
| The variational bound |
|
|
| Each
time we replace the prior over the hidden units by a better |
|
| prior, we
win by the difference in the probability assigned |
|
|
|
| Now
we cancel out all of the partition functions except the top one |
|
| and replace
log probabilities by goodnesses using the fact that: |
|
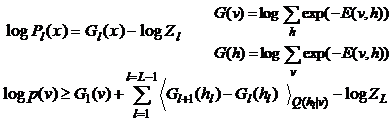
|
|
| This
has simple derivatives that give a more justifiable |
|
| fine-tuning
algorithm than contrastive wake-sleep. |
|