Hardware Sensitivity
- End-to-End Training
- FP32 Throughput
- Compute Utilization
- FP32 Utilization
- FP16 Throughput
- Hardware Specifications
FP32 Throughput Comparison
We show the throughput results on different GPU architectures, including the latest Pascal & Volta generations. Unlike the baseline analysis on P4000, we use a fixed mini-batch size for each benchmark. All benchmarks are trained with single-precision floating point.
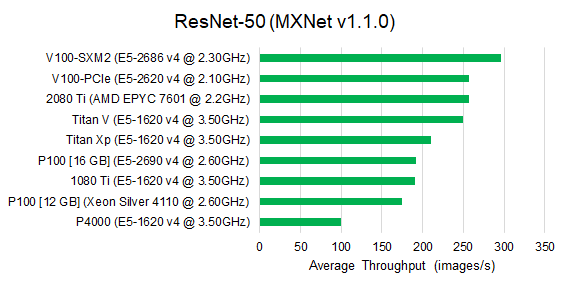
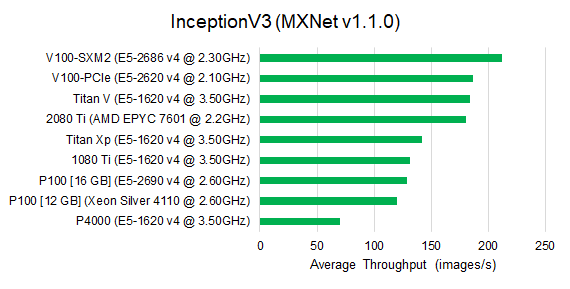
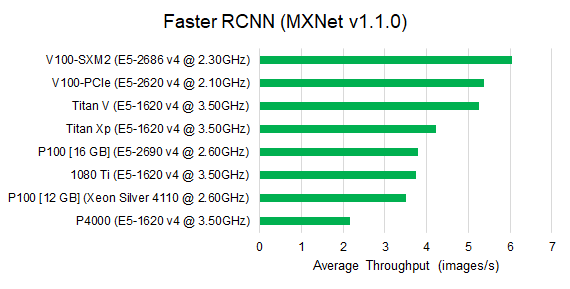
Observe that for image classification benchmarks, V100-SXM2 outperforms all other GPU architectures. The second tier includes the V100-PCIe, 2080 Ti and Titan V. Their performance is roughly 15% slower than V100-SXM2. The Pascal architectures deliver similar performance compared to 1080 Ti, which is slightly (10%) less than Titan Xp. We observed similar performance tiers for the Faster RCNN benchmark, since Faster RCNN uses an image classification model as its base model.
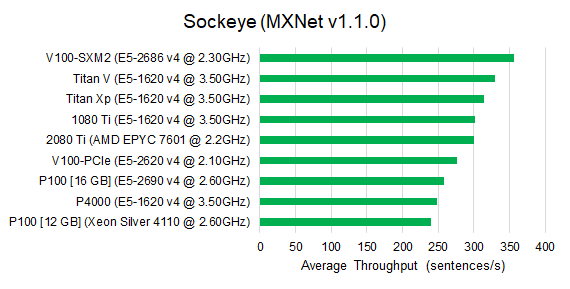
For the seq2seq model, The V100 architectures are still able to deliver the best training speed. However for the sockeye implementation, V100-PCIe is only faster than P100 and Quadro P4000, and Titan Xp and 1080 Ti are much more competative. For the NMT benchmark, the V100-PCIe architecture is slightly faster than V100-SXM2.
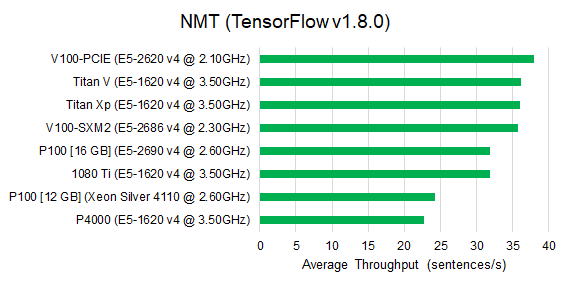
For the transformer model, the performance tiers are the same as image classification models. The only difference is that the Titan Xp, 1080 Ti, P100 and P4000 are much slower (roughly 50%) than others, while for image classification, they are around 30% slower.
The A3C model uses a relatively shallow CNN network as its base model. In this case, the V100 architectures are not able to outperform other architectures.
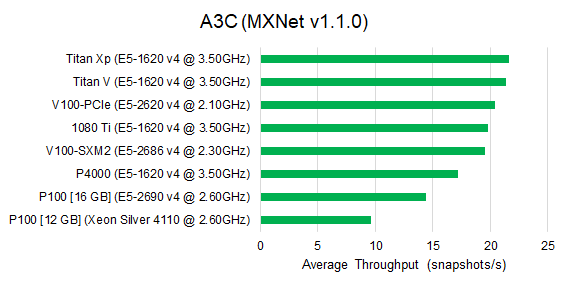
In general, we conclude that the V100 architectures deliver the best DNN training performance. The Titan V and 2080 Ti architectures are equally fast and competative (only 15% slower than V100 on average). Titan Xp is slightly (10%) faster than 1080 Ti, but slower than Titan V and 2080 Ti. The P100 architectures are much slower than others and only faster than our baseline Quadro P4000.