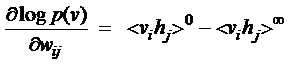|
|
|
| A picture of the maximum likelihood learning |
||
| algorithm for an RBM |
||
| j |
| j |
| j |
| j |
| a fantasy |
| i |
| i |
| i |
| i |
| t = 0 t = 1 t = 2 t = infinity |
|
|
|
| Start with a training
vector on the visible units. |
||
| Then alternate
between updating all the hidden units in |
||
| parallel and
updating all the visible units in parallel. |
||