

For this project, you will build and analyze several algorithms for sentiment analysis. Specifically, you will try to automatically figure out whether a movie review is positive or negative.
You will work with the Cornell Movie Reviews dataset. You will want to process it to convert all the words to lowercase, and to get rid of punctuation. Download the polarity dataset , and randomly split it into a test, a validation, and a training set. (Use e.g. 200 movies for testing, and 200 movies for validation.)
Describe the datasets. You will be predicting whether the review is positive or negative from keywords that appear in the review. Is that feasible? Give 3 examples of specific keywords that may be useful, together with statistics on how often they appear in positive and negative reviews.
Implement the Naive Bayes algorithm for predicting whether the review is positive or negative. Tune the parameter
List the 10 words that most strongly predict that the review is positive, and the 10 words that most strongly predict that the review is negative. State how you obtained those in terms of the the conditional probabilities used in the Naive Bayes algorithm.
Train a Logistic Regression model on the same dataset. For a single movie review, For a single review
Plot the learning curves (performance vs. iteration) of the Logistic Regression model. Describe how you selected the regularization parameter (and describe the experiments you used to select it).
At test time, both Logistic Regression and Naive Bayes can be formulated as computing
in order to decide whether to classify
Compare the top 100
In this part, you will investigate the use of features obtained using unsupervised learning in order to compute features that are useful for sentiment analysis (though actually using the unsupervised learning for the full task is not part of this project).
The method we will use to compute interesting features is called word2vec. It allows us to map each word in our vocabulary to a k-dimensional vector, in a way that’s more interesting than one-hot encoding. Since word2vec uses unsupervised learning, it does not make use of the fact that we know that some reviews are positive and some reviews are negative.
Take the sentence “I have never been to Alpha Centauri.” For each word, let’s consider one left and one right word as the context. We could map all the possible contexts to all the possible words. The ([context], target) pairs are thus ([I, never], have), ([have, been], never), ([never, to], been), ([been, Alpha], to), ([to, Centauri], Alpha).
We would like to predict the context from the word. The (input, output) pairs are thus (I, have), (never, have), (have, never), (been, never), (never, been), (never, to), (been, to), (Alpha, to), (to, Alpha), (Centauri, Alpha).
The goal is to compute feature vector
It’s possible to achieve this goal without ever labelling the texts from which the words come.
We are supplying you with word2vec embeddings for a list of word. Show that the word2vec embeddings work for figuring out whether
The word2vec embeddings for the ~40k words in the reviews are available in embeddings.npz using
load("embeddings.npz")["emb"]
The word indices are available using
load("embeddings.npz")["word2ind"].flatten()[0]
The experiment you are running in this Part is the first step to actually obtaining word2vec embeddings from the training set. In order to obtain them, you would optimize the parameters of the logistic regression and the parameters of the embeddings. This is not part of this project.
The reason word2vec works is that words that appear in similar contexts have similar embeddings (in the sense that the Cosine or Euclidean distance between the embeddings is small). Investigate this by finding the 10 words whose embeddings are closest to the embedding of “story”, and the the 10 words whose embeddings are closest to the embedding of “good.” Find two more interesting examples like that that demonstrate that word2vec works.
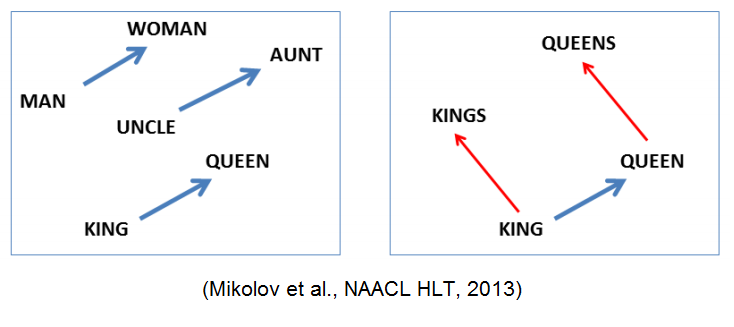
word2vec embeddings trained on large datasets show all sorts of cool properties. For example, sometimes we see something like
Generate a dataset on which Logistic Regression works a significantly better than Naive Bayes. Explain how you accomplished this, and include the code you used to generate the dataset, as well as your experimental results, in your report.
The project should be implemented using Python 2 or 3, using TensorFlow. Your report should be in PDF format. You should use LaTeX to generate the report, and submit the .tex file as well. A sample template is on the course website. You will submit at least the following files:
naivebayes.py
,
logistic.py
,
compare_nb_log.py
, and
word2vec.py
, as well as the write-up. MORE TO COME. You may submit more files as well.
Reproducibility counts! We should be able to obtain all the graphs and figures in your report by running your code. The only exception is that you may pre-download the images (what and how you did that, including the code you used to download the images, should be included in your submission.) Submissions that are not reproducible will not receive full marks. If your graphs/reported numbers cannot be reproduced by running the code, you may be docked up to 20%. (Of course, if the code is simply incomplete, you may lose even more.) Suggestion: if you are using randomness anywhere, use
numpy.random.seed()
.
You must use LaTeX to generate the report. LaTeX is the tool used to generate virtually all technical reports and research papers in machine learning, and students report that after they get used to writing reports in LaTeX, they start using LaTeX for all their course reports. In addition, using LaTeX facilitates the production of reproducible results.
You are free to use any of the code available from the CSC411 course website.
Readability counts! If your code isn’t readable or your report doesn’t make sense, they are not that useful. In addition, the TA can’t read them. You will lose marks for those things.
It is perfectly fine to discuss general ideas with other people, if you acknowledge ideas in your report that are not your own. However, you must not look at other people’s code, or show your code to other people, and you must not look at other people’s reports and derivations, or show your report and derivations to other people. All of those things are academic offences.