Automatic Code Clone Detection and Clone Pairs Harmfulness Ranking System
Chenguang Zhu, Kechao Wang, Tiantian Wang, and Xiaohong Su
Code clone is the duplication of similar code in a codebase. Code clones originate as outcomes of activities such as the copying and pasting of code, code generation by a code generator, and the use of a specific coding style.
Code clones contribute to the high maintenance cost of software. This is because if a defect is found in one of the clones, then all relative clones must be inspected and updated one-by-one with the necessary corrections. The costs of these fixes increase with software size. A software module with a lot of code clones usually incurs high maintenance cost.
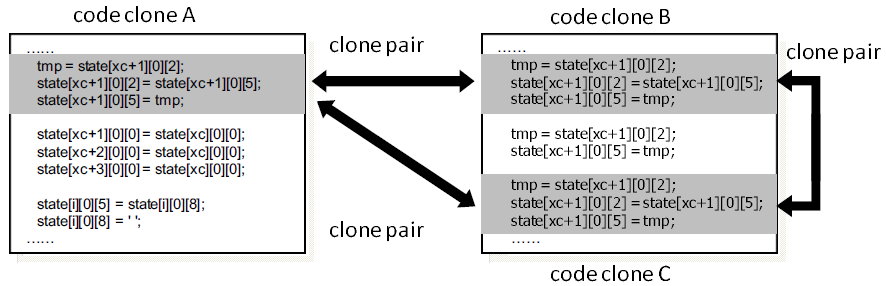
Fig. 1. Clone pairs.
We implemented a code clone detection technique, which combines token-based clone detection algorithms and frequent subsequence mining algorithm to detect basic-block level clone pairs. The algorithm was proposed by Z. Li et al. [1] in their CP-Miner paper. The algorithm firstly converts source code to token sequences, then performs hash operations on the token sequences to obtain number sequences, then divides the sequences into multiple segments based on the boundaries of basic blocks to obtain a sequence database. At last, it applies CloSpan mining algorithm to match the copy-pasted pairs.
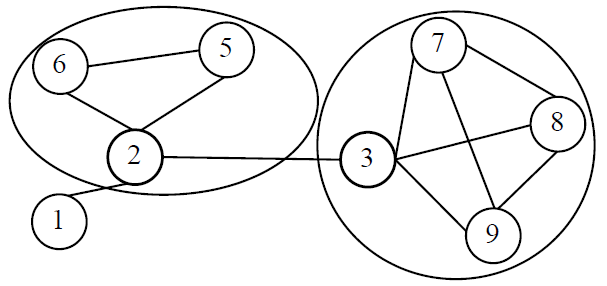
Fig. 2. The graph of the relationship of clone sets locations.
Since not all code clones are equally detrimental to the software maintenance. It is critical to identify the actual harmful clone sets. We proposed an algorithm for ranking the harmfulness levels of clone sets. Inspired by the work of Y. Fukushima et al. [2], we designed and implemented an algorithm that ranks the harmfulness levels of clone pairs. We model the relationship of locations of clone pairs as an undirected graph. Each node represents a clone set. An edge connecting node A and B represents the fact that we can find some clone segments, both from clone sets A and B, in the same subsystem. Based on the undirected graph we obtained, we calculate betweenness centrality metrics for each node, a clone set that has higher betweenness centrality receives a higher rank. From the graph, we are able to tell which clone sets are critical to software maintenance, and pay more attentions to them.
References:
[1] Z. Li, S. Lu, S. Myagmar, and Y. Zhou, "CP-Miner: A tool for finding copy-paste and related bugs in operating system code," in Proceeding of the 2004 symposium on operating systems design and implementation, OSDI 2004.
[2] Y. Fukushima, R. Kula, S. Kawaguchi, K. Fushida, M. Nagura, and H. Iida, "Code clone graph metrics for detecting diffused code clones," in Proceeding of the 16th Asia-Pacific software engineering conference, APSEC 2009.
Github repository: LINK
Related Publications:
Research on Code Clone Analysis Approach. (Chinese)
Kechao Wang, Chenguang Zhu, Tiantian Wang and Xiaohong Su.
Application Research of Computers, 2016 (Chinese).