| Resource |
My research interests lie in the design of data model and data management algorithms in information dissemination and web search systems. In particular, my research focuses on data representation, data management and data indexing and filtering algorithms. My representative research projects are described as follows.
Approximate Matching-based Publish/Subscribe System (A-ToPSS)
In the publish/subscribe paradigm, exact knowledge of either specific subscriptions or publications is not always available. Especially in selective information dissemination applications, it is often more appropriate for a user to formulate her search requests or information offers in less precise terms, rather than defining a sharp limit. A-ToPSS aims to capture uncertainty inherent to the information in either subscriptions or publications. To address this problem, A-ToPSS proposes a new publish/subscribe model based on possibility theory and fuzzy set theory to process uncertainties for both subscriptions and publications. And an approximate publish/subscribe matching semantic is defined and efficient approximate matching algorithms are developed. The system is sufficiently scalable to support a large number of subscribers and maintain a high matching rate.
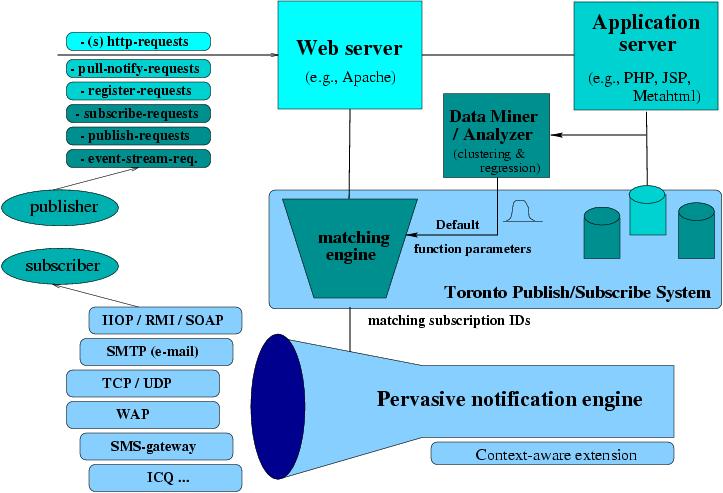
A-ToPSS Overall System Design
Fast Filtering of Graph-based Metadata (Nominated for best paper award in WWW05!!)
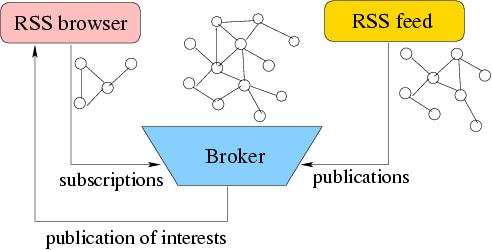
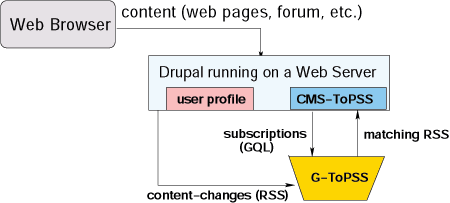
CMS-ToPSS System Architecture for RDF Site Summary Dissemination
Pipelined Filtering on Computing Cluster
To provide better scalability, we propose a cluster-based architecture for our ToPSS systems so that the workload can be distributed among several computers and can be evaluated in parallel, and hence speed up the matching and increase the system throughput compared to a centralized architecture. The key problem in designing a cluster-based publish/subscribe system is how to efficiently distribute the workload (subscription indexing and event filtering) among the cluster nodes. The algorithms we propose leverage the relationship among subscriptions and matching statistics to distribute subscriptions in a way that improves filtering efficiency maximally. We developed a pipelined filtering algorithm for graph-based data in a computing cluster environment [1]. The algorithm exploits structural differences among subscriptions to quickly identify candidate subscriptions. It effectively handles structurally similar workloads by pre-filtering based on graph node value constraints. Pipelined execution increases the throughput on multi-processor or cluster systems. We have developed two algorithms that complement pipelined filtering by effectively partitioning subscriptions into disjoint sets in order to reduce filtering time at each cluster node. Containment partitions subscriptions based on semantic similarity, while merging partitions subscriptions based on run-time access frequency. We have experimentally evaluated the performance of the filtering system in a small cluster environment and compared it to a centralized system. The results indicate that the system throughput increases by 300% for our cluster environment over a non-clustered, centralized implementation. In general, we observe that the filtering performance of our algorithms scales linearly in the number of compute nodes in the cluster.
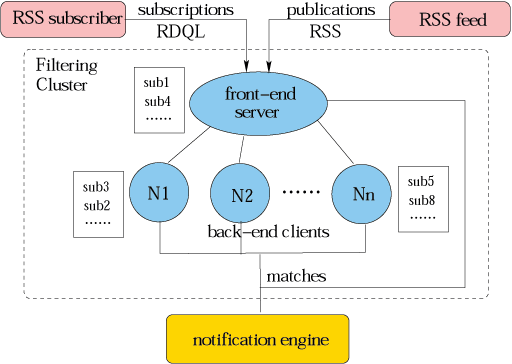
P/S Cluster System Architecture for RSS Documents
Geographically-Sensitive Link Analysis (Best Paper Award in Web Intelligence 2007!!)
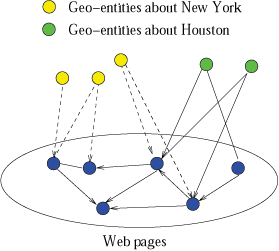
Many web pages and resources are primarily relevant to certain geographic locations. As the number of queries with a local component increases, searching for web pages which are relevant to geographic locations is becoming increasingly important. We refer to this problem as geographically-oriented search. The performance of geographically-oriented search is greatly affected by how we use geographic information to rank web pages. We study the issue of ranking web pages using geographically-sensitive link analysis algorithms. In [2], we propose several alternative graph models capturing the semantics of the geographic-entity-to-page and the page-to-page relations. Additionally, we propose geographically-oriented link analysis algorithms for each graph model. The first two algorithms, GeoRank and GeoHITS/NGeoHITS, are motivated by the original PageRank and HITS algorithms. We present a new algorithm, GeoLink that directly models the semantics of geographic locality embedded in pages. It distinguishes the role geographic entities play on different pages, in contrast to GeoRank and GeoHITS. Our evaluation shows the benefit of using the geographic-entity-to-page relation with the page-to-page relation in computing page reputations (as done by all three algorithms GeoRank, GeoHITS and GeoLink). Additionally, the evaluation highlights the side-effect of our geographically-sensitive ranking algorithms that it provides a tool to rank the actual physical entities in addition to web pages.
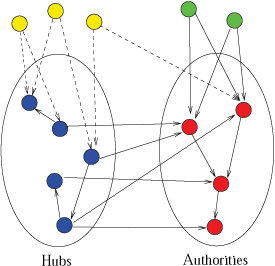
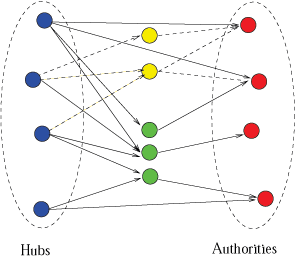
GeoRank GeoHITS/NGeoHITS GeoLink
Web Search and Mining (nominated for best award in WWW04!!)
Previous work shows that a web page can be partitioned into multiple segments or blocks, and often the importance of those blocks in a page is not equivalent. Also, it has been proven that differentiating noisy or unimportant blocks from pages can facilitate web mining, search and accessibility. However, in these researches, no uniform approach and model has been presented to measure the importance of different segments in web pages. Through a user study, we found that people do have a consistent view about the importance of blocks in web pages. We investigate how to find a model to automatically assign importance values to blocks in a web page. We define the block importance estimation as a learning problem. First, we use the VIPS (VIsion-based Page Segmentation) algorithm to partition a web page into semantic blocks with a hierarchical structure. Then spatial features (such as position, size) and content features (such as the number of images and links) are extracted to construct a feature vector for each block. Based on these features, learning algorithms, such as SVM and neural network, are applied to assign importance to different segments in the webpage. In our experiments, the best model can achieve the performance with Micro-F1 79% and Micro-Accuracy 85.9%, which is quite close to a person’s view.
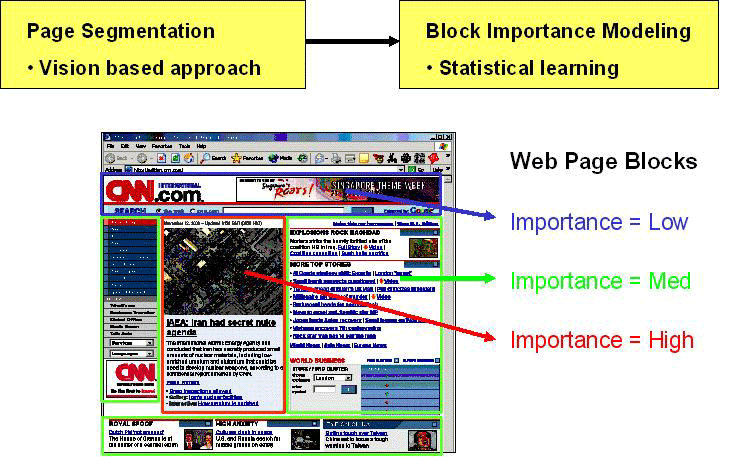
Block importance plays a significant role in a wide range of web applications. This model can help improve relevance ranking in web search, link analysis, web information extraction, web page classification
Machine Learning and its applications
Document representation and indexing is a key problem for document analysis and processing, such as clustering, classification and retrieval. Conventionally, Latent Semantic Indexing (LSI) is considered effective in deriving such an indexing. LSI essentially detects the most representative features for document representation rather than the most discriminative features. Therefore, LSI might not be optimal in discriminating documents with different semantics. In this paper, a novel algorithm called Locality Preserving Indexing (LPI) is proposed for document indexing. Each document is represented by a vector with low dimensionality. In contrast to LSI which discovers the global structure of the document space, LPI discovers the local structure and obtains a compact document representation subspace that best detects the essential semantic structure. We compare the proposed LPI approach with LSI on two standard databases. Experimental results show that LPI provides better representation in the sense of semantic structure.