The fundamental question that we want to answer in this section is how much overhead we pay for doing the adaptation outside of the application, as opposed to by modifying the application. To answer this question in a definitive way, we would need to modify the original applications to add the adaptation behavior that we achieve with Puppeteer, and compare the resulting performance to the performance of the applications running with Puppeteer. This is not possible, since we do not have access to the source code of the applications. Instead, we present some experiments to measure the various factors contributing to the Puppeteer overhead.
This overhead consists of two elements: a one-time initial cost and a continuing cost. The one-time initial cost consists of the CPU time to parse the document to extract its PIF and the network time to transmit the skeleton and some additional control information. Continuing costs come from the overhead of the various DMI commands used to control the application. We assume that other costs, such as network transmission, transcoding, and rendering of application data are similar for both implementations.
The remainder of this section is organized as follows. First, we measure the one-time initial adaptation costs of Puppeteer. Second, we measure the continuing adaptation costs. Finally, we present several examples of policies that significantly reduce user-perceived latency.
To determine the one-time initial costs, we compare the latency of loading PowerPoint and HTML documents in their entirety using the native application (PPT.native, IE.native) and the application with Puppeteer support (PPT.full, IE.full). In the latter configuration, Puppeteer loads the document's skeleton and all its components at their highest fidelity. This policy represents the worst possible case as it incurs the overhead of parsing the document to obtain the PIF but does not benefit from any adaptation.
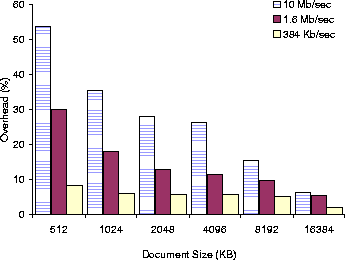
Figure 3: Percentage overhead of PPT.full
over PPT.native for various document sizes and bandwidths.
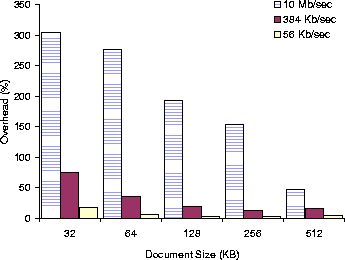
Figure 4: Percentage overhead of IE.full
over IE.native for various document sizes and bandwidths.
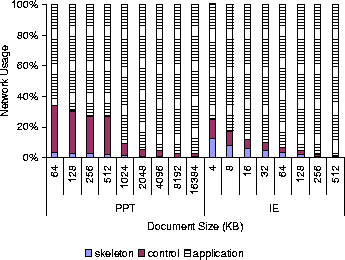
Figure 5: Data breakdowns for loading PowerPoint and
HTML documents.
Figures 3 and 4 show the percentage overhead of PPT.full and IE.full over PPT.native and IE.native for a variety of document sizes and bandwidths. Overall, the Puppeteer overhead for PowerPoint documents varies from 2% for large documents over 384 Kb/sec to 57% for small documents over 10 Mb/sec, and for HTML documents from 4.7% for large documents over 56 Kb/sec. to 305% for small document over 10 Mb/sec. These results show that, for large documents transmitted over medium to slow speed networks, where adaptation would normally be used, the initial adaptation costs of Puppeteer are small compared to the total document loading time.
Figure 5 plots the data breakdown for PowerPoint and HTML documents. We divide the data into application data and Puppeteer overhead, which we further decompose into data transmitted to fetch the skeleton (skeleton) and data transmitted to request components (control). This data confirms the results of Figures 3 and 4. The Puppeteer data overhead becomes less significant as document size increases. The data overhead varies for PowerPoint documents from 2.9% on large documents to 34% on small documents, and for HTML documents from 1.3% on large documents to 25% on small documents.
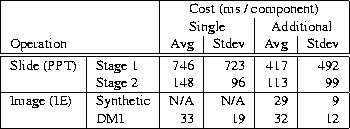
Table 2: Continuing adaptation costs for
PowerPoint (PPT) slides and IE images. The table shows the cost
of executing OLE calls that append PowerPoint slides or upgrade the
fidelity of IE images
The continuing costs of adapting using the DMI are clearly dependent on the application and the policy. Our purpose is not to give a comprehensive analysis of DMI-related adaptation costs, but to show that they are small compared to the network and rendering times inherent in the application. We perform two experiments: loading and pasting newly fetched slides into a PowerPoint presentation, and replacing all the images of an HTML page with higher fidelity versions. To prevent network effects from affecting our measurements we make sure that the data is present locally at the client before we load it into the application.
We determine the PowerPoint DMI overhead by measuring the time that the PowerPoint export driver spends loading the new slides, Stage 1, and cutting and pasting, Stage 2, as described in section 3.1.2. We expect that an in-application approach to adaptation would have to perform Stage 1, but would not need to perform Stage 2.
For IE, we determine the DMI overhead for upgrading the images in two different ways: DMI, which uses the DMI to update the images; and Synthetic, which approximates an in-application adaptation approach. Synthetic measures the time to load and render previously generated pages that already contain the high fidelity images. Synthetic is not a perfect imitation of in-application adaptation, because it requires IE to re-load and parse the HTML portion of the page, which an in-application approach could dispense with. We avoid this problem by using only pages where the HTML content is very small (less than 5% of total page size), so that HTML parsing and rendering costs are minimal.
Table 2 shows the results of these experiments. For each policy, it shows the cost of updating a single component (i.e., one slide or one image) and the additional cost incurred by every extra component that is updated simultaneously. For PowerPoint, the table shows the time spent in Stage 1 and Stage 2. For IE, the table shows the times for the DMI and Synthetic implementations.
The PowerPoint results show that the time spent cutting and pasting, Stage 2, is small compared to the time spent loading slides, Stage 1, which an in-application also has to carry out. Moreover, the time spent updating the application ( Stage 1 + Stage 2) is small compared to the network time. For example, the average network time to load a slide over the 384 Kb/sec network is 2994 milliseconds, with a standard deviation of 3943 milliseconds, while the average time for updating the application with a single slide is 994 milliseconds, with a standard deviation of 819 milliseconds.
The IE results show that the DMI implementation comes within 10% of Synthetic. Moreover, the image update times are small compared to the average network time. For instance, the average time to load an image over a 56 Kb/sec network is 565 milliseconds with a standard deviation of 635 milliseconds, compared to updating the application which takes on average 33 milliseconds with a standard deviation of 19 milliseconds.
The above results suggest that the cost of using DMI calls for adaptation is small, and that most of the time that it takes to add or upgrade a component is spent transferring the data over the network and loading it into the application. These two factors are expected to be similar whether we implement adaptation outside or inside the application.
In this experiment we measure the latency for a PowerPoint adaptation policy that loads only the first slide and the titles of all other slides of a PowerPoint presentation before it returns control to the user, and afterwards loads the remaining slides in the background. We also present results for an adaptation policy that, in addition, fetches all of the text in the PowerPoint document before returning control. With these adaptations, user-perceived latency is much reduced compared to the application policy of loading the entire document before returning control to the user.
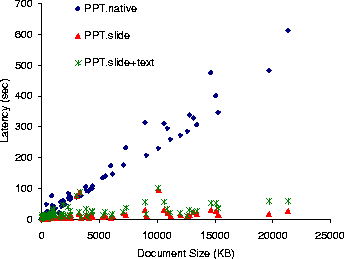
Figure 6: Load latency for PowerPoint
documents at 384 Kb/sec. Shown are latencies for native PowerPoint
(PPT.native), and Puppeteer runs for loading just the
components of the first slide (PPT.slide), and loading, in
addition, the text of all slides (PPT.slide+text).
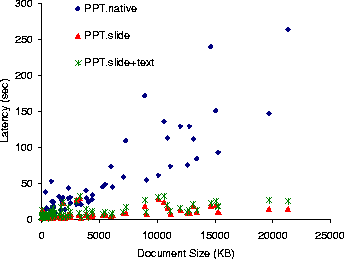
Figure 7: Load latency for PowerPoint documents at 1.6 Mb/sec.
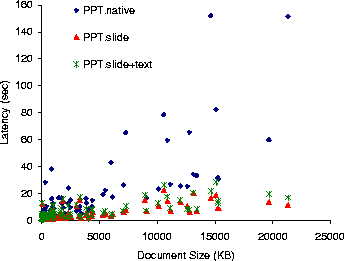
Figure 8: Load latency for PowerPoint documents at 10 Mb/sec.
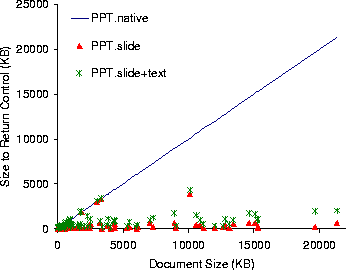
Figure 9: Data transfered to load PowerPoint documents.
The results of these experiments appear, under the labels PPT.slide and PPT.slide+text, respectively, in Figures 6, 7, and 8 for 384 Kb/sec, 1.6 Mb/sec, and 10 Mb/sec network links. Figure 9 shows the data transfered in each of the three scenarios. For each document, the figures contain three vertically aligned points representing the latency or data measurements in three system configurations: native PowerPoint (PPT.native), Puppeteer loading only the components of the first slide and the titles of all other slides (PPT.slide), and Puppeteer loading in addition the text for all remaining slides (PPT.slide+text).
We expect that reduced network traffic would improve latency with the slower 384 Kb/sec and 1.6 Mb/sec networks. The savings over the 10 Mb/sec network come as a surprise. While Puppeteer achieves most of its savings on the 384 Kb/sec and 1.6 Mb/sec networks by reducing network traffic, the transmission times over the 10 Mb/sec are too small to account for the savings. The savings result, instead, from reducing the parsing and rendering time.
On average, PPT.slide achieves latency reductions of 86%, 78%, and 62% for documents larger than 1 MB on 384 Kb/sec, 1.6 Mb/sec, and 10 Mb/sec networks, respectively. The data in Figure 9 also shows that, for large documents, it is possible to return control to the user after loading just a small fraction of the total document's data (about 4.5% for documents larger than 3 MB).
When comparing the data points of PPT.slide+text to PPT.slide, we see that the latency has moved up only slightly. The latency is still significantly lower than for PPT.native, achieving savings of, on average, 75%, 72%, and 54% for documents larger than 1 MB over 384 Kb/sec, 1.6 Mb/sec, and 10 Mb/sec networks, respectively. Moreover, the increase in the amount of data transfered, especially for documents larger than 4 MB, is small, amounting to only an extra 6.4% above the data sent for the first slide. These results are consistent with our earlier findings [&make_named_href('', "node9.html#dwz2000","[11]")] that text accounts for only a small fraction of the total data in large PowerPoint documents. These results suggest that text should be fetched in almost all situations and that the lazy fetching of components is more appropriate for the larger image and OLE embedded objects that appear in the documents.
Finally, an interesting characteristic of the figures is the large variation in user-perceived latency at high network speeds versus the alignment of data points into straight lines as the network speed decreases. The high variability at high network speeds results from the experiment being CPU-bound. Under these conditions, user-perceived latency is mostly dependent on the time that it takes PowerPoint to parse and render the presentation. For PowerPoint, this time is not only dependent on the size of the presentation, but is also a function of the number of components (such as slides, images, or embedded objects) in the presentation.
In this experiment we explore the use of lossy JPEG compression and progressive JPEG technology to reduce user-perceived latency for HTML pages. Our goal is to reduce the time required to display a page by lowering the fidelity of some of the page's elements.
Our prototype converts, at run time, GIF and JPEG images embedded in
an HTML document into progressive JPEG format using the PBMPlus [29] and
Independent JPEG Group [2] libraries. We then transfer only
the first 1/7th of the resulting image's bytes. In the client we convert
the low-fidelity progressive JPEG back into normal JPEG format and supply it
to the browser as though it comprised the image at its highest
fidelity. Finally, the prototype only transcodes images that are
greater than a user-specified size threshold. The results reported in this
paper reflect a threshold size of 8 KB, below which it becomes cheaper to
simply transmit an image rather than run the transcoder.
using the PBMPlus [29] and
Independent JPEG Group [2] libraries. We then transfer only
the first 1/7th of the resulting image's bytes. In the client we convert
the low-fidelity progressive JPEG back into normal JPEG format and supply it
to the browser as though it comprised the image at its highest
fidelity. Finally, the prototype only transcodes images that are
greater than a user-specified size threshold. The results reported in this
paper reflect a threshold size of 8 KB, below which it becomes cheaper to
simply transmit an image rather than run the transcoder.
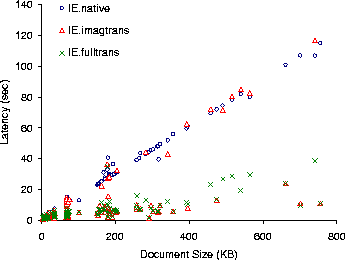
Figure 10: Load latency for HTML documents
at 56 Kb/sec. Shown are latencies for native IE (IE.native), and
Puppeteer runs that load only the first 1/7 bytes of transcoded images
(IE.imagtrans), load transcoded images and text (
IE.fulltrans).
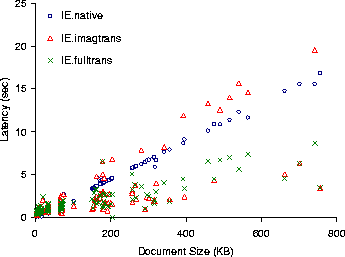
Figure 11: Load latency for HTML documents
at 384 Kb/sec.
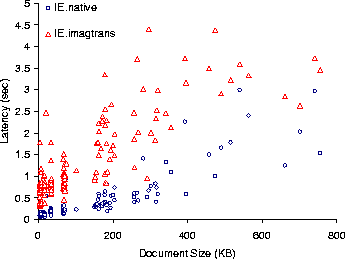
Figure 12: Load latency for HTML documents
at 10 Mb/sec.
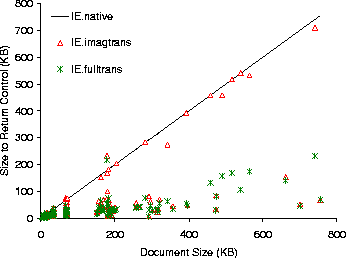
Figure 13: Data transfered to load HTML
documents.
Figures 10, 11, and 12 show the latency for loading the HTML documents over 56 Kb/sec, 384 Kb/sec, and 10 Mb/sec networks. Figure 13 shows the data transfered to load the documents. The figures show latencies for native IE ( IE.native), and for Puppeteer runs that load only the first 1/7 bytes of transcoded images (IE.imagtrans), and load transcoded images and gzip-compressed text (IE.fulltrans).
IE.imagtrans shows that on 10 Mb/sec networks, transcoding is always detrimental to performance. In contrast, on 56 KB/sec and 384 KB/sec networks, Puppeteer achieves an average reduction in latency for documents larger than 128 KB of 59% and 35% for 56 KB/sec and 384 KB/sec, respectively. A closer examination reveals that roughly 2/3 of the documents see some latency reduction. The remaining 1/3 of the documents, those seeing little improvement from transcoding, are composed mostly of HTML text and have little or no image content. To reduce the latency of these documents we add gzip text compression to the prototype. The IE.fulltrans run shows that with image and text transcoding, Puppeteer achieves average reductions in latency for all documents larger than 128 KB, at 56 KB/sec and 384 KB/sec, of 76% and 50%, respectively.
Overall transcoding time takes between 11.5% to less than 1% of execution time. Moreover, since Puppeteer overlaps image transcoding with data transmission, the overall effect on execution time diminishes as network speed decreases.
As with PowerPoint, we notice in the figures for IE that for low bandwidths the data points tend to fall in a straight line, while for higher bandwidths the data points become more dispersed. The reason is the same as for PowerPoint: At high bandwidths the experiment becomes CPU-bound and governed by the time it takes IE to parse and render the page. For IE, parsing and rendering time depends on the content types in the HTML document.