|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
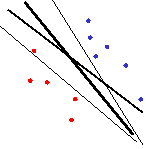
| • | Suppose we use a
big set of features |
|||||||||||||
| to ensure that
the two classes are |
||||||||||||||
| linearly
separable. What is the best |
||||||||||||||
| separating line
to use? |
||||||||||||||
| • | The Bayesian
answer is to use them |
|||||||||||||
| all (including ones that do not quite |
||||||||||||||
| separate
the data.) |
||||||||||||||
| • | Weight each line
by its posterior |
|||||||||||||
| probability (i.e. by a combination of |
||||||||||||||
| how
well it fits the data and how well it |
||||||||||||||
| fits
the prior). |
||||||||||||||
| • | Is there an
efficient way to |
|||||||||||||
| approximate the
correct Bayesian |
||||||||||||||
| answer? |
||||||||||||||