Department of Computer Science / University of Toronto
csc148F - Introduction to Computer Science, Fall 1995
Due 6 p.m., Thursday 7 December 1995
For each of the two languages, your program will have a lexicon of legal words. It will read in a text, and look each word up in the lexicons. Any word in the input that isn't in one of the lexicons will be flagged as a possible spelling error. The program will also know a bit about how words are formed in each language. For example, if it sees the English word getting, it will know that the word is correctly spelled if it can find get in its English lexicon.
The program will have four options: Check words for spelling in both languages, that is, accept words that are either English or Ruritanian; check spelling in English only; check spelling in Ruritanian only; or just count the number of words in the file. (The program also counts words if it's checking spelling.)
An important part of this assignment will be the use of classes and modules to deal neatly with the parts of the program that deal with English, those that deal with Ruritanian, and those that are the same for both languages.
Implementation: A simple method for storing a lexicon is as an array of strings. If the strings are stored in alphabetical order, then a binary search can quickly determine whether or not a given word is present.
Since you will need two lexicons, you should define a class for general lexicons that deals with all the aspects of lexicons that are independent of each language. So each object in the class will contain an array-the list of words-and procedures to read that list in and to perform binary search on it.
We have provided English and Ruritanian lexicons for you. Files with the base forms of the most common words of each language, sorted alphabetically (900-1000 base forms for each language), are available as pickup files 148eng.lex and 148rur.lex. (Note that you don't need to sort the lexicons; they come pre-sorted, and never change. However, your program should check each lexicon as it reads it in to make sure that it is indeed sorted.)
"WHAT??!" screamed Lisa 23 times.then the canonical forms for the tokens would be what, screamed, lisa, and times.
Table 1 lists the most common inflections in English, which your spelling checker should know about. Notice that recognizing each inflection requires taking some letters off the end of the token, and, in some cases, adding new letters. Notice that in English, an inflected word must be at least four letters long; if a token is only three letters or fewer, there is no point in checking it for inflections.
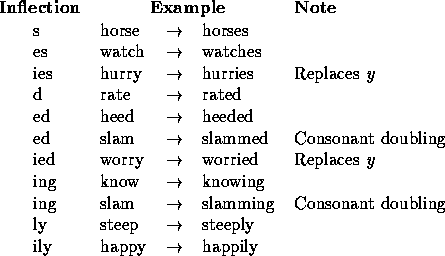
Table 1: Common inflections in English.
Two inflections, ing and ed, have the special property that they allow consonant doubling; for example, slam becomes slamming and slammed, not slaming and slamed. So after you've taken off the inflection, if the last two letters are the same consonant (e.g., if you've converted slamming to slamm), you should check the base form with and without the double consonant (e.g., check for both slamm and slam in the English lexicon).
So the method for checking whether a token is an English word is as follows:
(Notice that this approach is not perfect, because it will not detect illegally inflected words, such as aring and thinged-it will think that they are correctly spelled because are and thing are base-form words.)
To decide whether or not a token is a correctly spelled word in Ruritanian, you have to see whether or not it can be separated into base forms that can be found in the lexicon. The easiest way to do this is to work down the token, trying to find the first base form in it. If this succeeds, we remove the base form and (recursively) see whether what remains is a legal word. For example, with yowdtealbirsz, we would check whether y, yo, and yow were base forms, but we'd fail. Then, when we find that yowd is a base form, we would check whether tealbirsz was a word; again, we'd try removing prefixes, eventually find that teal was a word, and start over again on birsz.
Notice that this algorithm works only because of the no-prefix property of Ruritanian. If both yow and yowd were words, then when checking yowdtealbirsz, we would remove yow, check dtealbirsz (which isn't a word), and get the wrong answer.
Implementation: The rules for checking tokens for Ruritanian and English should be implemented in separate modules, one for each language. Each module will need to have within it an instantiation of the lexicon class for that language. (An important part of this assignment is for you to learn about the similarities and differences between modules and classes, and how to work with both of them.)
The program then reads the file, token by token, and prints a warning message whenever it finds a word that it can't recognize in the relevant language. See figure 1 for an example. (In the example, many of the possible errors are actually correctly spelled words that just weren't in the lexicon.) When the program finishes, it prints a count of the number of possible spelling errors and of the number of words in the file.
Note that your program will not be as sophisticated as commercial spelling checkers, which allow the user to correct their mistakes and to add new words to the lexicon while running the program.
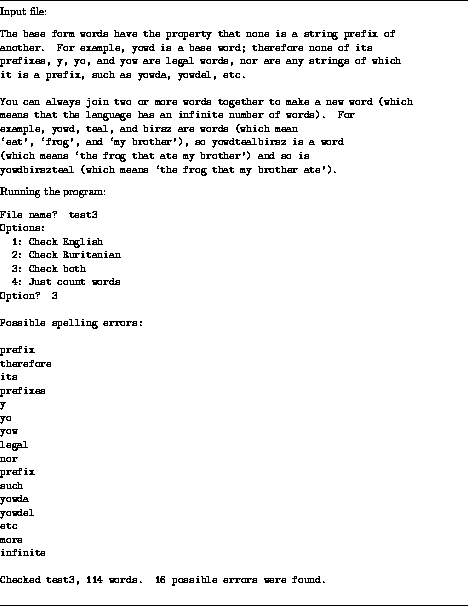
Figure 1: Example of spelling checker in operation.
 is a Ruritanian word.
is a Ruritanian word.
Hint: You can come up with a better (tighter) bound if you remember that no base-form word in Ruritarian is a prefix of another. For instance, if we are checking to see if fjord is Ruritarian, at most one of its 4 prefixes (f, fj, fjo, and fjor) can be a base-form word. That means that at most one of them has to have its remainder checked to be sure that it is a Ruritarian word. Part of your mark will be for the tightness of your bound.
 be the number of words
in your Ruritanian lexicon.
Use big-oh notation to express the worst-case time complexity
of checking whether a token of length is in the Ruritanian lexicon.
be the number of words
in your Ruritanian lexicon.
Use big-oh notation to express the worst-case time complexity
of checking whether a token of length is a Ruritanian word.
Explain how your arrived at your answer.
be the number of words
in your Ruritanian lexicon.
Use big-oh notation to express the worst-case time complexity
of checking whether a token of length is in the Ruritanian lexicon.
be the number of words
in your Ruritanian lexicon.
Use big-oh notation to express the worst-case time complexity
of checking whether a token of length is a Ruritanian word.
Explain how your arrived at your answer.
Department of Computer Science / University of Toronto
csc148F - Introduction to Computer Science, Fall 1995
Complete this page and include it in the envelope with your assignment.

