate partial point cloud registration. Experiments on both synthetic and real
data show that it is feasible and promising to learn 3D shape completion through large-scale data
without shape and pose supervision.
|
|
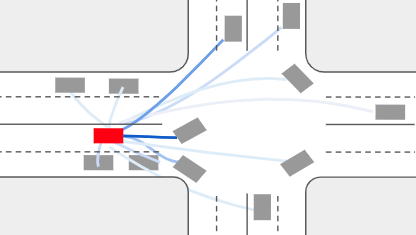
End-to-end Contextual Perception and Prediction with Interaction Transformer
Luke Lingyun Li,
Bin Yang,
Ming
Liang,
Wenyuan Zeng,
Mengye Ren,
Sean Segal,
Raquel Urtasun
International Conference on Intelligent Robots and Systems
(IROS), Las Vegas, 2020.
show abstract
/
paper
Adapt Transformer to model multi-agent interactions in trajectory prediction.
In this paper, we tackle the problem of detecting objects in 3D and forecasting their future motion in
the context of self-driving. Towards this goal, we design a novel approach that explicitly takes into
account the interactions between actors. To capture their spatial-temporal dependencies, we propose a
recurrent neural network with a novel Transformer architecture, which we call the Interaction
Transformer. Importantly, our model can be trained end-to-end, and runs in real-time. We validate our
approach on two challenging real-world datasets: ATG4D and nuScenes. We show that our approach can
outperform the state-of-the-art on both datasets. In particular, we significantly improve the social
compliance between the estimated future trajectories, resulting in far fewer collisions between the
predicted actors.
|

|
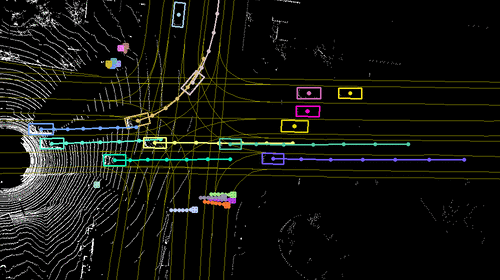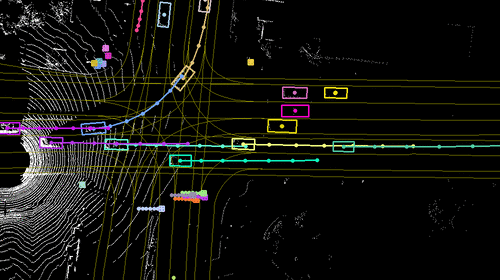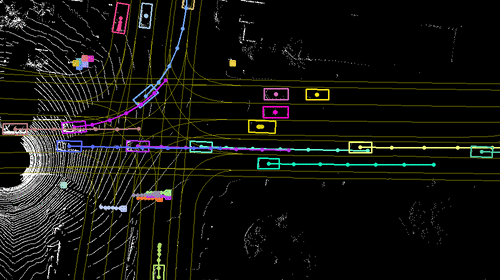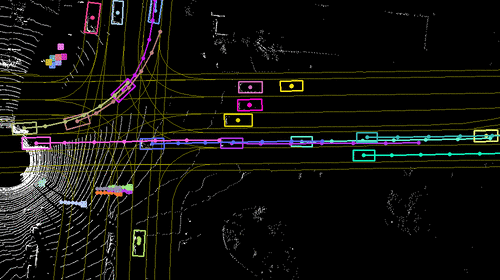
LidarSIM: Realistic LiDAR Simulation by Leveraging the Real World
Sivabalan Manivasagam,
Shenlong Wang,
Kelvin Wong,
Wenyuan Zeng,
Mikita Sazanovich,
Shuhan Tan,
Bin Yang,
Wei-Chiu Ma,
Raquel Urtasun
Computer Vision and Pattern Recognition
(CVPR), Seattle, 2020.
Oral Presentation
show abstract
/
paper
High-fidelity LiDAR simulator for close-loop
evaluating autonomous driving systems.
We tackle the problem of producing realistic simulations of LiDAR point clouds,
the sensor of preference for most self-driving vehicles. We argue that,
by leveraging real data, we can simulate the complex world more realistically
compared to employing virtual worlds built from CAD/procedural models. Towards
this goal, we first build a large catalog of 3D static maps and 3D dynamic objects
by driving around several cities with our self-driving fleet. We can then generate
scenarios by selecting a scene from our catalog and "virtually" placing the
self-driving vehicle (SDV) and a set of dynamic objects from the catalog in
plausible locations in the scene. To produce realistic simulations, we develop
a novel simulator that captures both the power of physics-based and learning-based
simulation. We first utilize ray casting over the 3D scene and then use a deep
neural network to produce deviations from the physics-based simulation, producing
realistic LiDAR point clouds. We showcase LiDARsim's usefulness for perception
algorithms-testing on long-tail events and end-to-end closed-loop evaluation on
safety-critical scenarios.
|
|
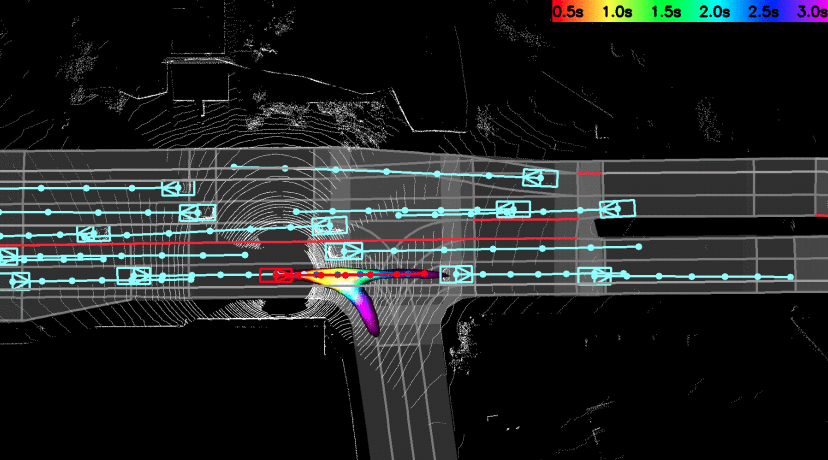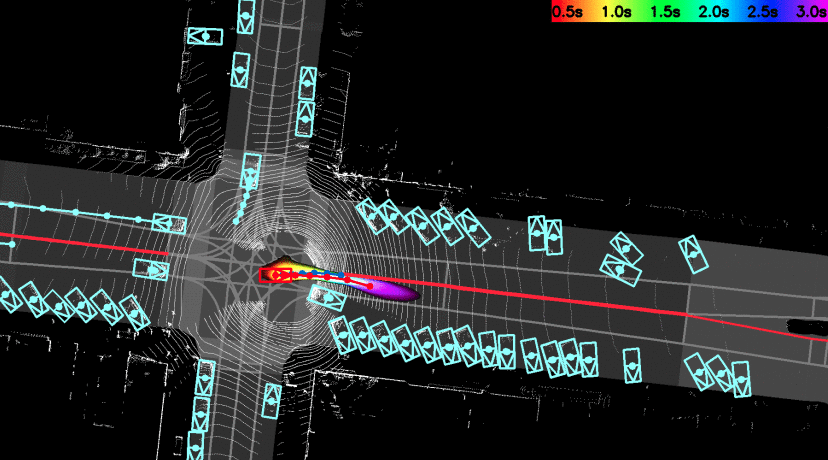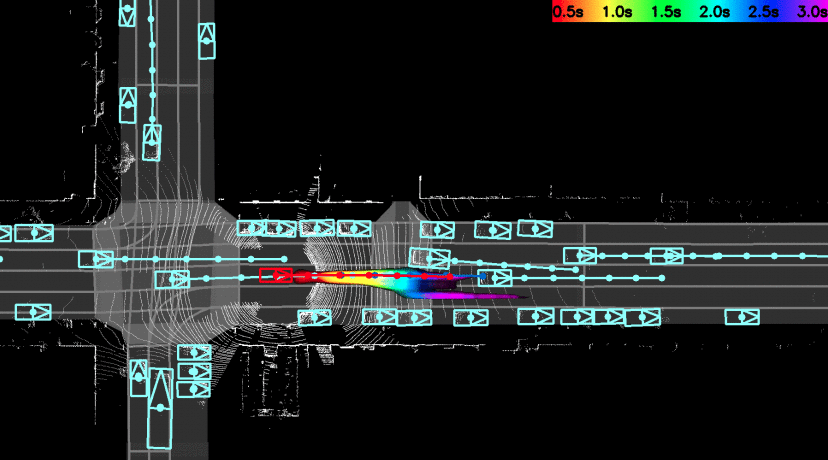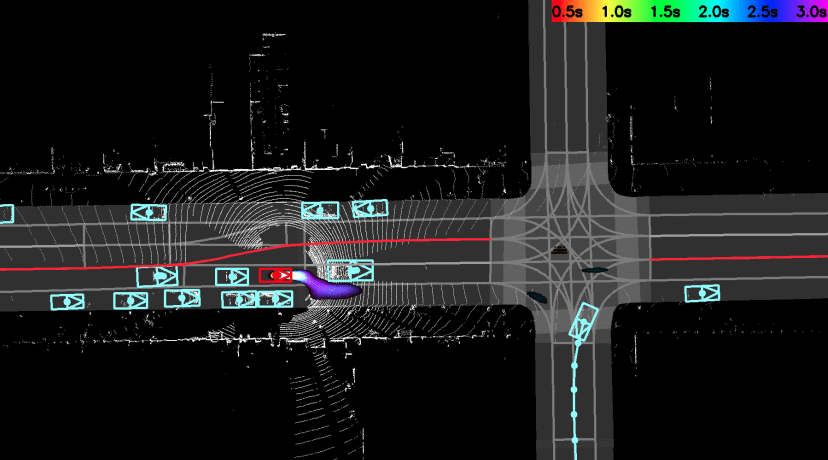
PnPNet: End-to-End Perception and Prediction with Tracking in the Loop
Ming
Liang*,
Bin Yang*,
Wenyuan Zeng,
Yun Chen,
Rui
Hu,
Sergio
Casas,
Raquel Urtasun
Computer Vision and Pattern Recognition
(CVPR), Seattle, 2020.
show abstract
/
paper
The first single neural network that solves
detection->tracking->prediction in an end-to-end manner.
We tackle the problem of joint perception and motion forecasting in the context of
self-driving vehicles. Towards this goal we propose PnPNet, an end-to-end model that takes as input
sequential sensor data, and outputs at each time step object tracks and their future trajectories. The
key component is a novel tracking module that generates object tracks online from detections and
exploits trajectory level features for motion forecasting. Specifically, the object tracks get updated
at each time step by solving both the data association problem and the trajectory estimation problem.
Importantly, the whole model is end-to-end trainable and benefits from joint optimization of all
tasks. We validate PnPNet on two large-scale driving datasets, and show significant improvements over
the state-of-the-art with better occlusion recovery and more accurate future prediction.
|
|
End-to-end Interpretable Neural Motion Planner
Wenyuan Zeng*,
Wenjie Luo*,
Simon Suo,
Abbas
Sadat,
Bin Yang,
Sergio
Casas,
Raquel Urtasun
Computer Vision and Pattern Recognition
(CVPR), Long Beach, 2019.
Oral Presentation
show abstract
/
paper
/
talk
End-to-end motion planner with interpretable intermediate
representations.
In this paper, we propose a neural motion planner for learning to drive autonomously in
complex urban scenarios that include traffic-light handling, yielding, and interactions
with multiple road-users. Towards this goal, we design a holistic model that takes as input
raw LIDAR data and a HD map and produces interpretable intermediate representations in the
form of 3D detections and their future trajectories, as well as a cost volume defining the
goodness of each position that the self-driving car can take within the planning horizon.
We then sample a set of diverse physically possible trajectories and choose the one with the
minimum learned cost. Importantly, our cost volume is able to naturally capture multi-modality.
We demonstrate the effectiveness of our approach in real-world driving data captured in
several cities in North America. Our experiments show that the learned cost volume can generate safer
planning than all the baselines.
|
|
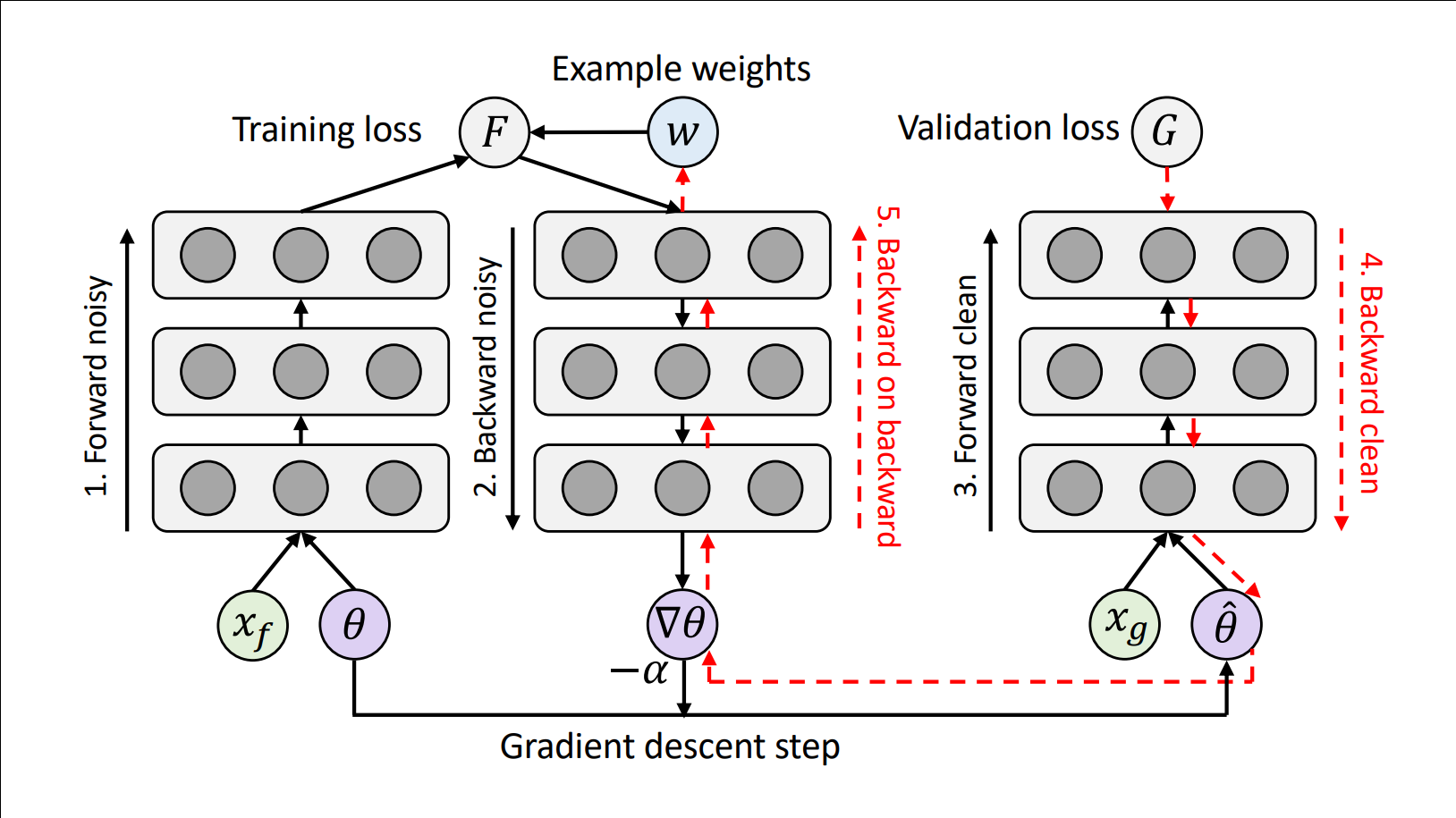
Learning to Reweight Examples for Robust Deep Learning
Mengye Ren,
Wenyuan Zeng,
Bin Yang,
Raquel Urtasun
International Conference on Machine Learning
(ICML), Stockholm, 2018.
show abstract
/
paper
/
talk
/
code
Learning to reweight training examples in an online manner
to overcome noisy or class-imblanced datasets.
Deep neural networks have been shown to be very powerful modeling tools for many
supervised learning tasks involving complex input patterns. However, they can also easily overfit to
training set biases and label noises. In addition to various regularizers, example reweighting
algorithms are popular solutions to these problems, but they require careful tuning of additional
hyperparameters, such as example mining schedules and regularization hyperparameters. In contrast to
past reweighting methods, which typically consist of functions of the cost value of each example, in
this work we propose a novel meta-learning algorithm that learns to assign weights to training
examples based on their gradient directions. To determine the example weights, our method performs a
meta gradient descent step on the current mini-batch example weights (which are initialized from zero)
to minimize the loss on a clean unbiased validation set. Our proposed method can be easily implemented
on any type of deep network, does not require any additional hyperparameter tuning, and achieves
impressive performance on class imbalance and corrupted label problems where only a small amount of
clean validation data is available.
|
|
Differentiable Compositional Kernel Learning for Gaussian Processes
Shengyang Sun,
Guodong Zhang,
Chaoqi Wang,
Wenyuan Zeng,
Jiaman Li,
Roger Grosse
International Conference on Machine Learning
(ICML), Stockholm, 2018.
show abstract
/
paper
/
talk
/
code
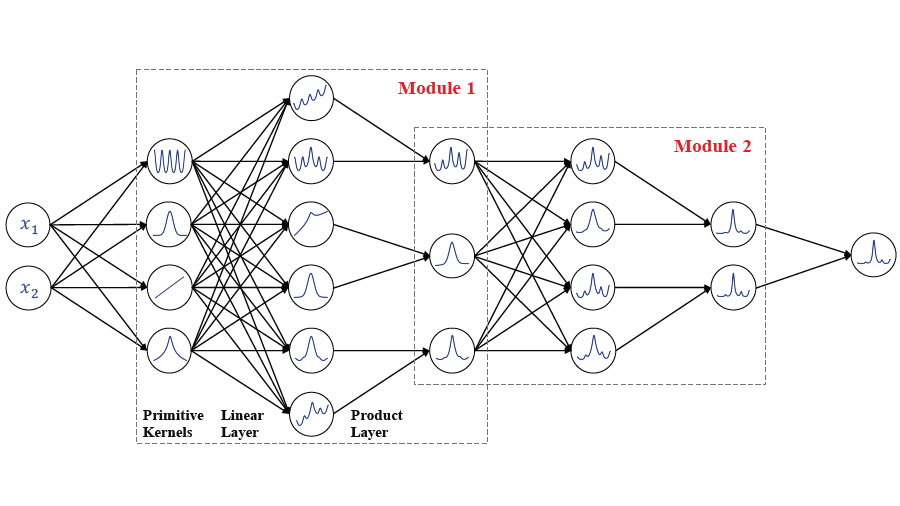
Neural Kernel Network (NKN), a flexible family of kernels represented
by a neural network.
The generalization properties of Gaussian processes depend heavily on the choice of kernel, and this
choice remains a dark art. We present the Neural Kernel Network (NKN), a flexible family of kernels
represented by a neural network. The NKN architecture is based on the composition rules for kernels,
so that each unit of the network corresponds to a valid kernel. It can compactly approximate
compositional kernel structures such as those used by the Automatic Statistician (Lloyd et al.,
2014), but because the architecture is differentiable, it is end-to-end trainable with
gradient-based optimization. We show that the NKN is universal for the class of stationary kernels.
Empirically we demonstrate pattern discovery and extrapolation abilities of NKN on several tasks
that depend crucially on identifying the underlying structure, including time series and texture
extrapolation, as well as Bayesian optimization.
|
|
Incorporating Relation Paths in Neural Relation Extraction
Wenyuan Zeng,
Yankai Lin,
Zhiyuan Liu,
Maosong Sun
Conference on Empirical Methods in Natural Language Processing
(EMNLP), Copenhagen, 2017.
show abstract
/
paper
/
code
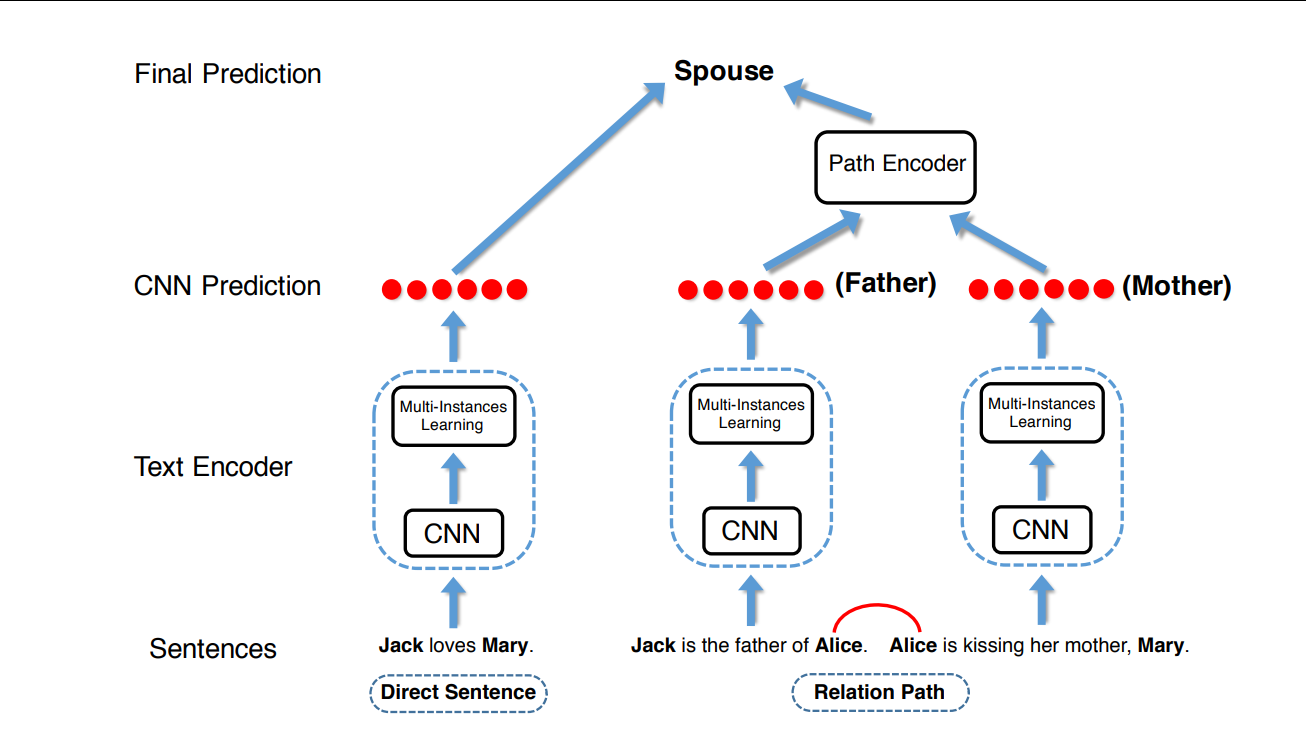
A path-based neural relation extractor which infers relations using
inference chains.
Distantly supervised relation extraction has been widely used to find novel relational facts from
plain text. To predict the relation between a pair of two target entities, existing methods solely
rely on those direct sentences containing both entities. In fact, there are also many sentences
containing only one of the target entities, which provide rich and useful information for relation
extraction. To address this issue, we build inference chains between two target entities via
intermediate entities, and propose a path-based neural relation extraction model to encode the
relational semantics from both direct sentences and inference chains. Experimental results on
real-world datasets show that, our model can make full use of those sentences containing only one
target entity, and achieves significant and consistent improvements on relation extraction as
compared with baselines.
|