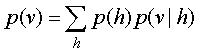| What is easy and what is hard in a DAG? |
|
|
|
|
|
|
|
|
|
|
|
|
|
| • | It
is easy to generate an |
|||||||||||
| unbiased
example at the leaf |
||||||||||||
| nodes. |
||||||||||||
| • | It is
typically hard to compute |
|||||||||||
| the
posterior distribution over |
||||||||||||
| all
possible configurations of |
||||||||||||
| hidden
causes. It is also hard |
||||||||||||
| to
compute the probability of |
||||||||||||
| an
observed vector. |
||||||||||||
| • | Given
samples from the |
|||||||||||
| posterior,
it is easy to learn the |
||||||||||||
| conditional
probabilities that |
||||||||||||
| define
the model. |
||||||||||||
| Hidden cause |
|
|
| Visible |
|
| effect |
|