Página 6 de 8 |
El SRAF permite elegir entre dos métodos de detección de contornos: Canny y Shen-Castan (ISEF). Ambos métodos contemplan el ruido en las imágenes analizadas. Se proporcionan los dos métos con el fin de poder realizar pruebas para determinar cual de ellos es el más adecuado para diferentes situaciones.
En 1986, John Canny definió un conjunto de objetivos para un detector de contorno y describió un método optimo para conseguirlo.
Canny asume un contorno de paso sujeto a un ruido blanco Gaussiano. El detector es un filtro de contorción f que suaviza el ruido y localiza el contorno. El problema es identificar el filtro que optimize los tres criterios de detección de contornos.
En una dimensión, la respuesta del filtro f a un contorno G está dada por la integral de la contorción:
H = S[-w,w] G(-x) f(x) dx
Se asume que el filtro vale cero fuera de la región [-w, w]. Matemáticamente, los tres criterios se expresan como:
SNR =
El valor de SNR es la seńal de salida para la tasa de ruido (tasa de error), y debe ser tan grande como sea posible: necesitamos muchas seńales y poco ruido. El valor de la ubicación representa la reciproca de la distancia entre el contorno localizado y el contorno verdadero, y también debe ser lo más grande posible, lo que significa que la distancia será la menor posible. El valor Xzc es una restricción; representa la distancia principal entre entrecruzados cero de f' y es esencialmente un declaración (statement) que el detector de contorno f no tendrá demasiadas respuestas para el mismo contorno en una región pequeńa.
Canny intenta encontrar el filtro f que maximize el producto SNR x Ubicación sujeto a la restricción de respuestas múltiples, y mientras el resultado es demasiado complejo para ser resuelto analíticamente, una aproximación logra ser (turns out) la primera derivada de una función gaussiana.
La aproximación al filtro optimo de Canny para la detección de contornos es G', y entonces contorcionando la imagen de entrada con G' se obtiene E que tiene contornos resaltados (enhanced), aún en presencia de ruido, el cual ha sido incorporado dentro del modelo de la imagen de contorno.
Una contorción es claramente simple de implementar, pero es computacionalmete costosa, especialmente una contorción de 2 dimensiones. Sin embargo, una contorción con una gaussiana de 2D puede ser separada en dos contorciones con una gaussiana de 1D, y la diferenciación puede ser realizada en último lugar. En realidad, la diferenciación también puede ser realizada por contorciones en una dimensión, dando dos imágenes. Una es la componente x de la contorción con G' y la otra es la componente y.
De está forma, el algoritmo del detector de contorno Canny es:
El programa principal abre y lee el archivo de la imagen, y también lee los parámetros (como tita). Luego llama a la función canny, la cual realiza la mayor parte del trabajo. La primer cosa que realiza canny es calcular la máscara de filtro gaussiano (llamada gau en el programa) y la derivada de la máscara de filtro gaussiano (llamada dgau). El tamańo de la mascara a ser usado depende de tita; para un valor de tita pequeńo la gaussiana será rápidamente cero, resultando una máscara pequeńa. El programa determina automáticamente el tamańo necesario de la mascara.
Luego, la función calcula la contorsión como en el paso 4 anterior. Esto es realizado por la función separable_convolution que recibe la imagen de entrada y la máscara, y retorna las partes x e y de la contorsión (llamadas smx y smy en el programa, estas son arreglos 2D de números de punto flotante). La contorsión del quinto paso anterior es calculada luego llamando dos veces a la función dxy_separable_convolution , una vez para x y otra para y. Las imágenes reales resultantes (llamadas dx y dy en el programa) son las componentes x e y de la imagen contorsionada con G'. La función norm calculará la magnitud de cualquier par de componentes x e y dados.
El paso final en el detector de contorno es un poco curioso al principio, y requiere de alguna explicación. El valor de los pixeles en M es grande si son pixeles de contorno y más pequeńo si no lo son, entonces el umbralado podría ser usado para mostrar el pixel de contorno como blanco y el fondo como negro. Esto no da muy buenos resultados; lo que se debe realizar es umbralar la imagen basándose parcialmente en la dirección del gradiente en cada pixel. La idea básica es que los pixeles de contorno tienen una dirección asociada con ellos; la magnitud del gradiente de un pixel de contorno debe ser mayor que la magnitud del gradiente de los pixeles del gradiente de cada lado del contorno. El paso final en el detector de contorno Canny consiste en suprimir-nomáximo, donde los pixeles que son no máximos locales son removidos.
La figura 1.13 intenta echar luz en este proceso utilizando la geometría. Una porción de esta figura muestra una región de 3 x 3 centrada en un pixel de contorno, el cual es en este caso vertical. Las flechas indican la dirección del gradiente en cada pixel, y la longitud de la flecha es proporcional a la magnitud del gradiente. Aquí, suprimir no máximos significa que el pixel central, el que esta bajo consideración, debe tener un mayor gradiente que sus vecinos en la dirección del gradiente; estos son los dos marcados con una "x". Esto es: Desde el pixel central, viajar en la dirección del gradiente hasta que otro pixel es encontrado; este es el primer vecino. Ahora, comenzando nuevamente desde el pixel central, viajar en la dirección opuesta a la del gradiente hasta que otro pixel sea encontrado; este es el segundo vecino. Moviéndose desde uno de estos hasta el otro se pasa a través del pixel de contorno en una dirección que cruza el contorno, entonces la magnitud del gradiente debe ser la mayor en el pixel de contorno.
En este caso especifico, la situación es clara. La dirección del gradiente es horizontal, y los pixeles vecinos utilizados en la comparación son exactamente los vecinos izquierdo y derecho. Desafortunadamente esto no sucede muy seguido.
Si la dirección del gradiente es arbitraria, seguir esa dirección lo llevará usualmente a un punto entre dos pixeles. żCuál es el gradiente aquí? Su valor no puede ser calculado, pero puede ser estimado a partir de los gradientes de los vecinos. Se asume que el gradiente cambia continuamente como una función de la posición, y que el gradiente en las coordenadas del pixel es simplemente muestreado a partir del caso continuo. Si es asumido lo primero, que el gradiente entre dos pixeles es una función lineal, entonces el gradiente puede ser aproximado por una interpolación lineal.
Un caso más general se muestra en la figura 1.13b. Aquí todos los gradientes apuntan en diferentes direcciones, y seguir el gradiente desde el pixel central ahora nos lleva entre los pixeles marcados con "x". Seguir la dirección opuesta al gradiente nos lleva entre los pixeles marcados con "y". Consideremos sólo el caso que involucra los pixeles "x" como muestra la figura 1.13c, dado que el otro caso es realmente el mismo. El pixel llamado A es el que esta bajo consideración, y los pixeles B y C son los vecinos en la dirección del gradiente positivo. Los componentes del vector del gradiente en A son Ax y Ay, y la misma convención de nombres se utiliza para B y C.
Cada pixel se halla en un eje de coordenadas que tiene una coordenada entera x e y. Esto significa que los pixeles A y B difieren por una unidad de distancia en la dirección de x. se debe determinar cual eje de coordenadas será cruzado primero cuando se mueva desde A en la dirección del gradiente. Luego la magnitud del gradiente será linealmente interpolada utilizando los dos pixeles en esa eje de coordenadas y en los lados opuestos del punto de cruce, el cual está en la ubicación (Px, Py). En la figura 1.13c el punto de cruce está marcado con "+", y está entre B y C. La magnitud del gradiente en este punto es estimada como:
G = (Py - Cy) Norm(C) + (By - Py) Norm(B)
donde la función norm calcula la magnitud del gradiente.
Cada pixel en la imagen filtrada se procesa de esta manera; la magnitud del gradiente es estimada por dos ubicaciones, una en cada lado del pixel, y la magnitud en el pixel debe ser mayor que la de sus vecinos. En el caso general hay ocho casos principales que chequear, y algunos atajos que se pueden realizar por amor a la eficiencia, pero el método anterior es el que esencialmente se utiliza en la mayoría de las implementaciones del detector de contorno Canny.
La función nonmax_suppress calcula un valor para la magnitud en cada pixel basándose en este método, y pone el valor en cero a menos que el pixel sea un máximo local.
Es posible detenerse en este punto, y utilizar el método para resaltar contornos. La figura 1.14 muestra las varias etapas al procesar una figura de testeo sin ruido. Las etapas son: calcular el resultado de la contorsión con una gaussiana en las direcciones x e y (figura 1.14a y b); calcular las derivadas de las direcciones x e y (figura 1.14c y d); la magnitud del gradiente antes de suprimir no máximos (figura 1.14e); y la magnitud luego de suprimir los no máximos (figura 1.14f). Esta última imagen todavía contiene valores de nivel gris, y debe se umbralizada para determinar que pixeles son pixeles de contorno y cuales no. Como un paso extra, Canny sugiere umbralizar utilizando Hysteresis en vez de simplemente seleccionar un valor umbral para aplicar en todos lados.
El umbralado Hysteresis usa un umbral alto Th y un umbral bajo Tl. Cualquier pixel que tenga un valor mayor a Th se presume que es un pixel de contorno, y es marcado como tal inmediatamente. Luego, cualquier pixel que este conectado con este pixel de contorno y que tenga un valor mayor a Tl también es seleccionado como un pixel de contorno, y también marcado. El marcado de los vecinos se puede realizar recursivamente, como se hace en la función hysteresis o realizando múltiples pasadas a través de la imagen.
La figura 1.15 muestra el resultado de ańadir el umbralado Hysteresis después de suprimir no máximos. La figura 1.15 es una parte expandida de la figura 1.14f, que muestra el peón en el centro del tablero. Los niveles de gris han sido ligeramente escalados para que los valores más pequeńos puedan ser vistos claramente. Un umbralado bajo (1.15b) y un umbralado alto (1.15c) han sido globalmente aplicados a la imagen de magnitud, y el resultado del umbralado Hysteresis esta dado en la figura 1.15d.
El detector de contornos de Canny es optimo con respecto a un criterio en particular. Mientras este criterio parezca lo suficientemente razonable, no hay ninguna razón para preocuparse pensando que existe solo una forma posible de detectar los contornos. Esto significa que el concepto de lo optimo es relativo y es posible que en algunos casos otros detectores sean mejores en ciertas circunstancias. De hecho a veces pareciera que la comparación toma lugar entre distintas definiciones de lo que es optimo, en vez de enfocarse las comparaciones entre los distintos esquemas de detectores de contornos que existen.
Shen y Castan están de acuerdo con Canny con la idea de la forma general de un detector de contornos: un núcleo capaz de hacer más suaves los contornos, seguido de una búsqueda de los pixels de los bordes o del contorno.
De cualquier modo, sus análisis producen una función diferente para optimizar, esta se basa en minimizar (en una sola dimensión).
En otras palabras, la función que minimiza Cn es el filtro óptimo para hacer más preciso el detector de contornos. La función optima de filtrado que se obtiene se denomina Filtro Exponencial Simétrico Infinito (ISEF - infinite symmetric exponential filter).
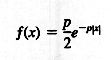
Shen y Castan sostienen que este filtro provee mejores seńales de radios con ruido que el filtro de Canny y provee una mejor localización. Esto puede deberse a que la implementación del algoritmo del filtro de Canny aproxima su filtro óptimo por la derivada de una curva de Gauss, en contraposición a Shen y Castan que usan su filtro en forma directa ; también puede debido a las diferencias en la forma en que los distintos criterios son reflejados en realidad. Por otro lado Shen y Castan no tienen en cuenta el criterio de las múltiples respuestas, y como resultado es posible que su método cree respuestas superiores a contornos ruidosos y borrosos.
En dos dimensiones el ISEF es :
![]()
Esto puede ser aplicado a una imagen en la misma forma que lo era la derivada del filtro gaussiano, como un filtro de una dimensión (1D) en la dirección del eje x, luego en la dirección del eje y. De otro modo Shen y Castan fueron un paso mas adelante y mejoraron su filtro obteniendo los filtros unidimensionales recursivos.
La función de filtro f de más arriba es una función continua y real y puede ser reescrita en forma discreta. Por ejemplo :
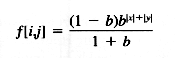
Para utilizar este filtro sobre una imagen, lo primero que hay que hacer es aplicar recursivamente el filtro en la dirección de x, dados r[i,j].
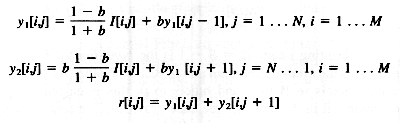
Con las condiciones de límite :
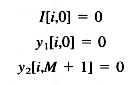
El filtrado es realizado en la dirección de y operando sobre r[i,j] para dar una salida final, y[i,j].
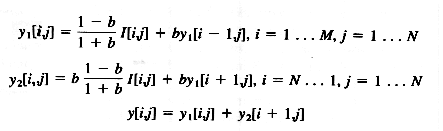
Con las condiciones de límite :
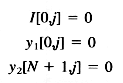
Con el uso de filtros recursivos se acelera el filtrado de la imagen. Todo el trabajo anterior hasta este punto computa la imagen filtrada. Los contornos son encontrados en la imagen hallando los ceros de una ecuación de Laplace, un proceso similar es utilizado en el algoritmo de Marr-Hildreth. Una aproximación a la ecuación de Laplace puede ser obtenida rápidamente restando la imagen original contra la imagen filtrada. Esto es, si la imagen filtrada es S y la original es I :
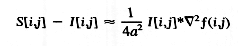
La imagen resultante B=S-I es la función de banda limitada de Laplace para esa imagen. A partir de esto se obtiene la imagen de Laplace binaria poniendo todos los pixels con valor positivo en B en 1 y los demás en cero. Esto es calculado por la función C. Los pixels de contorno candidatos están en los bordes de la región BLI que se corresponde con los ceros de la función. Esto puede ser usado como contornos, pero algunas mejoras adicionales aumentan la calidad de la identificación de pixels de contorno por parte del algoritmo.
La primer mejora es la eliminación de raíces o ceros falsos, que está relacionado a la eliminación de los valores no máximos realizados en el algoritmo de Canny. En el punto en el que se encuentra un pixel de contorno habrá una raíz en la segunda derivada de la imagen filtrada. Esto significa que el gradiente en este punto es o máximo o mínimo. Si la segunda derivada cambia su signo de positivo a negativo se la llama raíz positiva, y si cambia de negativo a positivo se la llama raíz negativa.
Permitiremos que las raíces positivas con gradiente positivo y las negativas con gradiente negativo sean utilizadas. Todas las demás se consideran falsas y por lo tanto son eliminadas.
En situaciones en que la imagen es muy ruidosa el método estándar puede no ser suficiente. Los pixels de contorno pueden ser hallados basándose en un valor de comienzo del gradiente pero Shen y Castan sugieren un método de gradiente adaptativo. Una ventana con un ancho fijo W es centrada en los pixels candidatos encontrados aplicando el método BLI. Si este es efectivamente un pixel de contorno, entonces la ventana contendrá dos regiones de diferentes niveles de grises separados por un borde (la raíz de contorno). La mejor estimación del gradiente en este punto debe ser la diferencia en nivel entre las dos regiones, donde una región corresponde a los pixels cero en el BLI y la otra región corresponde a los pixels uno.
Finalmente se aplica el método a los contornos. Este algoritmo es básicamente el mismo que el usado en el algoritmo de Canny, adaptado a imágenes donde los contornos están marcados con raíces.
Para resumir, el algoritmo de Canny filtra la imagen con la derivada de una función gausiana y luego elimina los puntos no máximos. El algoritmo de Shen-Castan filtra la imagen usando el filtro exponencial simétrico infinito, computa el BLI o imagen binaria de Laplace, suprime las raíces falsas y aplica el gradiente adaptativo. En ambos métodos, así como en el de Marr-Hildreth los autores sugieren el uso de múltiples soluciones. Ambos algoritmos ofrecen parámetros que pueden ser definidos por el usuario, lo cual puede ser útil para adaptar el método para un tipo de imagen en particular.
| << Anterior | Siguiente >> |