
Dec 30, 2025
Multimodal Retrieval for Automated Music Video Synthesis
A framework for automating music video editing by bridging the 'semantic gap' between abstract lyrics and concrete footage using Multi-Stream Synergy Retrieval.
Creating a compelling music video is a complex artistic endeavor. It requires a “cross-modal counterpoint”—images must not only visualize the lyrics but also synchronize with the rhythmic pulse and atmospheric timbre of the audio.
While generative AI models are advancing rapidly, they often struggle with long-form coherence and precise temporal alignment. Conversely, traditional retrieval methods fail due to the “Semantic Gap”: the disconnect between abstract, metaphorical lyrics (e.g., “fire in my heart”) and concrete video footage.
In this project, Multi-Stream Synergy Retrieval, we reformulate automated editing as a fused information retrieval problem. We employ Large Multimodal Models (LMMs) and a dual-pathway indexing strategy to align video candidates with what the lyrics say, what the music sounds like, and what the scene feels like.
🔗 Project Resources
The Challenge: The Semantic Gap
Standard dense retrieval methods frequently falter when confronted with poetic nuance. If a user queries for “Baby you’re a firework,” a standard system looks for pyrotechnics. A human editor, however, understands the metaphorical subtext of passion or resilience.
 Figure 1: Qualitative results for the song “Firework.” The system retrieves clips based on literal action (top-left), visual energy (top-right), object correspondence (bottom-left), and abstract association (bottom-right).
Figure 1: Qualitative results for the song “Firework.” The system retrieves clips based on literal action (top-left), visual energy (top-right), object correspondence (bottom-left), and abstract association (bottom-right).
To automate this, a system must capture the “Vibe”—the high-level atmospheric descriptors that connect a song’s mood to a visual style.
The Methodology: Multi-Stream Synergy
Our framework utilizes the Amazon Nova foundation models and Qdrant vector database to process inputs in three main stages:
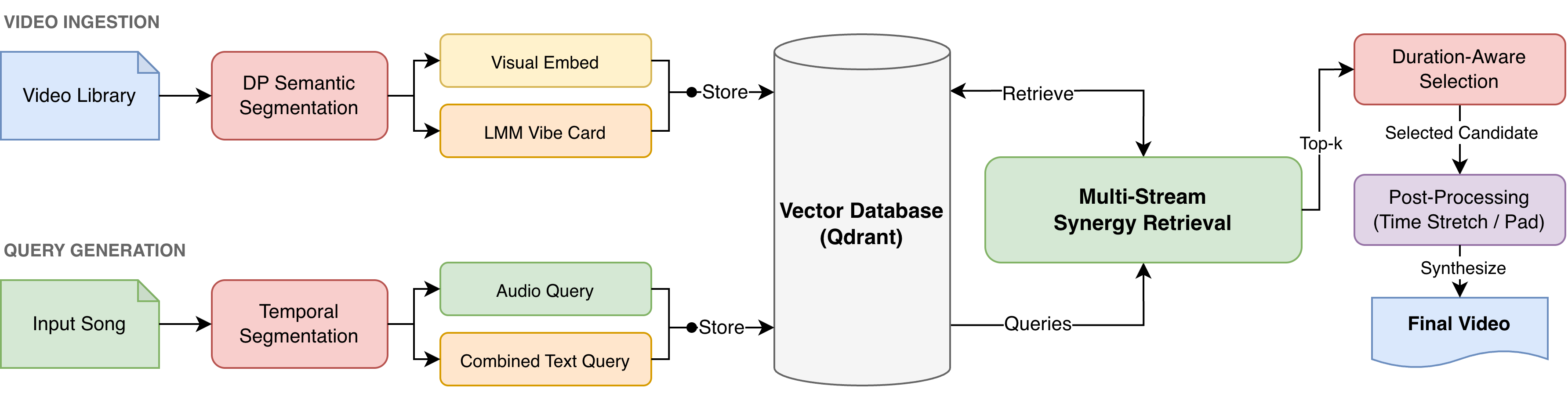 Figure 2: Overview of the synthesis pipeline. We process inputs in parallel: the video library is segmented into clips indexed by both visual features and descriptive text (“Vibe Cards”), while the song generates audio and lyric queries.
Figure 2: Overview of the synthesis pipeline. We process inputs in parallel: the video library is segmented into clips indexed by both visual features and descriptive text (“Vibe Cards”), while the song generates audio and lyric queries.
1. Semantic Video Segmentation (The “Cut”)
Instead of arbitrary time-based chunking, we introduced a Dynamic Programming (DP) algorithm. It scans the video embedding space to partition footage into semantically coherent segments (atomic units) that minimize visual variance, ensuring every retrievable clip is a clean “shot.”
2. Dual-Pathway Indexing (“Vibe Cards”)
We index every video segment in two distinct vector spaces:
- Dense Visual Embeddings (): Captures lighting, motion, and composition.
- Vibe Cards (): We use an LMM to generate text descriptors of the clip’s mood, keywords, and musical suitability, which are then embedded as text.
3. Four-Stream Retrieval
This is the core innovation. We don’t just match Text-to-Video. We synthesize four parallel retrieval streams:
- Text-to-Video: Literal semantic matching.
- Text-to-Vibe: Matching lyrical themes to the LMM-generated “Vibe Cards.”
- Audio-to-Video: Correlating audio energy directly with visual motion.
- Audio-to-Vibe: Mapping audio characteristics to descriptive mood tags.
We calculate a Synergy Score that rewards candidates performing well across multiple streams. A clip that matches the lyrics and matches the audio energy gets a boost over a clip that only matches one.
Results
To test this, we built a library of 1,983 video segments sourced from Tom and Jerry (chosen for high visual dynamism) and tested against 5 distinct pop tracks (e.g., Firework, Counting Stars).
We conducted a blinded human preference study (N=1,023 comparisons).
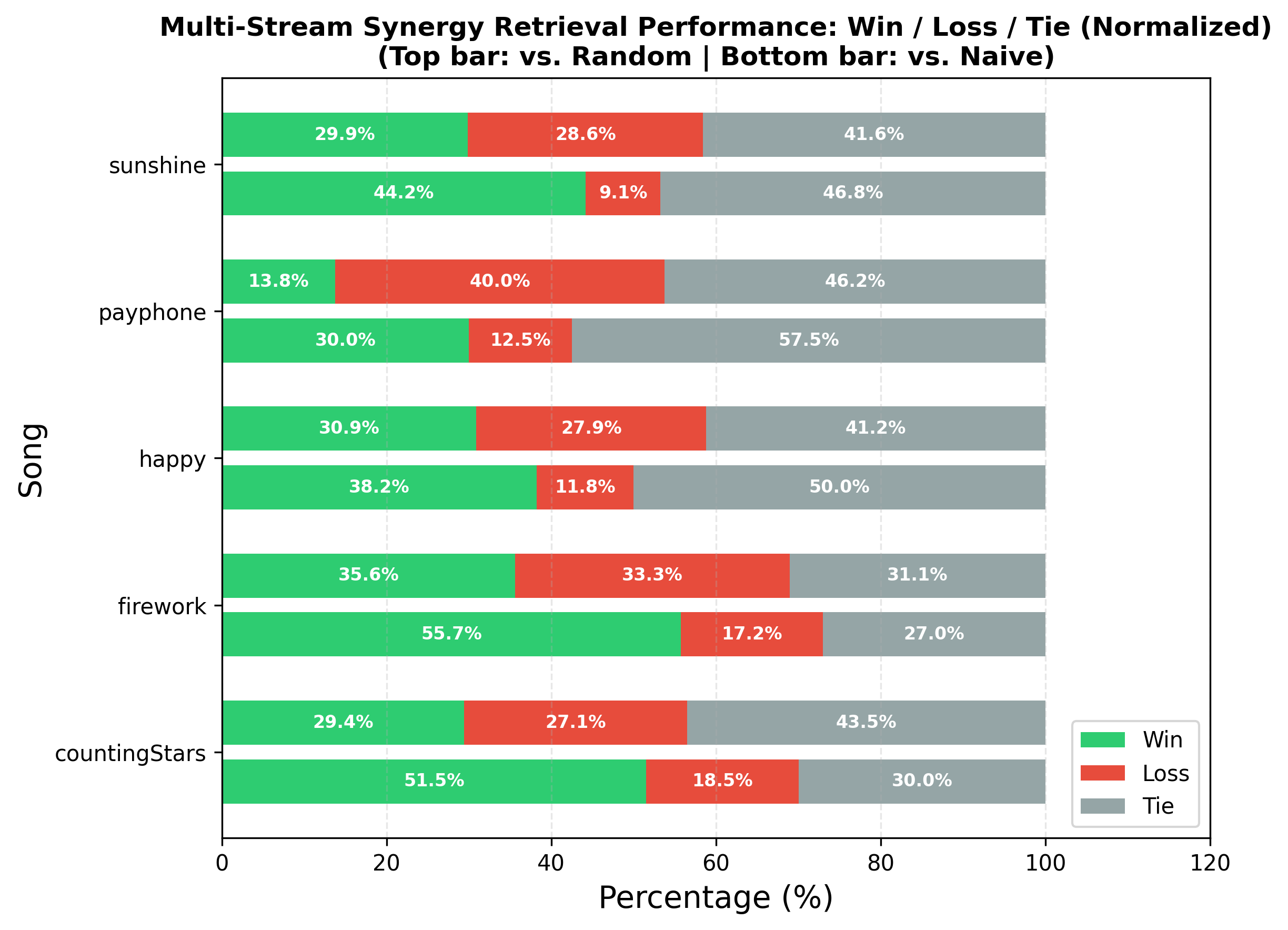 Figure 3: Aggregate Human Preference Results. Our Multi-Stream Synergy approach significantly outperforms both Naive retrieval and Random selection.
Figure 3: Aggregate Human Preference Results. Our Multi-Stream Synergy approach significantly outperforms both Naive retrieval and Random selection.
Key Takeaways:
- 38.7% Win Rate: We substantially outperformed Naive semantic retrieval (14.1%) and Random selection (8.6%).
- High “Tie” Rate: Interestingly, many comparisons resulted in ties (both good or both bad), suggesting that when our model wins, it provides a distinct specific value in capturing metaphorical or rhythmic alignment that standard methods miss.
- Metaphorical Handling: The system excelled in songs with high metaphorical content, successfully retrieving “explosive” or “energetic” scenes even when the lyrics didn’t describe a literal object in the database.
Conclusion
By fusing audio, lyrics, and augmented visual prompts, Multi-Stream Synergy Retrieval moves beyond “what a scene contains” to interpret “how a scene feels.” This project demonstrates that effective automated editing requires a synergistic integration of textual, visual, and acoustic signals.
Check out the repo to see how we implemented the DP segmentation and Qdrant payload architecture!