| Mathematics of Information Technology and Complex Systems |
| |
|||||
| |
|
||||
|
Research Our research focuses on the relationships between models of software behaviour. We are developing an appropriate theory that will allow us to compose models of individual components, and to reason about the relationship between different versions of a composed model. Our starting point is to observe that given a set of partial models of a system, expressed for instance as state machine models, we can imagine a number of different relationships between the behaviors they describe:
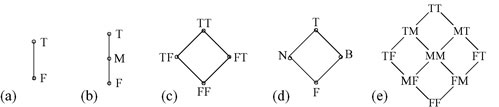
Combinations of these are also possible: versions of parallel devices; projections of a feature; and so on. To permit flexibility for composing and evolving such models, we use an underlying formalism that supports the explicit representation of uncertainty and disagreement. This basis is provided by a body of work on multi-valued model checking [2,4,13]. Our basic modeling approach is based on a class of multi-valued, quasi-boolean logics whose truth-values form finite lattices. We have used these logics to develop a modeling scheme based on multi-valued Kripke structures, in which transitions between states, and values of propositions within states, range over the truth values of a quasi-boolean logic. Below, we will introduce this modeling scheme briefly and then sketch some of its applications. We then present the central ideas that we plan to use for the proposed research on composition. The key insight for this proposal is that two different (partial) orders can be induced on the lattices that underlie our logics [8]. The first is a truth order, used to define the logic operations. The second is an information order, used to reason about elaborations that reduce uncertainty in an evolving model. We will use this observation to define a suitable refinement relation on our models, and to construct a category theoretic approach to composition. In the remainder of this section, we will briefly explain each of these ideas. We use quasi-boolean algebras [17] to provide a basis for our multi-valued
reasoning. These are a class of algebras based on finite distributive
lattices, where the elements of the lattice are taken as the truth values
for our logics, and the lattice partial order is the truth ordering.
We adopt the convention that T in the lattice means ‘True’,
and
Fig 1: Some example quasi-boolean logics. Note that (c) is a product lattice of two 2-valued lattices. (d) is Belnap's logic, in which B means both true and false, and N means neither. (e) is a product of two 3-valued lattices. We use these structures to give a multi-valued semantics
to existing, well-known (2-valued) logics used in software verification.
For example, we have extended the temporal logic CTL to provide us with
a family of multi-valued variants, which we call We have identified a number of interesting applications of this form of multi-valued reasoning:
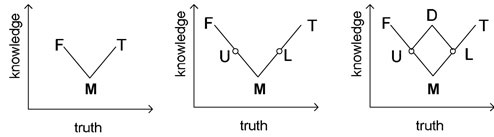
To build large structured models of software behaviour, we need to compose models of the behaviour of individual components. Note however, that our notion of a component is more general than that typically used in the software engineering literature. For example, in the software architecture literature, components are normally taken to be units of the implemented program, based on its static structure [14]. In this literature, it is assumed that interaction between components is restricted to some form of communication across a shared interface. Rather, we are more interested in components as fragments of a model, where each component represents an aspect or slice of the overall behaviour of the software. For example, our components may represent features to be added to some base system, or proposed modifications to be made to an existing system. Components may modify, restrict or even contradict the behavioural descriptions of other components. We model the behaviour of each component using a multi-valued state machine model, based on a particular quasi-boolean algebra. For example, if the component contains uncertainty, we may use the 3-valued logic of Figure 1(b). When we compose components, there will be some overlap in the phenomena described by each model. For example, some of the states may be shared, and some of the variables may be common to several components. Most interestingly, the components may disagree over the truth values of some phenomena. For example, the same transition between two states may be labeled T in one component, meaning it is permitted, and labeled F in another, meaning it is not permitted. Our product lattices (Figure 1c, 1e) allow us to explicitly capture this disagreement in the composed system. To define a suitable theory of composition, we adapt existing work on the use of category theory as a foundation for building structured specifications [6]. Category theory provides an ideal vehicle for reasoning about composition, because it explicitly focuses on structure, and provides a series of constructs for composing and transforming structures. For example, Fiadiero and Maibaum [7] describe the category in which the objects are temporal logic specifications, and the morphisms are refinements between specifications. Their approach explicitly handles differences in vocabulary between specifications, as a specification morphism combines a signature map and a specification map. The composition of a set of specifications is computed as their colimit. If there is some overlap in the phenomena described in the two specifications, we first create an interconnection diagram by declaring the shared phenomena in a separate specification, constructing a morphism from this to each of the original specifications, showing how the shared phenomena is refined in each specification. The composition is then the colimit of this diagram (in the simplest case, if we are composing two specifications, this is simply a pushout). The intuition behind colimits is that they glue things together with nothing essentially new added, and nothing left over. Category theory is attractive as a foundation for this work for a number of reasons. It provides a rich body of theory for reasoning about structured objects and the relations between them (in this case, software models and their interconnections). It is sufficiently abstract that it can be applied to a wide range of different modeling languages. It lends itself well to automation, because all the categorical operations we need have constructive definitions. Finally, we have found the concepts of category theory elegant as a way of conceptualizing the problem of composition, and as an appropriate terminology for the composition operations. The drawback to category theory is that, as an abstract branch of mathematics, it is even further removed from practical software engineering than most formal specification techniques. Our philosophy is to hide as much as possible of the underlying theory from the user, whilst providing an environment for composing models, and reasoning about the resulting structures. Taking our inspiration from the work on categories of algebraic [6] and temporal logic [7] specifications, we define a category of multi-valued state machine models, in which the morphisms are refinement relations between models. Our first problem is to identify a suitable refinement relation. Refinement, which can be thought of as correctness-preserving elaboration, has been studied widely in the program synthesis and program verification communities. Intuitively, refinement is the relationship that should hold between a specification and the program that implements that specification. More precisely, refinement is a preorder over specifications, where x refines y is taken to mean that x implements some of the behaviours of y, or alternatively, that the behaviours of x can be simulated by y. For any given modeling formalism, the question of how to choose an appropriate mathematical definition of the refinement relation is not always clear. For our work, we need to consider two different cases: refinement between two models based on the same underlying quasi-boolean lattices, and refinement between models based on different lattices. For the former, we make use of the idea of a knowledge order over the truth values. For the latter, we expect to be able to describe a refinement if the partial order of one lattice can be embedded in the partial order of the other. The idea of a knowledge order in multi-valued logics is an insight first described by Belnap [1], and later generalized in the concept of bilattices [10][9]. The insight is that there may be two separate partial orders on the truth values of our logics, which can be used for different purposes. The first is the truth ordering, and was used above in our account of quasi-boolean algebras. The second partial order is the knowledge order, in which we view ‘Maybe’ as containing less information than ‘True’ or ‘False’. For example, in Belnap’s logic, shown in figure 1(c), the truth order goes from bottom to top, and the knowledge order goes from left to right. In this reading, the value B (“Both true and false”) is treated as the situation where we have too much knowledge. Belnap’s logic is the simplest of the bilattices – structures for which both orders form a lattice. For our purposes, the truth order must be a lattice, to ensure a well-defined reasoning system, but we do not require the knowledge order be a lattice. Therefore we do not restrict ourselves just to bilattices. Figure 2 gives some examples showing both orders. We plan to use this insight to adapt classical notions of refinement in the following way. For classical, 2-valued state machines, refinement is normally defined as a simulation relation. Model B refines (or implements) model A, if A simulates B. The set of behaviours of B is a subset of those of A, so that every behaviour of B is permitted by A, and B is not capable of any behaviour that is not permitted by A. However, we usually want refinement to allow B to be a lower level of abstraction, so that several states in B may correspond to a single state in A. Hence, the simulation should be insensitive to stuttering (finite repetition of states in a trace). We adapt this to the multi-valued case by allowing the refinement to include a reduction in the uncertainty for any values, i.e. a move upwards in the knowledge order. This corresponds to the intuition that if a specification leaves some values unknown, a refinement of that specification is free to choose which values to use (but cannot introduce more uncertainty). For example, imagine we want to express a model, S, that has two different types of behavior (‘guaranteed’ and ‘admissible’). We can model these two types of behavior using a 3-valued logic (Figure 2a) where T represents the guaranteed behaviors and the set {M, T} represents the admissible behaviors. A 2-valued (classical) model I implements S if the set of guaranteed behaviors of S is a subset of the set of behaviors of I, and the set of behaviors of I is a subset of the set of admissible behaviors of S. Figure 2: Truth order vs. knowledge order. Intuitively, the truth values can be read as: False, Maybe, True, Unlikely, Likely, and Disputed. With a suitable definition of refinement, we expect to be able to define a category of multi-valued models, and use colimit in this category to construct compositions. We have proposed the category of fuzzy viewpoints as a suitable basis for this investigation. Informally, a fuzzy viewpoint is a graph in which the details of nodes and edges are annotated with the elements of a lattice to specify the amount of knowledge available about them. Effectively, this embeds the notion of uncertainty and incompleteness into the underlying structure of graphs, and provides an algebraic characterization of this embedding. The notion of a fuzzy viewpoint is very general, and can be applied to any of the large number of graph-based notations used in software engineering. In particular, it can be applied to the multi-valued state machine models we used in our earlier work on multi-valued model checking, to account for the syntactic aspects of incompleteness and inconsistency. The category of fuzzy viewpoints is constructed by combining the category
of fuzzy sets [11] with the category of graphs and graph homomorphisms.
Fuzzy set theory is a generalization of classical set theory, in which
elements of a set can have variable degrees of membership. In the general
case, the degrees of membership are drawn from a partial order; in our
case we will restrict these to the lattices we introduced above. We
also make use of the observation that the category of graphs is isomorphic
to a comma category [12]. A comma category is constructed from two categories,
A and B, with functors from each of these into a third category C. In
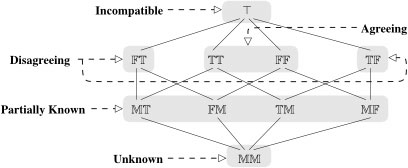
the comma category, each object is a triple <a, Our initial investigations suggest that the category of fuzzy viewpoints gives us precisely the foundation we need for composing multi-valued models . It allows us to merge inconsistent and incomplete models, and reason about the resulting composition. The framework allows us to work with different lattices for different types of analysis. For example, we demonstrate an application that uses the lattice A10 (see figure 3) to reason about the syntactic consistency of the composition of a pair of 3-valued models. This lattice allows us to label the syntactic elements of the composed model with items that the sources agree or disagree on. It also allows us to distinguish between disagreements (where the sources have different values assigned to common elements of their models) and incompatibilities, which arise if the chosen composition attempts to unify elements of the source models in such a way that we cannot consistently label them with any other single value from A10. If we resolve any incompatibilities, the remaining 9-valued semi-lattice can be used with the truth ordering of figure 1(e) for automated reasoning (e.g. model checking) of properties of the composed model.
Figure 3: The Lattice A10 Having explored some of the basic ideas, we plan to continue to develop this framework and explore its use to support compositional modeling for software engineering. The funding requested for this seed project will allow us to explore the utility the mathematical foundations we have described above, and to apply these ideas to several simple case studies to explore their applicability. The result should be a proof of concept – a demonstration that the ideas we have described can be used to support useful types of compositional modeling for reactive systems. References
|