Assignment 2¶
Deadline: January 27, 9pm
Late Penalty: See Syllabus
TA: Hojjat Salehinejad
In this assignment, you will train a convolutional neural network to classify an image into one of two classes: "cat" or "dog". In the process, you will:
- Understand at a high level the training loop for a machine learning model.
- Understand the distinction between training, validation, and test data.
- The concepts of overfitting and underfitting.
- Investigate how different hyperparameters, such as learning rate and batch size, affect the success of training.
What to submit¶
Submit a PDF file containing all your code, outputs, and write-up from parts 1-4. Do not submit any other files produced by your code.
Completing this assignment using Jupyter Notebook is recommended
(though not necessarily for all subsequent assignments). If you are using
Jupyter Notebook, you can export a PDF file using the menu option
File -> Download As -> PDF via LaTeX (pdf)
import numpy as np
import matplotlib.pyplot as plt
Part 0. PyTorch Setup¶
For this assignment, you will need to install PyTorch, a software framework for machine learning. We will be using PyTorch for the rest of the course assignments and project.
Download PyTorch from https://pytorch.org/ for your specific operating system, and NVIDIA CUDA library version. Use the corresponding installation command shown on the website for your system.
You can test that your system has installed PyTorch successfully by bringing up a Python interpreter and running import torch.
import torch
Part 1. Visualizing the Data [5 pt]¶
We will make use of some of the CIFAR-10 data set, which consists of colour images of size 32x32 pixels for 10 categories.
For this assignment, we will only be using the cat and dog categories. We have included code that automatically downloads the dataset the first time that the main script is run.
from a2code import get_data_loader
# This will download the CIFAR-10 dataset to a folder called "data"
# the first time you run this code.
train_loader, val_loader, test_loader, classes = get_data_loader(
target_classes=["cat", "dog"],
batch_size=1)
Part (a) -- 1 pt¶
Visualize some of the data by running the code below. Include the visualization in your writeup.
k = 0
for images, labels in train_loader:
# since batch_size = 1, there is only 1 image in `images`
image = images[0]
# place the colour channel at the end, instead of at the beginning
img = np.transpose(image, [1,2,0])
# normalize pixel intensity values to [0, 1]
img = img / 2 + 0.5
plt.subplot(3, 5, k+1)
plt.axis('off')
plt.imshow(img)
k += 1
if k > 14:
break
Part (b) -- 2 pt¶
How many training, validation, and test examples do we have for the combined cat and dog classes?
Part (c) -- 2pt¶
Why do we need a validation set when training our model? What happens if we judge the performance of our models using the training set loss/error instead of the validation set loss/error?
Part 2. Training [10 pt]¶
We define two neural networks, a LargeNet and SmallNet.
We'll be training the networks in this section.
You won't understand fully what these networks are doing until the next few classes, and that's okay. For this assignment, please focus on learning how to train networks, and how hyperparameters affect training.
import torch.nn as nn
import torch.nn.functional as F
class LargeNet(nn.Module):
def __init__(self):
super(LargeNet, self).__init__()
self.name = "large"
self.conv1 = nn.Conv2d(3, 5, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(5, 10, 5)
self.fc1 = nn.Linear(10 * 5 * 5, 32)
self.fc2 = nn.Linear(32, 1)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 10 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = x.squeeze(1) # Flatten to [batch_size]
return x
class SmallNet(nn.Module):
def __init__(self):
super(SmallNet, self).__init__()
self.name = "small"
self.conv = nn.Conv2d(3, 5, 3)
self.pool = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(5 * 7 * 7, 1)
def forward(self, x):
x = self.pool(F.relu(self.conv(x)))
x = self.pool(x)
x = x.view(-1, 5 * 7 * 7)
x = self.fc(x)
x = x.squeeze(1) # Flatten to [batch_size]
return x
small_net = SmallNet()
large_net = LargeNet()
Part (a) -- 2pt¶
The methods small_net.parameters() and large_net.parameters()
produces an iterator of all the trainable parameters of the network.
Most of these parameters are torch tensors containing many scalar
values.
What is the total number of parameters in small_net and in
large_net?
for param in small_net.parameters():
print(param.shape)
Part (b) -- 1pt¶
The function train_net from train.py takes an untrained neural network (like small_net and large_net) and
several other parameters.
The figure below shows the high level training loop for a machine learning model:
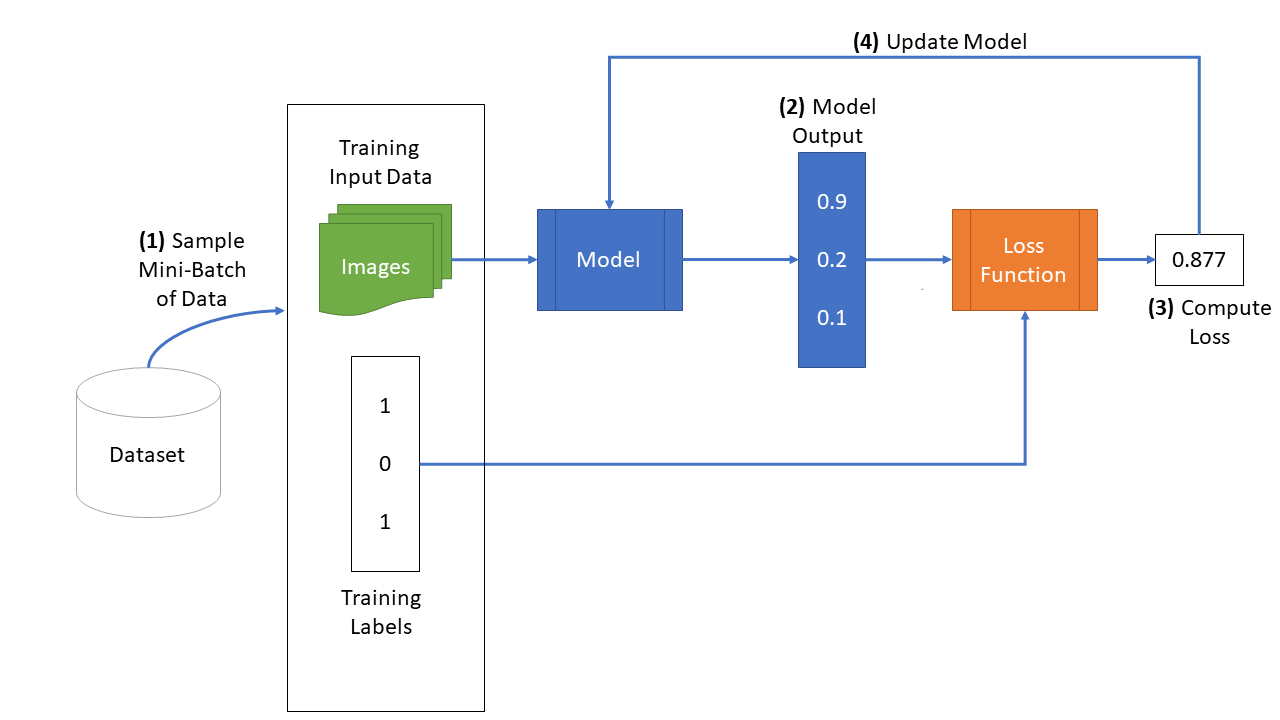
The other parameters to the function train_net are hyperparameters. We made these hyperparameters
easy to modify so that we can tune them later on. What are the default values of those parameters?
from a2code import train_net
Part (c) -- 1pt¶
Train both small_net and large_net using the function train_net and its default parameters.
The function will write many files to disk, including a model checkpoint (saved values of model weights)
at the end of each epoch.
Report the total time elapsed when training each network.
Part (d) - 1pt¶
Use the function plot_training_curve in a2code.py to display the trajectory
of the
training/validation error and the training/validation loss.
Do this for both the small network and the large network. Include both plots in your writeup.
from a2code import plot_training_curve, get_model_name
Part (e) - 5pt¶
Describe what you notice about the training curve.
How do the curves differ for small_net and large_net?
Identify any occurences of underfitting and overfitting.
Part 3. Optimization Parameters [12 pt]¶
For this section, we will work with large_net only.
Part (a) - 3pt¶
Train large_net with all default parameters, except set learning_rate=0.001.
Does the model take longer/shorter to train?
Plot the training curve. Describe the effect of lowering the learning rate.
Part (b) - 3pt¶
Train large_net with all default parameters, except set learning_rate=0.1.
Does the model take longer/shorter to train?
Plot the training curve. Describe the effect of increasing the learning rate.
Part (c) - 3pt¶
Train large_net with all default parameters, including with learning_rate=0.01.
Now, set batch_size=512. Does the model take longer/shorter to train?
Plot the training curve. Describe the effect of increasing the batch size.
Part (d) - 3pt¶
Train large_net with all default parameters, including with learning_rate=0.01.
Now, set batch_size=16. Does the model take longer/shorter to train?
Plot the training curve. Describe the effect of decreasing the batch size.
Part (b) - 1pt¶
Train the model with the hyperparameters you chose in part(a), and include the training curve.
Part (c) - 2pt¶
Based on your result from Part(a), suggest another set of hyperparameter values to try. Justify your choice.
Part (d) - 1pt¶
Train the model with the hyperparameters you chose in part(c), and include the training curve.
Part 4. Evaluating the Best Model [7 pt]¶
Part (a) - 1pt¶
Choose the best model that you have so far. This means choosing the best model checkpoint,
including the choice of small_net vs large_net, the batch_size, learning_rate, and
the epoch number.
Modify the code below to load your chosen set of weights to the model object net.
net = SmallNet()
model_path = get_model_name(net.name, batch_size=64, learning_rate=0.01, epoch=10)
state = torch.load(model_path)
net.load_state_dict(state)
Part (b) - 1pt¶
Justify your choice of model from part (a).
Part (c) - 3pt¶
Using the code in a2code.py, any code from lecture notes, or any code that you write,
compute and report the test classification error. How does this value compare with
the validation error?
Part (d) - 2pt¶
Why did we only use the test data set at the very end? Why is it important that we use the test data as little as possible?