My research spans several areas of vision research with common threads connecting the different topics. I study the perception of shape, both 2D shapes and 3D surfaces, and saccadic eye movements. I have a background in both Psychology (Ph.D.) and Computer Science (M.S.), and my work in both areas has involved computational modeling and psychophysics. In all the areas of my research one of the goals has been uncovering what information is available to the observer, how that information is represented (frequently looking at whether the local or global information is encoded), and whether or not the representation used can be flexible and change with changing task demands.
I am currently working as a Postdoctoral Fellow in Computer Science under the direction of Prof. Sven Dickinson. We are investigating using the junctions of superpixels to improve image segmentation and the interpretation of the figure/ground organization of the scene.
My previous postdoctoral position was in the lab of Prof. Richard Murray. I studied how the human visual system represents scene lighting information and how the visual system interprets shape from shading. Most models of shape from shading make a global lighting assumption, using a single fixed light source. Our work suggests that the human visual system does not make a global lighting direction assumption. Instead lighting direction is represented locally, and the area of the local estimate is related to the frequency of shape changes. The most surprising result of the project is that observers cannot always consciously report the local lighting direction, but their visual system still uses the appropriate local lighting information when interpreting the shape of an object. Subjects were shown a surface where one quadrant was lit from one lighting direction and the other 3 quadrants were lit from a lighting direction with a difference in tilt of 90 degrees. Subjects were unable to identify the oddly lit region, even though estimations of shape from shading were just as accurate in the odd region as in the consistently lit regions. This result suggests that the visual system uses the appropriate local lighting information when estimating shape from shading even when that information is not reportable by the subjects.

Example stimulus where 1 quadrant is lit from one direction and the remaining quadrants are lit from a different direction. The oddly lit region does not pop out. In this image the odd region is the top right.
I have collaborated with Prof. James Elder and Dr. Ingo Fründ to investigate 2D shape preception, and develop a classification image paradigm for that can be used to efficiently probe the internal representation used by the human visual system. In these experiments subjects classified a shape into one of two categories. We designed the experiment in such a way that in a discrimination task all frequencies of the shape were equally useful, but the data showed that humans were unable to make use of high frequency shape information. Our estimated classification images were better predictors of human performance than making an assumption that humans perform as the ideal observer with internal noise, suggesting that humans pay more attention to the more global structure of a shape than to the fine details when performing our task, even though all frequencies had the same amount of information. This is consistent with my other shape work, stressing the importance of global and regional representations.
I earned my PhD working in the Visual Cognition Lab under the direction of Dr. Jacob Feldman
Many of my projects focus on investigating whether visual representations encode local/detailed information or global information. In Wilder, Feldman, and Singh (2011), we created a model for shape classification that could accurately predict a human’s classification of a novel shape. Using a skeletal representation of shapes (Feldman & Singh, 2006) we created a naïve Bayesian classifier for leaves and animals. By morphing together animals and leaves we created novel shapes. These novel shapes were presented to both human observers and the classifier. The classifications made by the human observers could be accurately predicted by the naïve Bayesian classifier. This shows that a skeletal representation contains the necessary information for accurate classification, possibly due to the skeletal representation capturing relevant information about part structure, and that classifiers based upon the shape skeleton can be tuned to the statistics of natural shapes.
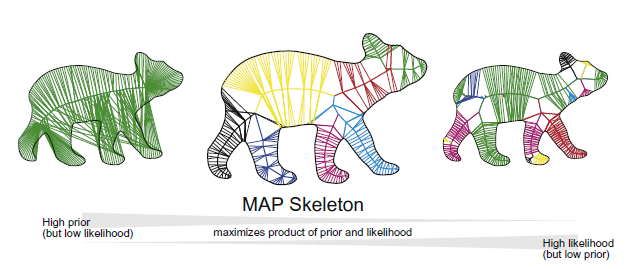
The MAP skeleton. The simplest skeleton that adequately explains the shape.
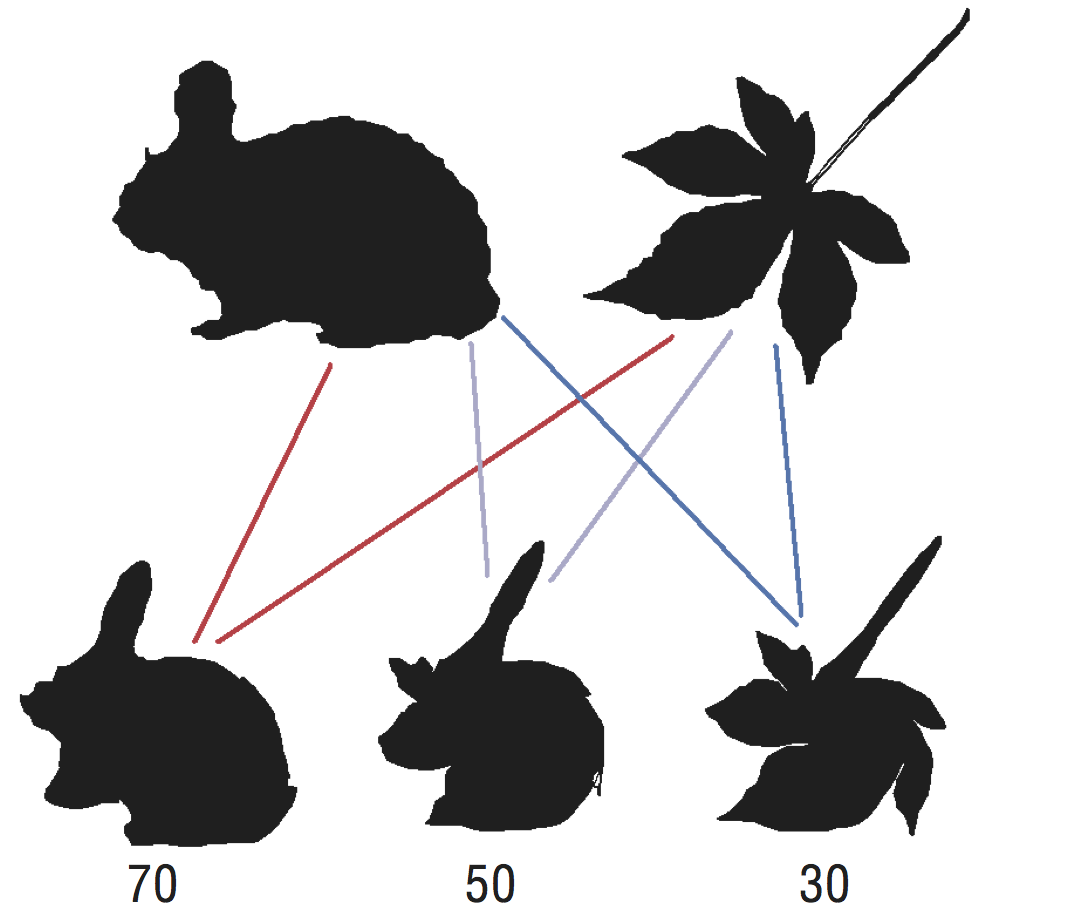
Natural shapes were morphed together. Subjects classified these novel shapes as animal or plant. A classifier was trained using the MAP skeleton representation of the natural shapes. The classifier was able to predict the human observer's classifications of the novel shapes.
In Wilder, Feldman, and Singh (2015) I advanced and tested a model of contour complexity proposed in Feldman and Singh (2005). Subjects were shown open contours (contours that do not touch at their end) embedded in noise fields. Their ability to detect the contours was related to the complexity of the contour, as the complexity of the contour increased (as measured by the description length of the contour) the ability of an observer to detect that contour decreased. These experiments have been repeated, and we have demonstrated that the model also accounts for the detection of closed contours (paper under review). The detection of closed contours was also modulated by the complexity of the shape skeleton that best fits the closed contour. This shows that the visual system pays attention to global shape structure even when this information is not necessarily task relevant.
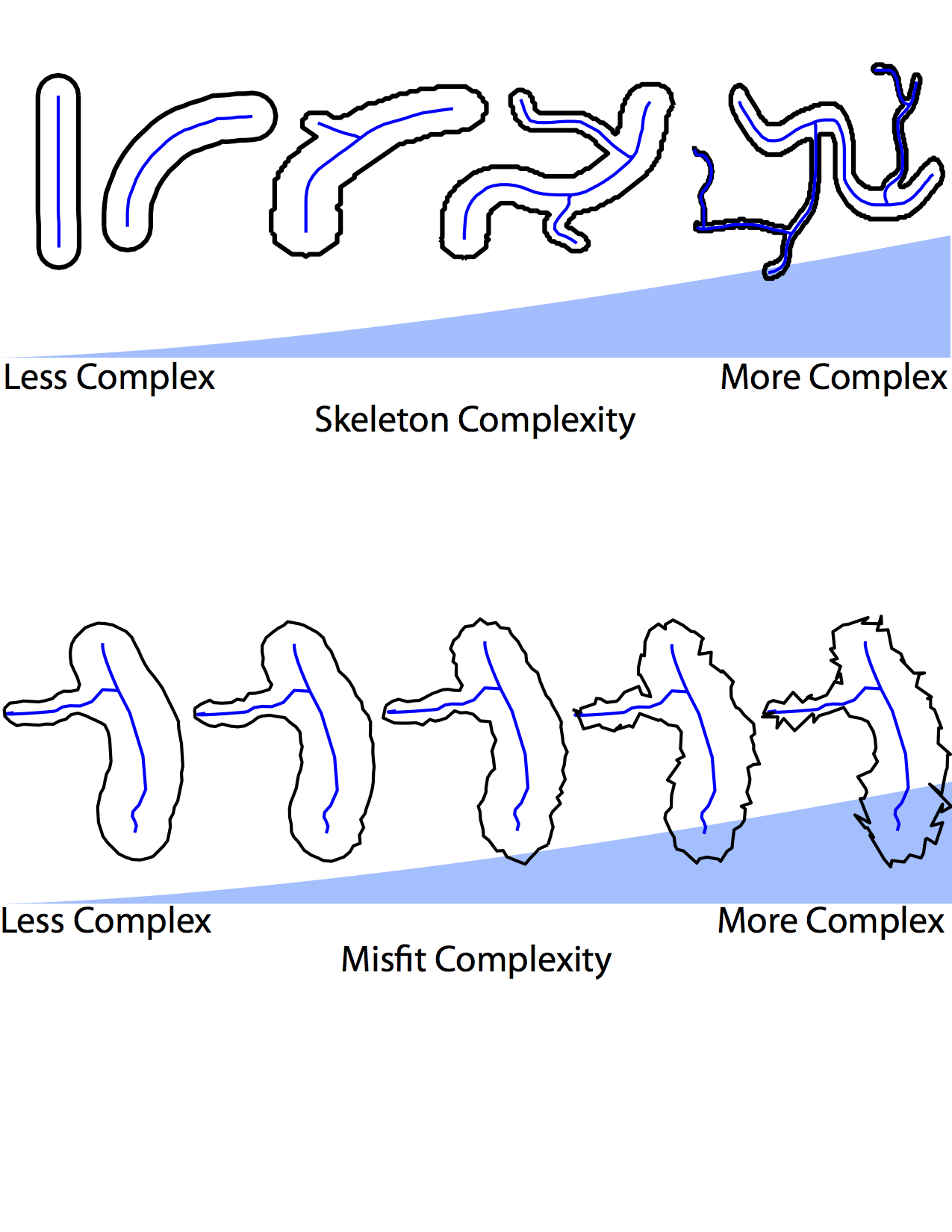
Shape complexity metrics. Skelton complexity is a measure of the internal structure of the shape. Misfit complexity is a measure of how well the best fitting skeleton explains the shape. We have shown that skeleton complexity is related to how detectable a shape is in noise, even though only a small segment of the contour needs to be detected to complete the task.
Taken together these projects suggests that for different tasks, even though different representations could potentially be more useful than others, the visual system is not completely flexible. In a categorization task, a skeletal representation that captures the global structure of the shape might be more useful, while this is not necessary for detection, since only a small, local, portion of the contour needs to be seen to successfully decide which of two noisy images contains the shape. However, the visual system is influenced by a more global skeletal representation in a detection task.
Also, while at Rutgers, I collaborated with Prof. Eileen Kowler on eye movements. In Wilder, et al. (2009) we measured how much attentional cost there is to making an eye movement. In another project, we studied how an observer decides when to move the eye to a new location. Standard models of information accumulation model the process stochastically, where the information accumulation is simulated with no direct connection to an actual stimulus. We designed a stimulus to allow for the direct measurement of information at every point in time. Subjects saw a display where dots appeared slowly, one at a time. Subjects were required to decide if the mean of the distribution from which these dots are sampled was to the right or left of a reference line. Subjects let dots accumulate until they either decided they had waited long enough or had enough information to make the decision about the location of the mean of the dot generating distribution. One key part of this project was the creation of a task that allowed us to give the observer relevant information in measurable chunks, giving us an upper bound on the amount of information used by the observer to complete the task. We directly compared predictions from an information accumulation model and an internal clock (timer) model. Neither model, nor standard variations on those models, was able to completely account for our subjects’ behavior. We find that a hybrid evidence/timer model is necessary to account for subject behavior.