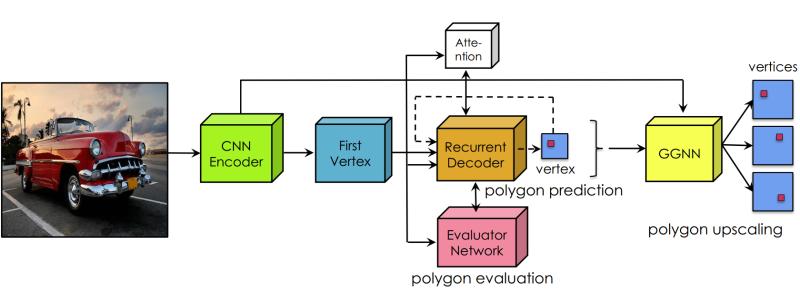
Manually labeling datasets with object masks is extremely time consuming. In this work, we follow the idea of PolygonRNN to produce polygonal annotations of objects interactively using humans-in-the-loop. We introduce several important improvements to the model: 1) we design a new CNN encoder architecture, 2) show how to effectively
train the model with Reinforcement Learning, and 3) significantly increase the output resolution using a Graph Neural
Network, allowing the model to accurately annotate highresolution objects in images. Extensive evaluation on the
Cityscapes dataset shows that our model, which we refer to as Polygon-RNN++, significantly outperforms the original model in both automatic (10% absolute and 16% relative
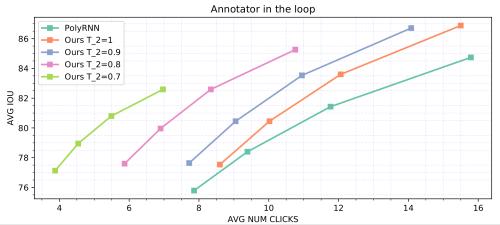
improvement in mean IoU) and interactive modes (requiring 50% fewer clicks by annotators). We further analyze the cross-domain scenario in which our model is trained on one
dataset, and used out of the box on datasets from varying domains. The results show that Polygon-RNN++ exhibits powerful generalization capabilities, achieving significant
improvements over existing pixel-wise methods. Using simple online fine-tuning we further achieve a high reduction in annotation time for new datasets, moving a step closer
towards an interactive annotation tool to be used in practice.
|