Hardware Sensitivity
- End-to-End Training
- FP32 Throughput
- Compute Utilization
- FP32 Utilization
- FP16 Throughput
- Hardware Specifications
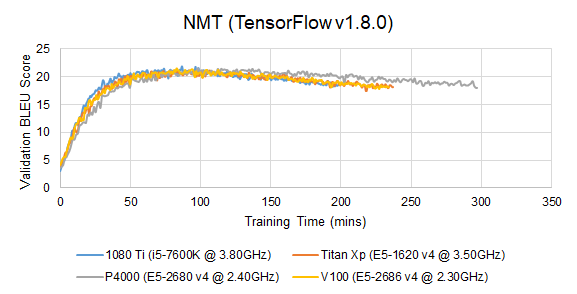
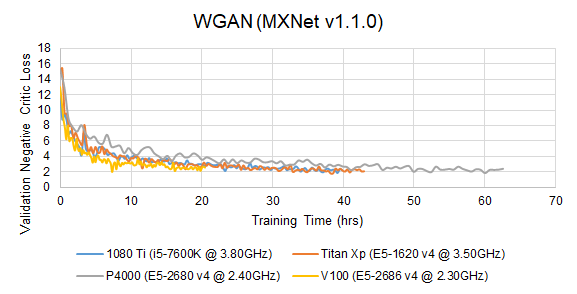
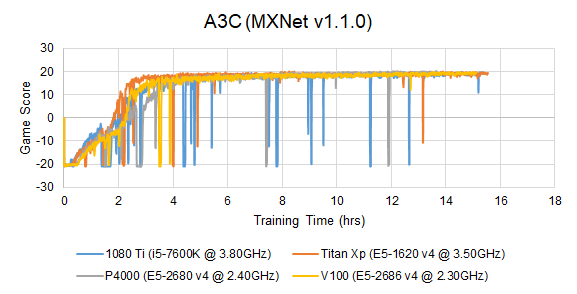
End-to-End Training
Before we proceed to actual profiling, we need to verify that the profiled implementation is able to produce the reported validation accuracy. However, training a DNN model to full completion is usually an extremely time-consuming job. Due to time and hardware resource constraints, we only so far produced training curves on the P4000, 1080 Ti, Titan Xp and V100-SXM2 architectures for some models. We will gradually add more training curves.