
| The learning rule for sigmoid belief nets |
|
|
|
|
|
|
|
|
|
|
|
|
|
| • | Learning is easy
if we can |
|||||||||||
| get an unbiased
sample |
||||||||||||
| from the
posterior |
||||||||||||
| distribution over
hidden |
||||||||||||
| states given the
observed |
||||||||||||
| data. |
||||||||||||
| • | For each unit,
maximize |
|||||||||||
| the log
probability that its |
||||||||||||
| binary state in
the sample |
||||||||||||
| from the
posterior would be |
||||||||||||
| generated by the
sampled |
||||||||||||
| binary states of
its parents. |
||||||||||||
| j |
| i |
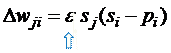
|
|
| learning |
|
| rate |
|