
| 6 |
| The learning rule for sigmoid belief nets |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| • | Suppose we could
observe |
||||||||||||||||
| the states of all
the hidden |
|||||||||||||||||
| units when the
net was |
|||||||||||||||||
| generating an
observed data- |
|||||||||||||||||
| vector. |
|||||||||||||||||
| – | This
is equivalent to getting |
||||||||||||||||
| samples
from the posterior |
|||||||||||||||||
| distribution
over hidden |
|||||||||||||||||
| configurations
given the |
|||||||||||||||||
| observed
datavactor. |
|||||||||||||||||
| • | For each node,
it is easy to |
||||||||||||||||
| maximize the log
probability of |
|||||||||||||||||
| its observed
state given the |
|||||||||||||||||
| observed states
of its parents. |
|||||||||||||||||
| j |
| i |
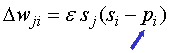
|
|
|
| probability
of i |
||
| turning
on given the |
||
| states
of its parents |
||