
Suppose our training set and test set are the same. Why would this be a problem?
Why is it necessary to have both a test set and a validation set?
Images are generally represented as
Write pseudocode to select the
Give an example of a training and a test set such that 3-nearest-neighbours and 5-nearest neighbours perform differently on the test set.
Consider the data plotted below. If all that you have to go by is the data below, how would you objectively determine whether 1-NN or 15-NN is the better classifier for the data?
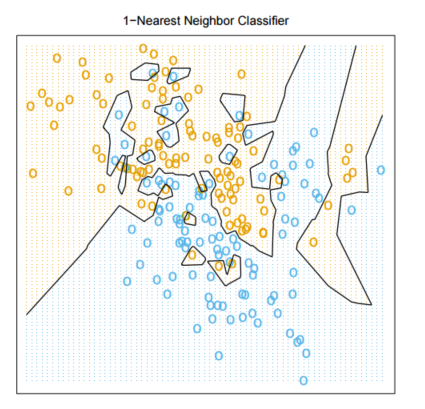
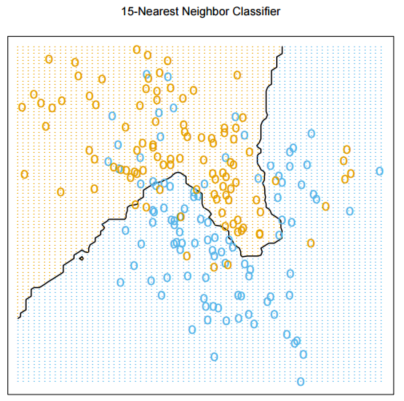
What is the performance of k-NN on the training set for k = 1? Is it the same for k = 3? (Give an example in your answer to the second question.)
What happens to the performance of k-NN if k is the same as the size of the training set?
Explain why the negative cosine distance may make more sense for comparing images than the Euclidean distance.
Give an example of a dataset where the Euclidean distance metric makes more sense than the negative cosine distance.
Explain how the quadratic cost function
is constructed. Specifically, what is the intuitive meaning of
How to estimate the best
How to estimate the best
Write a Python function to find a local minimum of
On a plot of a function of one variable
On a surface plot of a function of two variables, at point
With Gradient Descent, desribe functions for which a larger
Without computing the gradient symbolically, how can you estimate it? (Hint: generalize the technique we used for computing
Suppose
Explain how to use regression in order to solve two-classification problems. What’s the problem with using this approach for multi-class classification?
Describe a technique for using regression for multi-class classification problems.
Show that the code below computes the gradient with respect to the parameters of a linear hypothesis function
def df(x, y, theta):
x = vstack( (ones((1, x.shape[1])), x))
return -2*sum((y-dot(theta.T, x))*x, 1)
Write non-vectorized code to perform linear regression.
Explain how points that are not separable by a linear decision boundary using just the original features can become separable by a linear decision boundary if computed features are used.
When converting a classification problem into a regression problem, we assigned the output 1 Class A and the output 0 to Class B. We then predicted y = 1 for
Recall that we can find the Maximum Likelihood solution to linear regression problems using
paul_imgs
whose keys are
0..19
, and a dictionary
john_imgs
whose keys are
0..19
such that
paul_imgs[i]
and
john_imgs[i]
are the i-th image of Paul and John, respectively. The images are
True
if it’s likely a picture of Paul and False if it’s likely a picture of John. Use linear regression.
Explain why it makes sense to use Maximum Likelihood estimation.
Explain why it sometimes makes sense to use a prior on the parameter
Show that, for priors that are never zero, the more training data there is, the less important is the prior for Maximum A-Posteriori inference. Show that by writing down the posterior probability that is being maximized
Recall the following code. Explain why
theta_hat
will tend to have larger values (in terms of the absolute value than
theta
.
def compare_theta_theta_hat(N, ndim, sigma_theta, sigma):
theta = scipy.stats.norm.rvs(scale=sigma_theta,size=ndim+1)
x_raw = 100*(random.random((N, ndim))-.5)
x = hstack((ones((N, 1)),
x_raw,
))
y = dot(x, theta) + scipy.stats.norm.rvs(scale= sigma,size=N)
theta_hat = dot(linalg.pinv(dot(x.T, x)), dot(x.T, y))
return theta[1], theta_hat[1]
How would you use Bayesian inference in order to make it so that
theta_hat
is not systematically larger? Explan why your prior makes sense.
Show that minimizing the sum of squared differences between the prediction
Show how to compute AND using a neural network that uses logistic neurons.
Why can’t you use the log-loss when using linear neurons?
Assume that
Write Python code to find the Maximum Likelihood estimate for
After you find the Maximum Likelihood estimate for
Suppose that your model for the data is
with
Write vectorized code (i.e., you cannot use for-loops) to compute the output of a feedforward neural network with the activation function
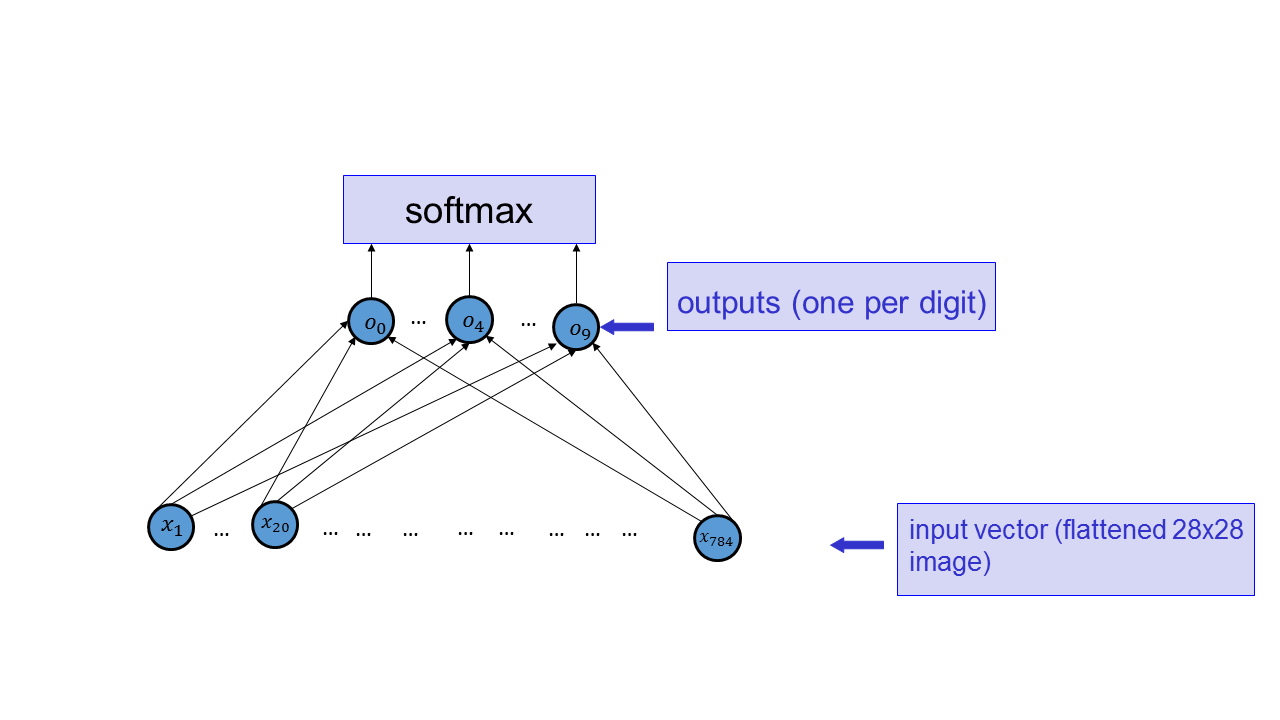
What is the disadvatange of using a single output when using feedforward neural networks for classification?
What is the disadvatange of using the quadratic cost function when using feedforward neural networks for classification, compared to the log-loss? When answering, consider how a single atypical example would influence the log-loss cost and the quadratic cost, and describe the consequence of that for our estimate of the network parameters
Consider solving a classification problem by specifying that for Class 1,
Suppose we are using multinomial logistic regression for a multiclass classification problem. What does the decision surface look like now? Explain the relationship between measure the distance of a point from a hyperplane and using multinomial logistic regression. Be precise. See here for how to compute the distance from a point to a plane.
Explain why the output of Softmax is better for representing probabilities than the raw output layer
What is one advantage of the
Explain what it means for a neuron to be dead. Why is that a bad thing? What is the implication for initializing the weights and biases for ReLU units?
Consider the network below
What would be the effect of applying the
Why is it useful to normalize the input data?
The learning curve here (Slide 3) is “wiggly.” How would you make it less wiggly?
Devise of an example of fitting a curve in 2D where a cubic polynomial would overfit, but a quadratic polynomial will work. In your example, sketch the points in the training and test sets and provide a cost function.
Suppose we modify our cost function as follows:
Why is adding the cubes of the weights to the cost function a bad idea?
Describe two different scenarios in which you would not observe overfitting.
Write code to generate a synthentic dataset for which the weights in a neural network on slide 7 here would look differently (approximately as described on slide 7) under L1 and L2 norm regularization.
Don’t you feel sorry for life science students who have to memorize the stuff about dendrites and axons?
How is the replicated feature approach related to the invariant feature approach?
On slide 5 here , you see a way of obtaining an image where points near horizontal edges are bright and everything else is dark, but this only works for edges that happen across a step of 2 pixels (or a little bit more). How would you produce an image that shows horizontal edges where the transition between one area and another is more gradual, and happens over, say, 10 pixels?
Explain Slide 15
here
: why is
Why to we sometimes pad the border of the image with zeros when performing convolutions?
Explain the difference between Max Pooling and Average Pooling. Write Python code that performs both.
When might you expect Max Pooling to work better than Average Pooling (and vice-verse)?
Give an example of a gradient computation when a network has a convolutional layer.
Give an example of a gradient computation when a network has a max-pooling layer.
Give an example of a gradient computation when a network has both a convolutional layer and a max-pooling layer.
Suppose the size of an input layer is
Why would we ever use
What is the idea behind the Inception module?
How many activation functions need to be computed if we are computing the first convolutional layer of a network which takes as input an
Suppose we want to visualize what a neuron in a ConvNet is doing. How would you go about that?
Sometimes when we visualize what a neuron is doing, we display an image that’s smaller than an input image. How is that done?
How is what the neurons are doing in the lower layers (near the input) different from what the neurons are doing in the upper layers?
Explain guided backpropagation. Provide pseudocode, and explain how guided backprop improves
on simply computing the gradient.
Explain the cost function for Neural Style Transfer, and explain how Neural Style Transfer works. Give the intuition for why the Gram Matrix is useful. Be specific about what’s being optimized and how.
Sketch how you would implement TensorFlow’s mechanism for computing gradients. (I.e., explain the idea behind automatic differentiation.)
Describe a situation where
Suppose you have training data where each data point contains information about whether the person tested positive for cancer and whether they actually have cancer. Write Python code to generate training data that was generated using the same process (i.e., same
Same question as above, but now the test result is a real number. You can use the fact that if the data is
In the spam classification example, specify what the Naive Bayes assumption entails, in non-technical terms. Give an example.
We have a test for a disease that can come out as either positive or negative. We know about each patient in the training set whether they have the disease or not. Write code to learn the parameters of the data, and to randomly generate more data that’s distributed similarly to the training data.
The previous question can be addressed directly, or using a generative classifier framework. Explain the difference in terms of the quantities (i.e. parameters) being estimated. (For example, in the generative classifier framework we do not estimate
Explain how to estimate
Suppose the outcome of a test is a real number. Explain how to train a generative Gaussian classifier in order to determine the probability that a patient has the disease. Justify all derivations.
See slide 10
here
. There are computational issues with trying to compute
Explain how to generate a figure such as the one on the first slide here .
What is the difference between supervised and unsupervised learning?
How might you use the results of running an unsupervised learning algorithm on a large dataset in order to train a classifier using a very small training set with labels?
Suppose the Covariance Matrix of a multivariate Gaussian is
Show that the
In the EM algorithm for learning a Mixture of Gaussians, during the E-step, we are estimating
In the EM algorithm for learning a Mixture of Gaussians, during the M-step, we are estimating
If we know the
Write code to generate data from a Mixture of Gaussians
When computing the total reward in RL, we usually use a discount factor
The average-value cost function in RL is
How is the policy
Explain how Policy Gradient learning can work by approximation the gradient using finite differences.
The Policy Gradient Theorem is:
Give an example of a probabilistic policy, and the gradient of its computation.
Explain the steps needed to get from the Policy Gradient Theorem to the REINFORCE algorithm.
Why does it make sense to use Convolutional Neural Networks to evaluate a Go position? Is there reason to think that a ConvNet would do a good job at evaluating for example poker hands?
Consider images that consist of n pixels. Explain why and how they can always be represented as the weighted sum of the n vetoctors that constitue the standard basis for
The goal of PCA is to find a small basis such that all the vectors in the training set can be approximately reconstructed using that basis. Write down the cost function that’s being minizined when performing PCA.
PCA is a form of unsupervised learning. One goal of unsupervised learning is computing interesting features from new input. What features can be computed using PCA?
Explain how to generate sentences if we have a way of computing
Explain the effect of
Draw a small Markov model for string generation, and explain how to compute the probabilities of strings using the model.
Draw a small RNN that can be run on strings, and point out all of its parameters.
What is the cost function that’s being opitmized when training an RNN?
Explain the vanishing gradient problem. Why is it a problem?
How can word2vec vectors be obtained from a training set?
Explain how to compute gradients in a small RNN. Use a concrete example of an RNN.
Draw the diagram of the sequence-to-sequence machine translation RNN we discussed. What is the cost function? How can it be computed?
Explain why we can say that the rightmost hidden layer in a machine translation RNN contains information about how to generate the translated sentence.
Explain how Beam Search Decoding can be used to generate a translation. Write pseudocode for Beam-Search Decoding.
Write pseudocode for Evolution Strategies for RL. What is the connection to gradient-based RL where the gradient is compute using finite difference approximation?
How is an autoencoder network trained?
What is an autoencoder network that produces the same results as PCA? Why does it produce the same results?
Why is full Bayesian inference infeasible for large neural networks?
Write the pseudocode for the Metropolis Algorithm
Annotate the Metropolis Algorithm implementation , explaining which parts of the algorithm correspond to which code.