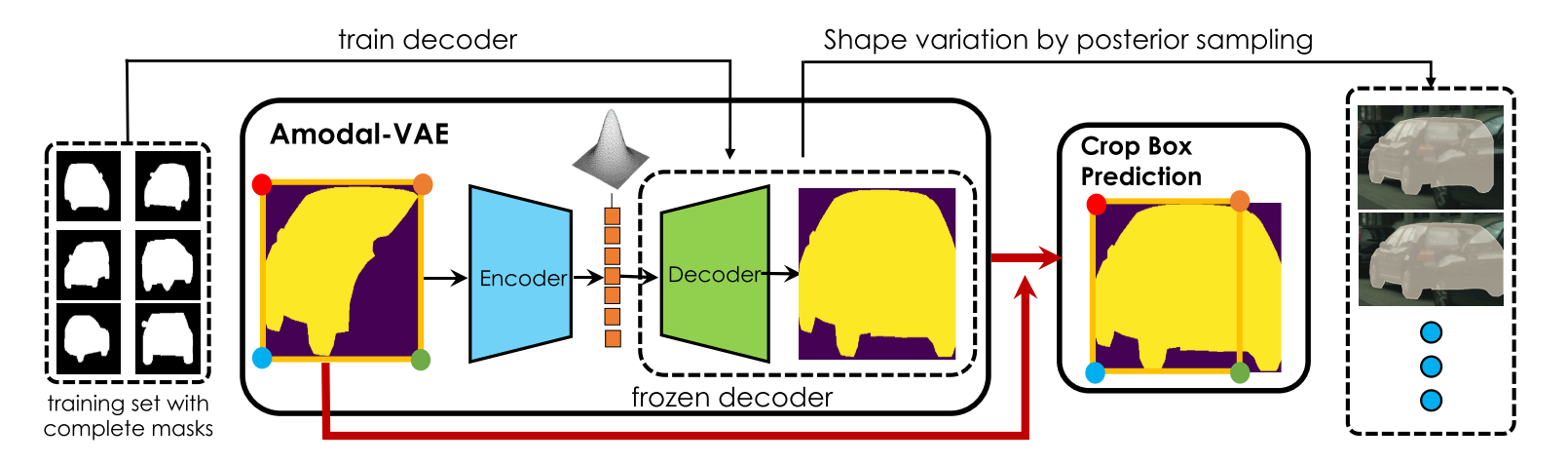
In images of complex scenes, objects are often occluding each other which makes perception tasks such as object detection and tracking, or robotic control tasks such as planning, challenging. To facilitate downstream tasks, it is thus important to reason about the full extent of objects, i.e., seeing behind occlusion, typically referred to as amodal instance completion. In this paper, we propose a variational generative framework for amodal completion, referred to as AMODAL-VAE, which does not require any amodal labels at training time, as it is able to utilize widely available object instance masks. We showcase our approach on the downstream task of scene editing where the user is presented with interactive tools to complete and erase objects in photographs. Experiments on complex street scenes demonstrate state-of-the-art performance in amodal mask completion and showcase high-quality scene editing results. Interestingly, a user study shows that humans prefer object completions inferred by our model to the human-labeled ones.
|