
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Constructing and animating humans is an important component for building virtual worlds in a wide variety of applications such as virtual reality or robotics testing in simulation. As there are exponentially many variations of humans with different shape, pose and clothing, it is critical to develop methods that can automatically reconstruct and animate humans at scale from real world data. Towards this goal, we represent the pedestrian's shape, pose and skinning weights as neural implicit functions that are directly learned from data. This representation enables us to handle a wide variety of different pedestrian shapes and poses without explicitly fitting a human parametric body model, allowing us to handle a wider range of human geometries and topologies. We demonstrate the effectiveness of our approach on various datasets and show that our reconstructions outperform existing state-of-the-art methods. Furthermore, our re-animation experiments show that we can generate 3D human animations at scale from a single RGB image (and/or an optional LiDAR sweep) as input. |
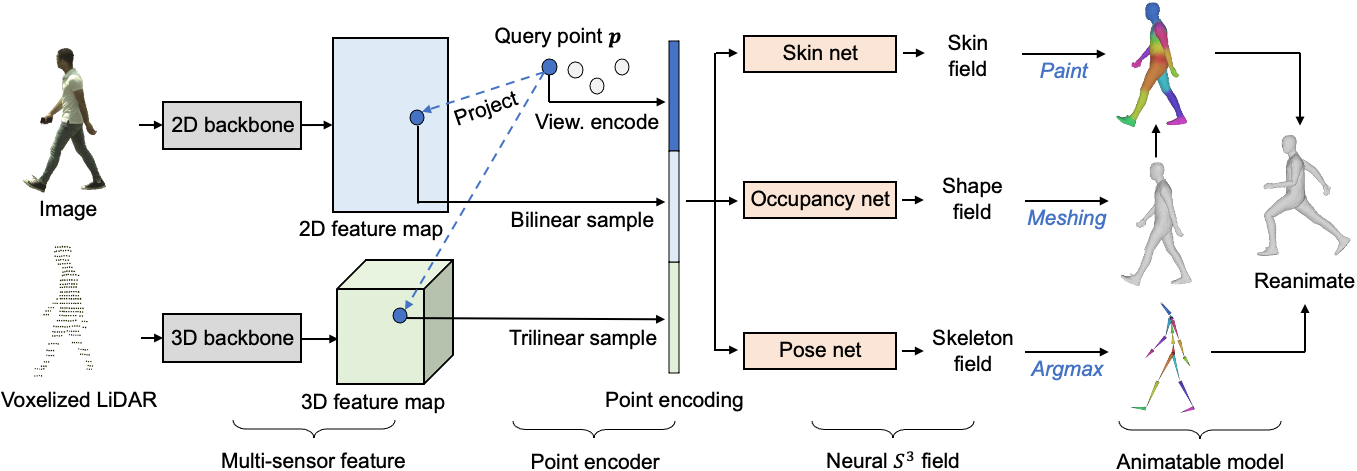 |
| We process input sensor data into spatial feature representations. We then query points adaptively from 3D space and extract their point encoding, which we use to query our neural implicit representations of shape, pose, and skinning. We apply post-processing to construct the final explicit representation of an animatable person. |
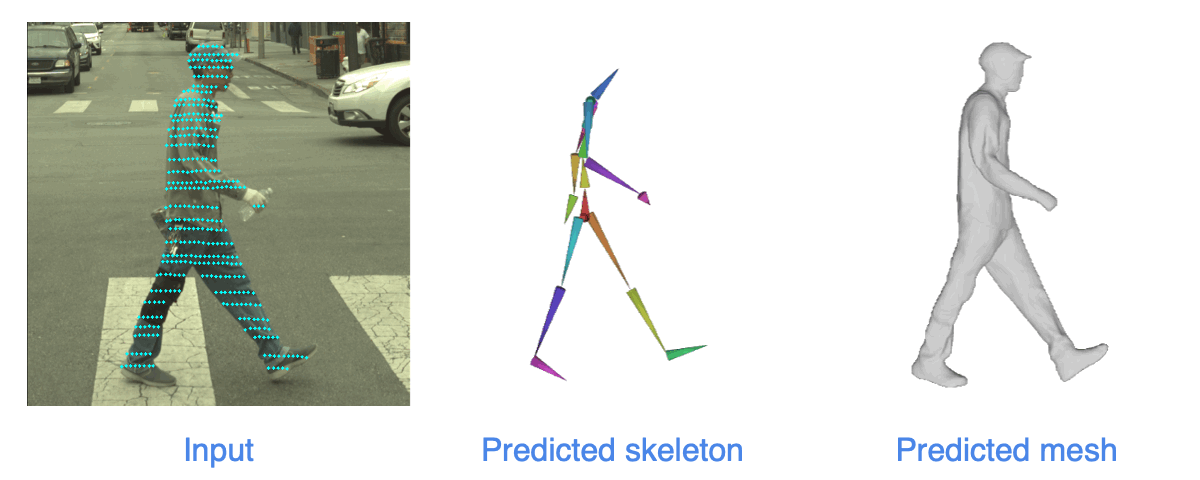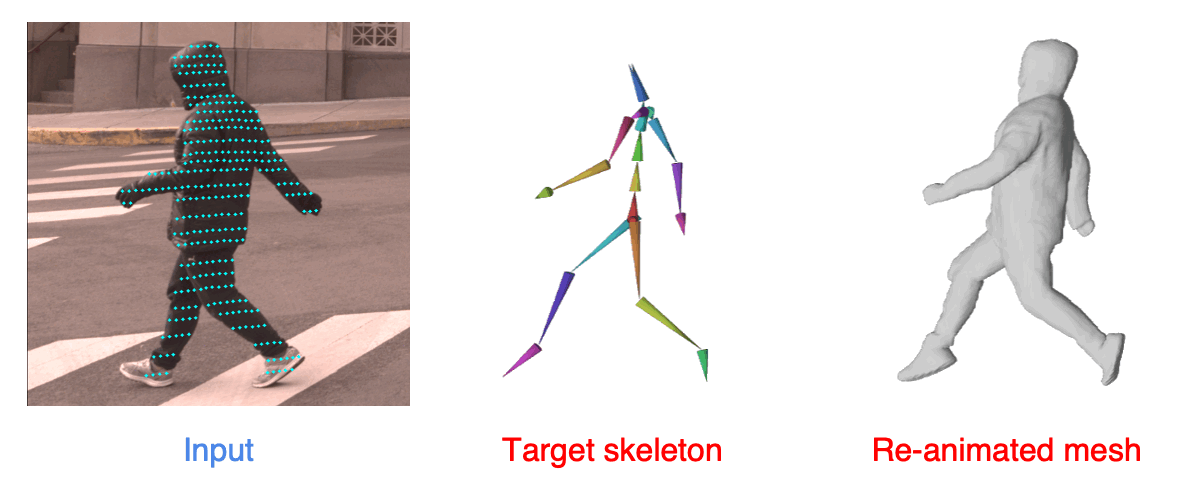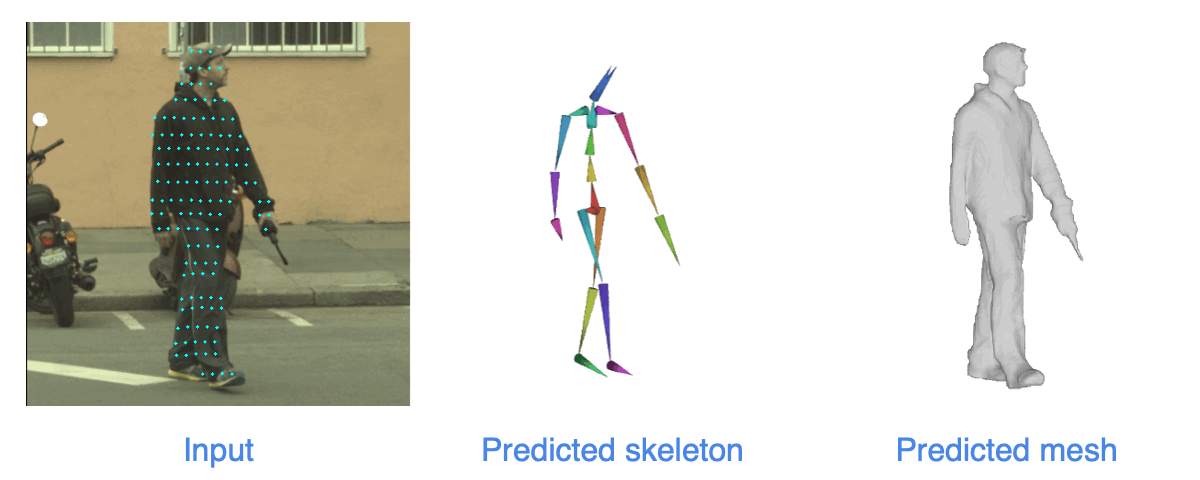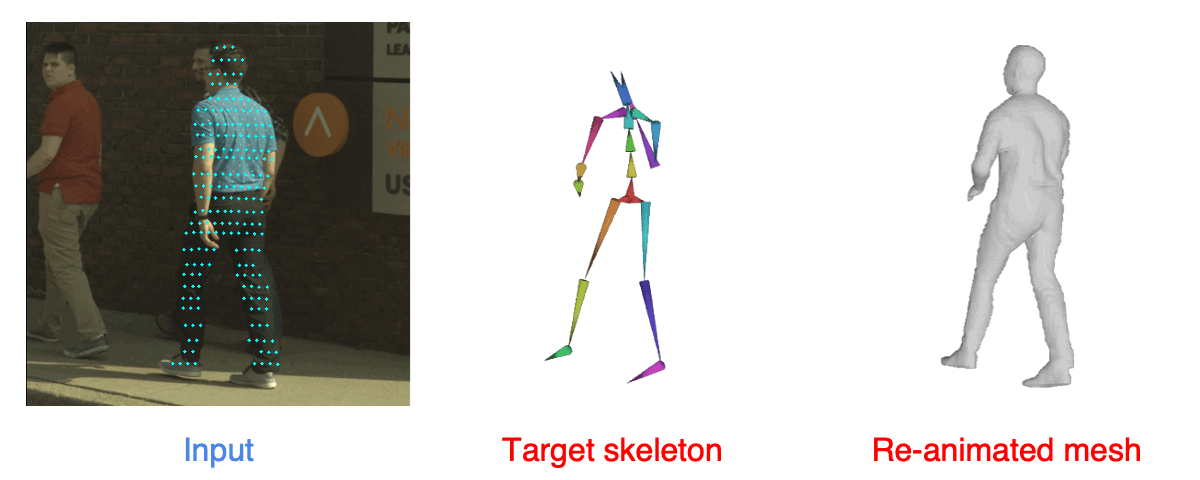 |
| Given an input camera image and a LiDAR scan captured in urban scenes, we reconstructs the shape and the animation model. We show the re-animated shape at a target pose. |