CSC411/2515 Study Guide, Winter 2018
Suppose our training set and test set are the same. Why would this be a problem?
Why is it necessary to have both a test set and a validation set?
Images are generally represented as \(n\times m\times 3\) arrays, but we treat them as vectors. How is that possible?
Write pseudocode to select the \(k\) in the \(k\)-nearest-neighbours algorithm.
Give an example of a training and a test set such that 3-nearest-neighbours and 5-nearest neighbours perform differently on the test set.
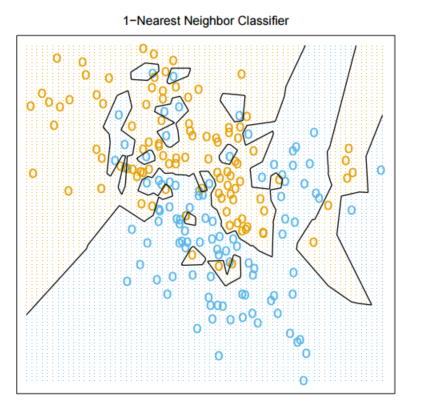
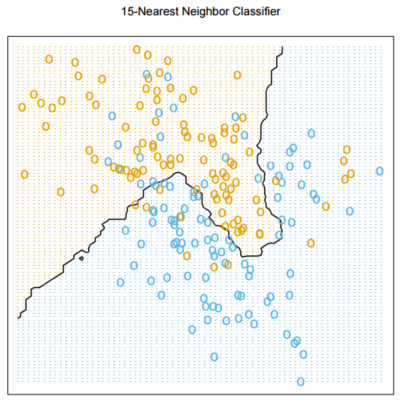
Consider the data plotted below. If all that you have to go by is the data below, how would you objectively determine whether 1-NN or 15-NN is the better classifier for the data? Use pseudocode.
Explain why the negative cosine distance may make more sense for comparing images than the Euclidean distance.
Explain why the Euclidean distance may make more sense for comparing images than the negative cosine distance
Why do we have the minus sign in the formula for the negative cosine distance?
What is the performance of k-NN on the training set for \(k = 1\)? Is it the same for \(k = 3\)? (Give an example in your answer to the second question.)
What happens to the performance of k-NN if \(k\) is the same as the size of the training set?
Give an example of a (non-image) dataset where the Euclidean distance metric makes more sense than the negative cosine distance.
Explain how the quadratic cost function \[J(\theta_0, \theta_1) = \frac{1}{2m} \sum_{i}^{m}(h_\theta(x^{(i)})-y^{(i)})^2 \] is constructed. Specifically, what is the intuitive meaning of \[(h_\theta(x^{(i)})-y^{(i)})^2?\]
How to estimate the best \(h_{\theta}\) by looking at a surface plot of the cost function, in the context of linear regression?
How to estimate the best \(h_{\theta}\) by looking at a contour plot of the cost function, in the context of linear regression?
When performing coordinate-wise gradient descent to minimize the function \(J\), the update rule is \[\text{for j = 1, 2, ..., n}: x_j \leftarrow x_j - \alpha \frac{\partial J}{\partial x_j}(x)\] When performing steepest-descent gradient descent, the update rule is: \[x \leftarrow x - \alpha \nabla J (x)\] Why are those rules not equivalent?
Characterize functions for which a larger learning rate \(\alpha\) makes sense and functions for which a smaller learning rate \(\alpha\) makes sense.
Write a Python function to find a local minimum of \[y = x^6 - 10 x^5- 5x^4 + 1\] using gradient descent.
On a plot of a function of one variable \(y= f(x)\) , at point \((x_0, f(x_0))\) , write down a unit vector that points “uphill.”
On a surface plot of a function of two variables, at point \((x_0, y_0, f(x_0, y_0))\) , write down a unit vector that points “downhill.”
Without computing the gradient symbolically, how can you estimate it? (Hint: you can estimate partial derivatives by looking at the definition of the derivative)
Suppose \(J(\theta)\) is the cost function for linear regression. Explain how to interpret \[\partial J/\partial \theta_0 = 1/m \sum_i (\theta^T x^{(i)}-y^{(i)}),\] where \(\theta_0\) is the constant coefficient.
Explain how to use regression in order to solve two-classification problems. What’s the problem with using this approach for multi-class classification?
Describe a technique for using regression for multi-class classification problems.
Show that the code below computes the gradient with respect to the parameters of a linear hypothesis function
def df(x, y, theta): x = vstack( (ones((1, x.shape[1])), x)) return -2*sum((y-dot(theta.T, x))*x, 1)Write non-vectorized code to perform linear regression.
Explain how points that are not separable by a linear decision boundary using just the original features can become separable by a linear decision boundary if computed features are used.
Recall that we can find the Maximum Likelihood solution to linear regression problems using \[\hat{\theta} = (X^T X)^{-1} (X^T Y).\] Suppose you are given a dictionary
paul_imgswhose keys are0..19, and a dictionaryjohn_imgswhose keys are0..19such thatpaul_imgs[i]andjohn_imgs[i]are the i-th image of Paul and John, respectively. The images are \(20\times 20\) NumPy arrays representing grayscale images. Write NumPy code that would take in a new image, and returnTrueif it’s likely a picture of Paul and False if it’s likely a picture of John. Use linear regression.Explain why it makes sense to use Maximum Likelihood estimation.
Explain why it sometimes makes sense to use a prior on the parameter \(\theta\).
Show that, for priors that are never zero, the more training data there is, the less important is the prior for Maximum A-Posteriori inference. Show that by writing down the posterior probability that is being maximized
Define the 0-1 classification error. What is the gradient of the 0-1 classification error?
One issue with the quadratic cost function when it is used in the context of classification is that the cost is large when \(\theta^T x^{(i)}\) is very large. Explain why that is a problem by considering a situation where there is just one point \(x^{(i)}\) for which this happens.
Show that the decision surface when using Logistic Regression is a hyperplane. (First, define what a hyperplane is.)
Show that \[\sigma'(t) = (1-\sigma(t))\sigma(t).\]
Show that the gradient of the quadratic cost is very small for points where the classifier is ``very sure" when using \(h_\theta (x) = \sigma(\theta^T x)\) as the hypothesis function. Why is it a problem?
Looking at slide 1 of the Linear Classification lecture, describe precisely how to obtain the decision boundary (i.e., an equation for the decision boundary) when the input is a list of coordinates of orange points and coordinates of blue points.
Draw a graph for the quadratic cost that is similar to the graph on Slide 15 of the linear classification lecture.
Explain why the Cross Entropy loss used in the Logistic Regression context makes sense.
Prove that the Maximum Likelihood estimate for \(\theta\) when \(Y_i\sim Bernoulli(\theta)\) is \(\frac{1}{n} \sum_i^{n} y_i.\)
Show that, for priors that are never zero, the more training data there is, the less important is the prior for Maximum A-Posteriori inference. Show that by writing down the posterior probability that is being maximized
Recall the following code. Explain why
theta_hatwill tend to have larger values (in terms of the absolute value thantheta.def compare_theta_theta_hat(N, ndim, sigma_theta, sigma): theta = scipy.stats.norm.rvs(scale=sigma_theta,size=ndim+1) x_raw = 100*(random.random((N, ndim))-.5) x = hstack((ones((N, 1)), x_raw, )) y = dot(x, theta) + scipy.stats.norm.rvs(scale= sigma,size=N) theta_hat = dot(linalg.pinv(dot(x.T, x)), dot(x.T, y)) return theta[1], theta_hat[1]How would you use Bayesian inference in order to make it so that
theta_hatis not systematically larger? Explain why your prior makes sense.Show that minimizing the sum of squared differences between the prediction \(h_\theta (x)\) and the actual outputs \(y\) is equivalent to maximizing the likelihood when \(y\sim N(\theta^T x, \sigma^2)\).
Show how to compute AND using a neural network that uses logistic neurons.
Why can’t you use the log-loss when using linear neurons?
Assume that \(y\sim Poisson(\theta^T x)\). Derive the log-likelihood of the training set where the inputs are x and the output are y.
Write Python code to find the Maximum Likelihood estimate for \(\theta\) where \(y\sim Poisson(\theta^T x)\).
After you find the Maximum Likelihood estimate for \(\theta\) where \(y\sim Poisson(\theta^T x)\), how would you use it to make predictions for new data?
Suppose that your model for the data is \[y\sim Poisson(\alpha x+10), \] with \(\alpha \in \mathbb{R}\). Assume you believe that \(\alpha\sim N(0, \beta)\). Write Python code to obtain the posterior distribution of \(\alpha\) given a dataset, and to obtain the Maximum A-Posteriori (MAP) estimate of \(\alpha\).
Write vectorized code (i.e., you cannot use for-loops) to compute the output of a feedforward neural network with the activation function \(g\).
Explain all three of the contour plots below (i.e., state what each contour plot corresponds to). Why do they show that, in this case, L1 regularization (with what \(\lambda\)?) leads to a sparse solution? Point out the minima that you can obtain from the contour plots. Sketch the contour plot of the cost function obtained when summing up the error and regularization terms.

Suppose that both height and weight predict shoe size, but height predicts shoe size a little better. Explain why L1 regularization can make the coefficient for weight be 0 but L2 regularization may not.
Explain the intuition for Early Stopping accomplishing the same task as L2 regularization.
Write vectorized code (i.e., you cannot use for-loops) to compute the output of a feedforward neural network with the activation function \(g\) .
What is the disadvantage of using a single output when using feedforward neural networks for classification?
What is the log-loss in the context of multiclass classification with output passed through the softmax? Explain the log-loss by interpreting it as the likelihood of the expected output.
What is the disadvantage of using the quadratic cost function when using feedforward neural networks for classification, compared to the log-loss? When answering, consider how a single atypical example would influence the log-loss cost and the quadratic cost, and describe the consequence of that for our estimate of the network parameters \(\theta\) .
Consider solving a classification problem by specifying that for Class 1, \(y = 1\) , for Class 2, \(y = 2\) , etc. What is the decision surface implied by this if we’re using linear regression?
Suppose we are using multinomial logistic regression for a multiclass classification problem. What does the decision surface look like now? Explain the relationship between measure the distance of a point from a hyperplane and using multinomial logistic regression. Be precise. See here for how to compute the distance from a point to a plane.
Explain why the output of Softmax is better for representing probabilities than the raw output layer
What is one advantage of the \(\tanh\) activation function compared to the sigmoid activation function? Give a concrete example.
Explain what it means for a neuron to be dead. Why is that a bad thing? What is the implication for initializing the weights and biases for ReLU units?
Consider the network below
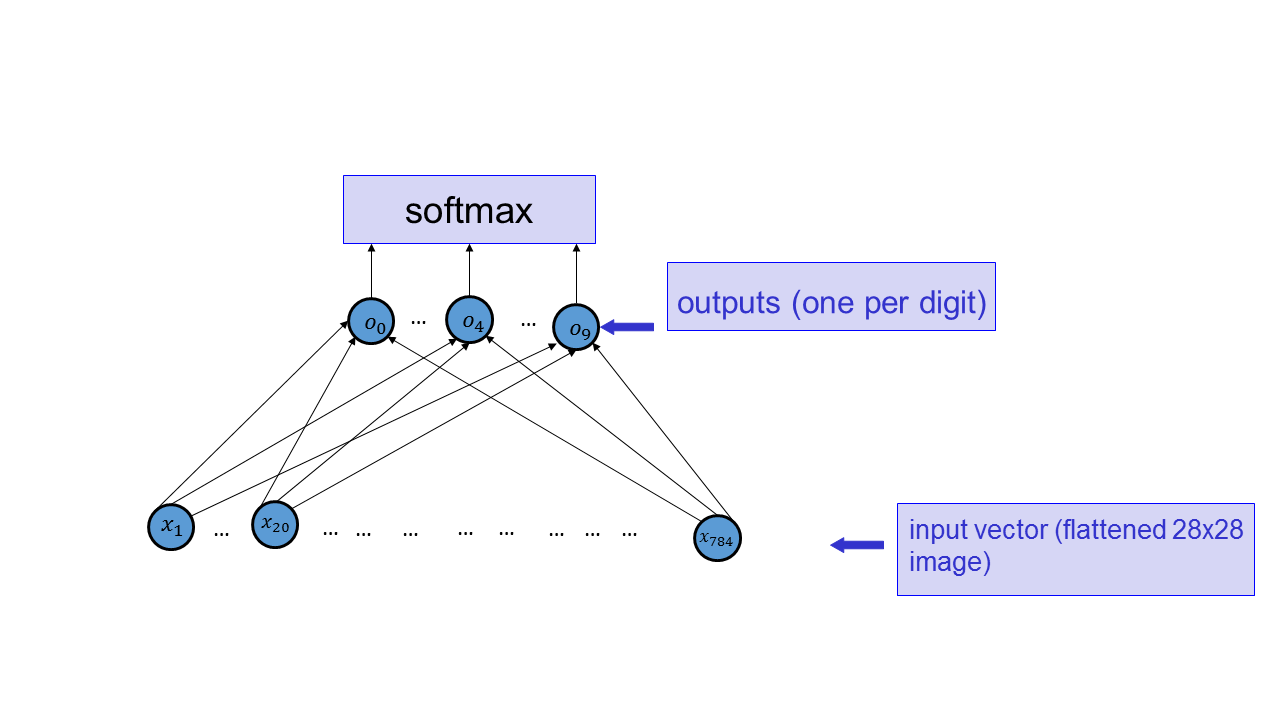
What would be the effect of applying the \(tanh\) nonlinearity to the output layer before passing the output units through the softmax?
Why is it useful to normalize the input data?
The learning curve here can sometimes be “wiggly.” How would you make it less wiggly?
Devise of an example of fitting a curve in 2D where a cubic polynomial would overfit, but a quadratic polynomial will work. In your example, sketch the points in the training and test sets and provide a cost function.
Suppose we modify our cost function as follows: \[cost_{wd} = cost + \frac{\lambda}{3}\sum_{i,j, k}(W^{k, i, j})^3.\] How would you compute the gradient of \(cost_{wd}\)? Why is adding the cubes of the weights to the cost function a bad idea?
Design a network that uses the sigmoid activation functions to compute the XOR function
Why does momentum help when optimizing neural networks?
Explain why inputs on different scales can cause “ravines” in the cost function
Explain why, in a network with sigmoid activations, all the weights that connect to hidden units from another hidden layer will change in one direction during a gradient descent update. Why is that to be avoided? How does using tanh units help with this issue?
Prove that for a one-hidden-layer neural network with nonlinear activation functions, the cost function is not convex in the weights.
Explain why Dropout prevents feature co-adaptation – i.e., the output’s depending on several hidden units activating at the same time. Explain why this helps with regularization. How would you implement backpropagation when dropout is being used?
Explain why fitting a fifth-degree polynomial to data is more likely to lead to overfitting than fitting a quadratic function to data. (It is not enough to say “capacity control” – explain the phenomenon in plain terms.)
Explain why “teaching to the test” in an educational setting is analogous to overfitting.
Usually, when visualizing the weights of a neural network classifying faces, you would tend to observe “noisy” images when there is overfitting. Why? Why does this not happen when the training set is extremely small?
Explain in plain language why 1-Nearest Neighbours has more capacity than 15-Nearest Neighbours.
A one-hidden-layer with 300 hidden units be viewed as an algorithm for matching 300 templates to the input. How would you implement a neural network that works similarly to a 300-Nearest Neighbour classifier?
When doing classification with a softmax on top of the output layer and the log-loss cost, the derivative of the cost with respect to the i-th output is \[\frac{\partial C}{\partial o_i} = \sum_j \frac{\partial C}{\partial p_j} \frac{\partial p_j}{\partial o_i}= p_i-y_i.\] Prove this.
- Consider the following Geoff Hinton fact:
In Jan 2012, I made a post on Google+ reproducing a dialog that occured between Geoff Hinton and Radford Neal, while Radford was giving a talk at a CIfAR workshop in 2004:
Radford Neal: I don’t necessarily think that the Bayesian method is the best thing to do in all cases…
Geoff Hinton: Sorry Radford, my prior probability for you saying this is zero, so I couldn’t hear what you said.
Explain the last sentence. Define the different posterior and prior probabilities implied by this conversations mathematically.
Why is momentum term set to 0.99 instead of 1? Is there any difference?
On slide 8 here , you see a way of obtaining an image where points near horizontal edges are bright and everything else is dark, but this only works for edges that happen across a step of 2 pixels (or a little bit more). How would you produce an image that shows horizontal edges where the transition between one area and another is more gradual, and happens over, say, 10 pixels?
Explain slide 19 here. Why is \((N − F)/stride + 1\) the output size?(What do we mean by “output size?” Precisely define what N, F, and stride refer to.)
Why to we sometimes pad the border of the image with zeros when performing convolutions?
Explain the difference between Max Pooling and Average Pooling. Write Python code that performs both.
In what situations might you expect Max Pooling to work better than Average Pooling (and vice-versa)?
Give an example of a gradient computation when a network has a convolutional layer.
Give an example of a gradient computation when a network has a max-pooling layer.
Suppose the size of an input layer is \(32\times32\times 3\) , and you have 10 \(5\times 5\) filters with stride \(2\) and pad \(2\) . What is the number of parameters (weights+biases) that we need in order to define the connections between the layers? What is the size of the output layer?
Why would we ever use \(1\times 1\) convolutions?
How many output units if we are computing the first convolutional layer of a network which takes as input an \(N\times N\times 3\) image using M \(3\times 3\) features, using 0 padding and a stride of 1?
Suppose we want to visualize what a neuron in a ConvNet is doing. How would you go about that?
Sometimes when we visualize what a neuron is doing, we display an image that’s smaller than an input image. How is that done?
Explain what it means when we compute \(\partial neuron/\partial x_i\) for every \(i\), where \(x\) is the input. What is the visualization of of that gradient means intuitively?
Explain guided backpropagation. Provide pseudocode, and explain how guided backprop improves on simply computing the gradient.
Describe a situation where \(\theta_{ML} = \theta_{MAP}\) regardless of what the training data is.
Suppose you have training data where each data point contains information about whether the person tested positive for cancer and whether they actually have cancer. Write Python code to generate training data that was generated using the same process (i.e., same \(\theta\) ; note that you initially don’t know \(\theta\) ) as the training data.
Same question as above, but now the test result is a real number. You can use the fact that if the data is \(x^{(1)}, x^{(2)}, ..., x^{(n)}\) and \(x^{(i)} \sim N(\mu, \sigma^2)\) , then \(\mu_{ML} = \bar{x} = 1/M \sum x^{(i)}\) and \(\sigma_{ML}^{2} = 1/M \sum (x^{(i)} - \bar{x})^2\).
Prove that \(\mu_{ML} = \bar{x} = 1/M \sum x^{(i)}\) when \(x^{(i)}\sim N(\mu, \sigma^2)\).
We have a test for a disease that can come out as either positive or negative. We know about each patient in the training set whether they have the disease or not. Write code to learn the parameters of the data, and to randomly generate more data that’s distributed similarly to the training data.
The previous question can be addressed directly, or using a generative classifier framework. Explain the difference in terms of the quantities (i.e. parameters) being estimated. (For example, in the generative classifier framework we do not estimate \(P(cancer|+)\) directly.
Explain how to estimate \(P(cancer|+)\) from \(P(cancer)\) , \(P(+|cancer)\) , and \(P(-|\neg cancer)\) . Justify every step.
Suppose the outcome of a test is a real number. Explain how to train a generative Gaussian classifier in order to determine the probability that a patient has the disease. Justify all derivations.
In slide 14, we claimed \[P(cancer|t, D)= \sum_{\theta' \in \Theta} P_{\theta'}(cancer|t)P(\theta'|D).\] Prove this, referring to standard facts in probability.
The above formula would be difficult to apply if \(\theta\) is continuous. Why? Propose a solution to this issue.
Describe a scenario where \(\sum_{\theta' \in \Theta} P_{\theta'}(cancer|t)P(\theta'|D)\) is substantially different from \(P_{\theta_{MAP}}(cancer|t)\).
Explain two ways of visualizing what a neuron in the inner layers of a deep ConvNet is doing.
Explain why gradient ascent on the input, using \(\nabla_x output\), can be useful for understanding what the neural is doing. Why is it gradient ascent rather than gradient descent?
Explain this equation on Slide 21 here: \[p(review, us | spam) = (1-2/4)(1/4)(1-3/4)(3/4)(1-3/4)(1-1/4)\]
Explain this equation on Slide 21 here: \[p(spam | review, us) = \frac{p(review, us|spam)p(spam)}{p(review, us|spam)p(spam)+p(review, us|notspam)p(notspam)}\]
Explain why the “curse of dimensionality” (high-dimensional x’s) necessitate using something like the Naive Bayes assumption
When we interpret \(m\) as “virtual” examples in \(P(x_i=1|c)\approx \frac{count(x_i=1,c)+m\hat{p}}{count(c)+m}\), why does it make sense to have \(\hat{p} = P(x_i=1|c)\) be the prior?
The training cost for logistic regression is always going to be no higher than the cost for Naive Bayes. Explain why that is, and prove it.
Explain Slide 28 here: what is the model assumption being made? (Be explicit: don’t use words like “Naive” and “Bayes”)
Explain the benefits of modeling \(p(x|y)\) directly in the context of building generative classifiers
Show that a 1-dimensional multivariate Gaussian is the same as a plain Gaussian
Sketch a multivariate Guassian with \(\Sigma = \begin{bmatrix}1&0.2\\0.2&1\end{bmatrix}\)
Write the exact equation (no constants allowed) for the decision boundary of a Gaussian Bayes Classifier. Show that the boundary is quadratic in \(x\).
How would you lean a shared covariance when learning a Gaussian Bayes Classifier (how would learn a non-shared one?)
Show that the decision boundary is linear when the covariance is shared when using a Gaussian Bayes Classifier
How many parameters does a Naive Bayes classifier have?
If we know the parameters, how would we estimate the counts of features equalling 1 belonging to each class, in the context of a Naive Bayes models with unknown labels?
In a context where only the inputs (
x) are known, but not the labels (y), what does \(P_{\pi, \theta}(x)\) mean? How can we compute it?Propose a plausible dataset that violates the Naive Bayes assumptions.
Explain how to generate a data from a Mixture of Gaussians model.
In the E-step, when training a MoG model, we compute the responsibility of each cluster for each point \(P(z^{(i)}=cl|x^{(i)}, \pi, \mu, \Sigma)\). Explain exactly how to compute it and what it means.
\(\pi_{cl}\) is the average of the \(w_{cl}^{(i)}\). Why?
Explain the k-means algorithm and why it makes sure that the mean square distance to the cluster centres always decreases.
Give an example of a local optimum for k-means. Give an example of a bad local optimum for MoG.
Suppose we learned a model for the email data (without labels) using the EM algorithm. How would you generate “fake” email data using the model that you learned?
In the MoG tutorial, the Gaussians each stay in their corner of the plane. Why?
Why is it essential in the EM for Binomials tutorial that we observe several tosses of the same coin at a time?
Write down \(P(observations|\theta)\) for the model in the EM for Binomials tutorial. Write down the E-step and the M-step using algebra and explain how to figure them out.
Consider images that consist of n pixels. Explain why and how they can always be represented as the weighted sum of the n vectors that constitute the standard basis for \(\mathbb{R}^n\).
The goal of PCA is to find a small basis such that all the vectors in the training set can be approximately reconstructed using that basis. Write down the cost function that’s being minimized when performing PCA.
PCA is a form of unsupervised learning. One goal of unsupervised learning is computing informative/interesting features for new inputs. What features can be computed using PCA?
A “cloud” of points with zero mean is rotated using the matrix of eigenvectors of its covariance matrix. Show that the covariances of the i-th and j-th coordinates of the points for \(i\neq j\) is 0.
Explain how to interpret the coordinates of the points of the rotated cloud as the coefficients of the same points in a different basis.
Assume a 2-d cloud of points distributed with a multivariate Gaussian distribution. Assume \(v_1\) is the Eigenvector corresponding to the largest Eigenvalue of the covariance matrix of the points. What is the reconstruction of an arbitrary point in the subspace \(span(v_1)\)?
Explain the geometric intuition for why the variance of the reconstructions obtained in the question above is as large as possible for a 1-D subspace.
Assume we know the principal components for a training set of faces. State how to reconstruct a face using the first k principal components.
Explain why the reconstruction is \(\hat{x} = V(V^Tx))\).
Sketch the architecture of an autoencoder. How is an autoencoder trained? (What is the cost function?)
Why do we say that the code obtained by the autoencoder contains useful features extracted from the input image? (I.e., what’s the intuition that this would usually be the case?)
Explain why PCA is a special case of an autoencoder.
What is the decision surface associated with decision trees? Explain why it has the shape it does.
Compare the hypothesis space for decision trees and one-hidden-layer neural networks with 20 hidden neurons. Which model has the larger capacity? Why?
Give pseudocode for constructing a decision tree, assuming you have an function that selects the best attribute to split on.
For splitting on continuous attributes when growing a decision tree, give an efficient algorithm for selecting a threshold.
Why is the error rate not ideal for deciding which attribute to split on when growing a decision tree?
Explain why \(H(V)\) the entropy of a random variable \(V\), \(H(V) = -\sum_v P(V=v)\log_2 P(V=v)\) can be interpreted as the average amount of information need to communicate the outcome of \(V\).
For which value of \(p\) is the entropy of \(Bernoulli(p)\) the highest? Prove your answer, and explain the intuitively why the answer is the one that you’d expect.
Plot two hypothetical mass probability functions, one for a random variable with high entropy, and one for a random variable with low entropy.
What are the largest and the smallest possible values of \(H(B|A)\)? What is the intuition behind that answer?
Do the exercise on slide 30 here.
On slide 31, we say that any concave function of p will work. What is \(p\) in the context of selecting an attribute to split on? What is the concave function in question? (Figure out what X we are conditioning on when).
List three ways of dealing with missing attributes in some samples.
Explain how to convert a decision tree to a list of rules.
Explain rule post-pruning
When computing the total reward in RL, we usually use a discount factor \(\gamma\) , and compute \(r_0 + \gamma r_1 + \gamma^2 r_2 + ...\) . Explain why discounting makes sense from the point of view of optimizing the agent’s policy, and also why it leads to the agent’s potentially completing tasks faster (when the agent tries to optimize the discounted reward.)
The average-value cost function in RL is \(J_{avV}(\theta) = \sum_s d^{\pi_\theta}(s)V^{\pi_\theta}(s)\) . Define all the quantities in that formula, and explain why the formula makes sense.
How is the policy \(\pi_\theta\) optimized using gradient ascent. (That is, what are you computing the gradient of? How do you use the gradient?)
Explain how Policy Gradient learning can work by approximating the gradient using finite differences.
The Policy Gradient Theorem is: \[\nabla_\theta J_{avV}(\theta) = \sum_s d^{\pi_\theta }(s)\sum_a q^{\pi_\theta}(s, a)\nabla_\theta \pi_\theta (a|s).\] Explain the notation, and explain why this intuitively could make sense.
Give an example of a probabilistic policy, and the gradient of its computation.
Explain the steps needed to get from the Policy Gradient Theorem to the REINFORCE algorithm.
Why does it make sense to use Convolutional Neural Networks to evaluate a Go position?
We reconstructed a student’s grade on the midterm using \(\mu + \lambda_1 v_1\). Explain how to interpret \(\lambda\). Why does it make sense that all the entries in \(v_1\) are positive? Do they have to be positive?
Give a mathematical definition of overfitting. How does it correspond to the notion of “fitting the peculiarities of the training set rather than the patterns in the data”? In the context of the precise definition of overfitting, explain how “teaching to the test” in an educational setting lead to overfitting,
Compute the distance between the lines \(w^T x + b=2\) and \(w^T +b = 5\).
Make up four datapoint in 2D, and write the constraints subject to which we would minimize \(w^T w\) if we were fitting a linear SVM. Do not use “if”s.
In linear SVMs with a soft margin, what does a large \(\epsilon\) mean?
The following conditions are equivalent. Why? \[w^T x^{(k)} + b \geq 1-\epsilon^{(k)}, y^{(k)}=1 \\ w^T x^{(k)} + b \leq -1+\epsilon^{(k)}, y^{(k)}=-1\] and \[(w^Tx^{(k)}+b)y^{(k)} +\epsilon^{(k)}\geq 1.\] Assume \(\epsilon^{(k)}\geq 0\).
Show that the primal formulation for linear SVM with soft margins and the the negative log-likelihood for the logistic regression model have similar form. Why do we say that some examples in the training set don’t influence the deicsion boundary in SVMs? Refer to the hinge loss in your answer.
In the soft margin formulation, we minimize \(\frac{1}{2}w^T w + C\sum_{k}^{R}\epsilon^{(k)}\). Does larger \(C\) mean more or less regularization? Why?
(A version of the) Representer Theorem states that \(w^{*} = \sum_k \alpha_k y^{(k)}x^{(k)}\). Explain why this means that we only need to compute linear combinations of dot products between the \(x\)’s to get the output we need.
After finding the optimal \(w\), how do we figure out what the support vectors are?
Explain the Kernel Trick. Start from the fact that the prediction for a linear SVM is \(f(x) = \sum_k \alpha_k y^{(k)}(x^{(k)}\cdot x) + b\).
Explain the intuition behind kernels measuring how close two points are.
For an SVM with kernel \(K\), how do we make predictions for new data?
We can decompose \(E[(Y-\hat{f}(X))^2]\) into an irreducible error component, a squared bias component, and a variance component. Write down the formula for each, and explain why it makes sense.
What is the expectation taking with respect to when computing the Variance component \(E[(E[\hat{f}(x)]-\hat{f}(x))^2]\)? Explain when the Variance component would be \(0\).
A linear model is low-variance, but high-bias. A 100-degree polynomial is low-bias but high-variance (for a training set of about 100 points). Explain why in terms of the bias-variance decomposition.
A 100-degree polynomial is low-variance for a training set of 100,000 points. Why?
Give an example of a situation where the model has high bias.
Explain why an average of two parabolas has higher capacity than one parabola. Does the same work with linear models?
Give the pseudocode for Bagging.
How do random forest produce diverse classifiers? (Name two tricks.)
Explain out-of-bag estimation.
Explain N-fold cross-validation.
Explain why leave-one-out cross-validation is a special case of N-fold cross-validation.
Argue that SVMs can be considered to be a non-parametric model.
What is the key idea in Boosting?
Sketch the architecture of a Mixture of Experts network. Explain why the architecture makes sense.
(OPTIONAL) Explain why \(q^{*}(a, s) = E[r_{t+1}|S_t=s, A_t = a] + \gamma E[max_{a'}q^{*}(a|s)|S_t=s, A_t=a],\) where \(q^{*}\) is optimal.
(OPTIONAL) Suppose we are minimizing \(Loss = L(r_{t+1}+\gamma max_{a}^{'}q(a', s_{t+1})-q(a_t, s_t))\). why does this cost make sense? How to derive the gradient step?
Explain how to generate random images using a convolutional architecture (i.e., explain the Generator Network in GANs built using Convolutional Networks).
What is the cost function when training GANs? Explain each component.
In the GAN cost function, what does \(E_{z\sim p(z)}\) mean?
Why is it better to optimize \(E_{z\sim p(z)} -\log(D_{\theta_g}(G_{\theta_g}(z)))\) than to optimize \(E_{z\sim p(z)} \log(1-D_{\theta_g}(G_{\theta_g}(z)))\)?
How do we optimize \(E_{x\sim p_{data}}\log D_{\theta_d}(x) + E_{z\sim p(z)}\log(1-D_{\theta_d}(G_{\theta_g}(z)))\) in practice? (I.e., how would you implement the optimization?)
Explain how doing arithmetic on the latent variables \(z\) of the GAN can lead to interesting images being visualized.
(OPTIONAL) What is the Deep Learning Hypothesis?