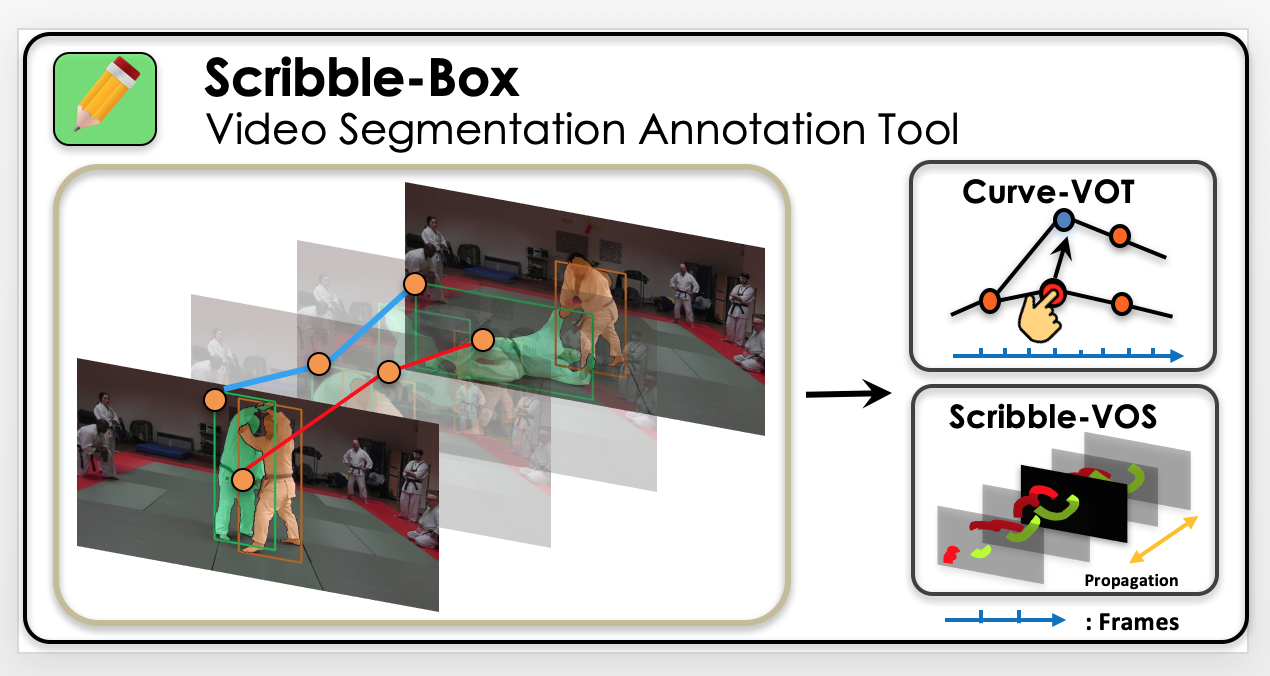
Manually labeling video datasets for segmentation tasks is extremely time consuming. In this paper, we introduce ScribbleBox, a novel interactive framework for annotating object instances with masks in videos. In particular, we split annotation into two steps: annotating objects with tracked boxes, and labeling masks inside these tracks. We introduce automation and interaction in both steps. Box tracks are annotated efficiently by approximating the trajectory using a parametric curve with a small number of control points which the annotator can interactively correct. Our approach tolerates a modest amount of noise in the box placements, thus typically only a few clicks are needed to annotate tracked boxes to a sufficient accuracy. Segmentation masks are corrected via scribbles which are efficiently propagated through time. We show significant performance gains in annotation efficiency over past work. We show that our ScribbleBox approach reaches 88.92% J&F on DAVIS2017 with 9.14 clicks per box track, and 4 frames of scribble annotation.
|