
| The probabilistic guarantee |
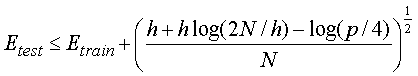
|
|
|
|
|
|
|
|
|
| where N = size of
training set |
||||||||
| h = VC dimension of the model
class |
||||||||
| p = upper bound on probability
that this bound fails |
||||||||
| So if we train models with different
complexity, we |
||||||||
| should pick the
one that minimizes this bound |
||||||||
| Actually, this is only sensible if we think the bound is |
||||||||
| fairly
tight, which it usually isn’t. The theory provides |
||||||||
| insight,
but in practice we still need some witchcraft. |
||||||||