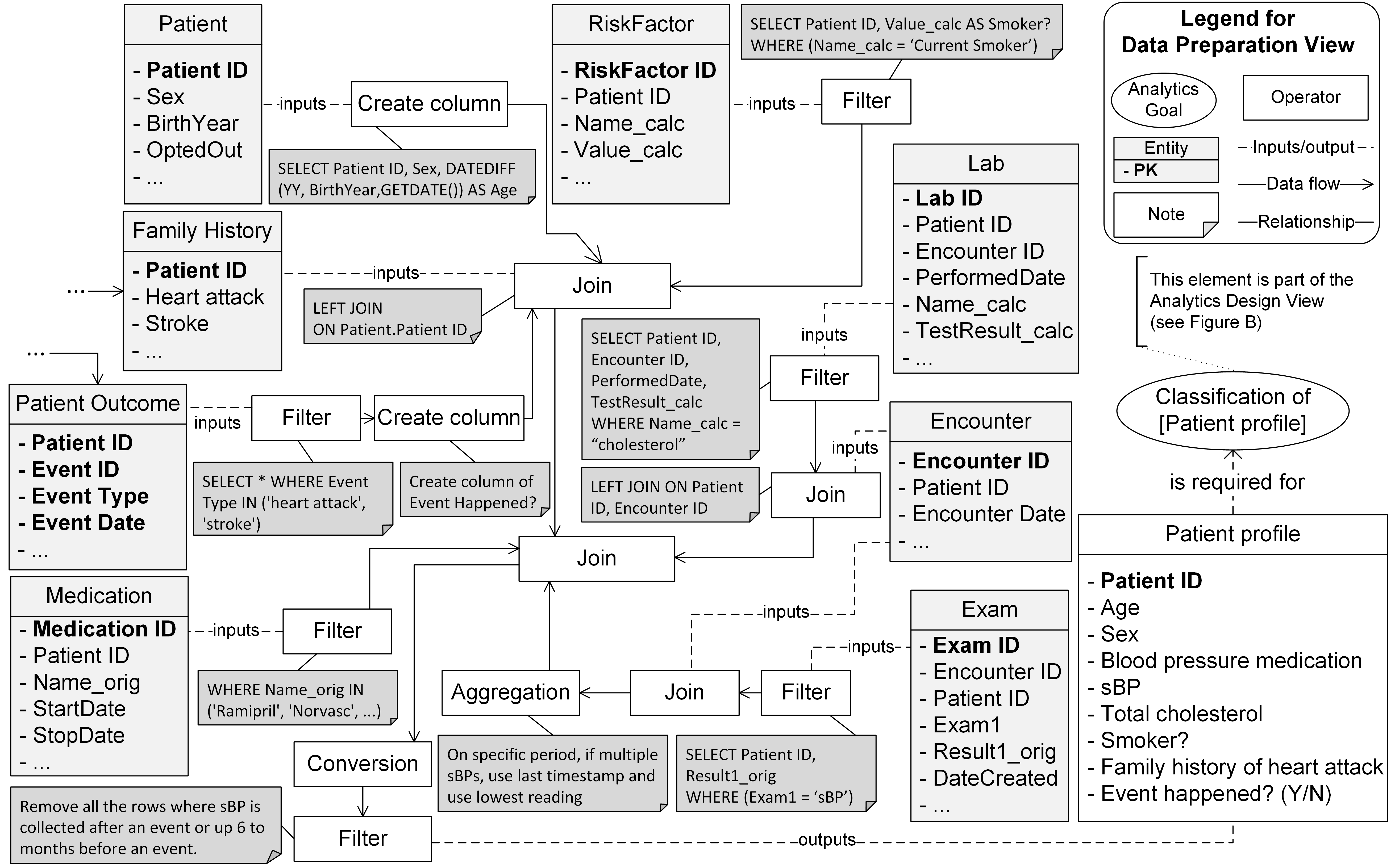
Step 3: Decide and design the flow of Data Preparation Tasks that transform the input data into prepared datasets
In this step, one identifies the sequence of integration, cleaning, aggregation, filtering and other data preparations that are needed for transforming the raw data tables into the prepared data tables. Findings from data understanding is a critical input to this step. Database administrators and data engineers and data scientists work together while taking into account data quality and treatment aspects. This includes decisions on how to deal with noise and outlier values, treat imbalanced dataset, address missing values, use sampling methods, derive and construct new attributes, change data types, among others. Data Preparation Catalogue provides techniques and algorithms for performing various data preprocessing tasks which can be referred to while performing this step.
Start by asking the following question to guide you: "What (sequence of) integration, cleaning, aggregation, filtering and other data preparations are needed for transforming the raw data tables into the prepared data tables?"
Ensure to take into account data quality and treatment aspects, including decisions on how to deal with noise and outlier values, treat imbalanced dataset, address missing values, use sampling methods, derive and construct new attributes, change data types, among others.
Step 1 Step 2 Step 3 ‹ ›