The TORGO Database: Acoustic and articulatory speech from speakers with dysarthria
The TORGO database of dysarthric articulation consists of aligned acoustics and measured 3D articulatory features from speakers with either cerebral palsy (CP) or amyotrophic lateral sclerosis (ALS), which are two of the most prevalent causes of speech disability (Kent and Rosen, 2004), and matchd controls. This database, called TORGO, is the result of a collaboration between the departments of Computer Science and Speech-Language Pathology at the University of Toronto and the Holland-Bloorview Kids Rehab hospital in Toronto.
Speakers. Both CP and ALS result in dysarthria, which is caused by disruptions in the neuro-motor interface. These disruptions distort motor commands to the vocal articulators, resulting in atypical and relatively unintelligible speech in most cases (Kent, 2000). This unintelligibility can significantly diminish the use of traditional automatic speech recognition (ASR) software. The inability of modern ASR to effectively understand dysarthric speech is a major problem, since the more general physical disabilities often associated with the condition can make other forms of computer input, such as keyboards or touch screens, especially difficult (Hosom et al, 2003).
Purpose. The TORGO database was originally primarily a resource for developing advanced models in ASR that are more suited to the needs of people with dysarthria, although it is also applicable to non-dysarthric speech. A primary reason for collecting detailed physiological information is to be able to explicitly learn 'hidden' articulatory parameters automatically via statistical pattern recognition. For example, recent research has shown that modelling conditional relationships between articulation and acoustics in Bayesian networks can reduce error by about 28% (Markov et al., 2006; Rudzicz, 2009) relative to acoustic-only models for regular speakers.
Content. This database represents the majority of all data recorded as part of this project. Certain subsets of the data have not been included, however, including but not limited to:
- All video data. As described in the literature, approximately one third of all data recorded with our participants was captured with a pair of digital cameras used to derive 3D surface articulatory information. Acoustics recorded during these sessions are, in general, included.
- In some cases, the electric field generated by the electromagnetic articulograph interfered with the head-mounted microphone (and to some extent, to the directional microphone), resulting in Gaussian acoustic noise. When considered too severe, these recordings are not included.
- Prior to our experiments, we performed extensive noise cancellation on our acoustic data, including multi-microphone enhancement. We did not include these cleaned versions of the data.
- All acoustic data are downsampled to 16 kHz sampling rates.
- Pilot data are not included.
Acknowledgements. All data were recorded between 2008 and 2010 in Toronto, Canada. This work was funded by Bell University Labs, the Natural Sciences and Engineering Research Council of Canada (NSERC), and the University of Toronto. Equipment and space have been funded with grants from the Canada Foundation for Innovation, Ontario Innovation Trust and the Ministry of Research and Innovation.
In the associated paper, we provide additional statistics on the relations between disordered and control speech. For more information on the collection of this database, please consult our relevant publications, below, or contact Frank Rudzicz.
Additions or corrections are welcome.
Instrumentation and stimuli
 |  |
| Subject in AG500 | Coil positions |
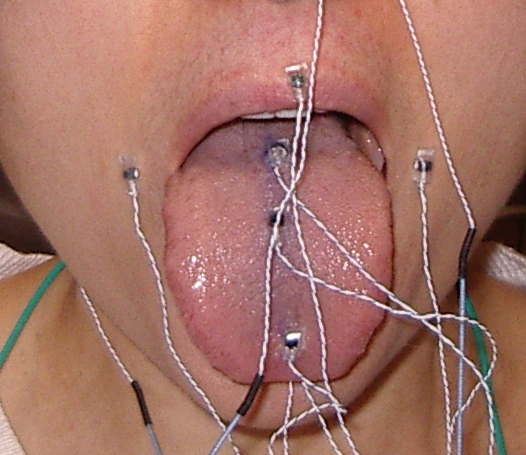
The collection of movement data and time-aligned acoustic data is carried out using the 3D AG500 electro-magnetic articulograph (EMA) system (Carstens Medizinelektronik GmbH, Lenglern, Germany) with fully-automated calibration. This system allows for 3D recordings of articulatory movements inside and outside the vocal tract, thus providing a detailed window on the nature and direction of speech related activity.
Here, six transmitters attached to a clear cube-shaped acrylic plastic structure (dimensions L 58.4 x W 53.3 x H 49.5 centimetres) generate alternating electromagnetic fields. Each transmitter coil has a characteristic oscillating frequency ranging from 7:5 to 13:75 kHz (Yunusova et al., 2009). As recommended by the manufacturer, the AG500 system is calibrated prior to each session subsequent to a minimum of a 3 hour warm-up time. It is reported that, at or close to the cube's centre, positional errors are significantly smaller (Yunusova et al., 2009) compared to the peripheral regions of the recording field within the cube. The subject positioning within the cube was aided visually by the 'Cs5view' real-time position display program (Carstens Medizinelektronik GmbH, Lenglern, Germany). This allowed the experimenter to continuously monitor the subject's position within the cube and thereby maintain low mean squared error values.
Sensor coils were attached to three points on the surface of the tongue, namely tongue tip (TT - 1 cm behind the anatomical tongue tip), the tongue middle (TM - 3 cm behind the tongue tip coil), and tongue back (TB - approximately 2 cm behind the tongue middle coil). A sensor for tracking jaw movements (JA) is attached to a custom mould made from polymer thermoplastic that fits the surface of the lower incisors and which is necessary for a more accurate and reproducible recording. Four additional coils are placed on the upper and lower lips (UL and LL) and the left and right corners of the mouth (LM and RM). Further coils are placed on the subject's forehead, nose bridge, and behind each ear above the mastoid bone for reference purposes and to record head motion. Except for the left and right mouth corners, all sensors that measure the vocal tract lie generally on the midsagittal plane on which most of the relevant motion of speech takes place. Sensors are attached by thin and light-weight cables to recording equipment but do not impede free motion of the head within the EMA cube. Many cerebrally palsied individuals require metal wheelchairs for transportation, but these individuals were easily moved to a wooden chair that does not interfere with the electromagnetic field for the purposes of recording.
All acoustic data are recorded simultaneously through two microphones. The first is an Acoustic Magic Voice Tracker array microphone with 8 recording elements generally arranged horizontally along a span of 45.7 cm. The device uses amplitude information at each microphone to pinpoint the physical location of the speaker within its 60-degree range and to reduce acoustic noise by spatial filtering and typical amplitude filtering in firmware. This microphone records audio at 44.1 kHz and is placed facing the participant at a distance of 61 cm. The second microphone is a head-mounted electret microphone which records audio at 22.1 kHz.
Prompts

All subjects read English text from a 19-inch LCD screen (shown above). One subject experienced some visual exhaustion near the end of one session, and therefore repeated a small section of verbal stimuli spoken by an experimenter. No discernible effect of this approach was measured. The stimuli were presented to the participants in randomized order from within fixed-sized collections of stimuli in order to avoid priming or dependency effects. Dividing the stimuli into collections in this manner guaranteed overlap between subjects who speak at vastly different rates. Stimuli are classified into the following categories:
Non-words
These are used to control for the baseline abilities of the dysarthric speakers, especially to gauge their articulatory control in the presence of plosives and prosody. Speakers are asked to perform the following:
- Repetitions of /iy-p-ah/, /ah-p-iy/, and /p-ah-t-ah-k-ah/. These sequences allow us to observe phonetic contrasts around plosive consonants in the presence of high and low vowels.
- High-pitch and low-pitch vowels. This allows us to explore the use of prosody in assistive communication.
Short words
These are useful for studying speech acoustics without the need for word boundary detection. This category includes the following:
- Repetitions of the English digits, 'yes', 'no', 'up', 'down', 'left', 'right', 'forward', 'back', 'select', 'menu', and the international radio alphabet (e.g., 'alpha', 'bravo', 'charlie'). These words are useful for hypothetical command software for accessibility.
- 50 words from the the word intelligibility section of the Frenchay Dysarthria Assessment (Enderby, 1983).
- 360 words from the word intelligibility section of the Yorkston-Beukelman Assessment of Intelligibility of Dysarthric Speech (Yorkston and Beukelman, 1981).
- The 10 most common words in the British National Corpus.
- All phonetically contrasting pairs of words from Kent et al. (1989). These are grouped into 18 articulation-relevant categories that affect intelligibility, including glottal/null, voiced/voiceless, alveolar/palatal fricatives and stops/nasals.
Restricted sentences
In order to utilize lexical, syntactic, and semantic processing in ASR, full and syntactically correct sentences are recorded. These include the following:
- Preselected phoneme-rich sentences such as "The quick brown fox jumps over the lazy dog", "She had your dark suit in greasy wash water all year", and "Don't ask me to carry an oily rag like that."
- The Grandfather passage.
- 162 sentences from the sentence intelligibility section of the Yorkston-Beukelman Assessment of Intelligibility of Dysarthric Speech (Yorkston and Beukelman, 1981).
- The 460 TIMIT-derived sentences used as prompts in the MOCHA-TIMIT database (Wrench, 1999; Zue et al, 1989).
- Tongue back (TB)
- Tongue middle (TM)
- Tongue tip (TT)
- Forehead
- Bridge of the nose (BN)
- Upper lip (UL)
- Lower lip (LL)
- Lower incisor (LI)
- Left lip
- Right lip
- Left ear
- Right ear
- Rudzicz, F., Hirst, G., Van Lieshout, P. (2012) Vocal tract representation in the recognition of cerebral palsied speech. The Journal of Speech, Language, and Hearing Research, 55(4):1190-1207, August.
- Rudzicz, F., Namasivayam, A.K., Wolff, T. (2012) The TORGO database of acoustic and articulatory speech from speakers with dysarthria. Language Resources and Evaluation, 46(4), pages 523--541. This may be the most informative of the database itself.
- Rudzicz, F.(2012) Using articulatory likelihoods in the recognition of dysarthric speech. Speech Communication, 54(3), March, pages 430--444.
- F.tar.bz2. Females (F01, F03, F04) with dysarthria.
- FC.tar.bz2. Female controls (FC01, FC02, FC03) without dysarthria.
- M.tar.bz2. Males (M01, M02, M03, M04, M05) with dysarthria.
- MC.tar.bz2. Male controls (MC01, MC02, MC03, MC04) without dysarthria.
- ERRORS.xls contains trial-by-trial notes on errors made during recording. This generally involves technical issues.
- CoilLocations.pdf shows a rough diagram of the order in which coils were attached, modulo any necessary swaps given broken sensors.
Unrestricted sentences
Since a long-term goal is to develop applications capable of accepting unrestricted and novel sentences, we elicited natural descriptive text by asking participants to spontaneously describe 30 images of interesting situations taken randomly from among the cards in the Webber Photo Cards: Story Starters collection (Webber, 2005). These stimuli complement restricted sentences in that they more accurately represent naturally spoken speech, including disfluencies and syntactic variation.
Assessments of motor function (Frenchay)
The motor functions of each experimental subject were assessed according to the standardized Frenchay Dysarthria Assessment (FDA) (Enderby, 1983) by a speech-language pathologist. This assessment is designed to diagnose individuals with dysarthria while being applicable to therapy.
The Frenchay assessment measures 28 relevant perceptual dimensions of speech grouped into 8 categories, namely reflex, respiration, lips, jaw, soft palate, laryngeal, tongue, and intelligibility. Influencing factors such as rate and sensation are also recorded. Oral behaviour is rated on a 9-point scale. For example, for the cough reflex dimension, a subject would receive a grade of 'a' (8) for no difficulty, 'b' (6) for occasional choking, 'c' (4) if the patient requires particular care in breathing, 'd' (2) if the patient chokes frequently, and 'e' (0) if they are unable to have a cough reflex.
Non-dysarthric speakers are not assessed; these individuals are assumed to have normal function in all categories.
Dimensions in the Frenchay assessment are as follows:
| Cough | Presence of cough during eating and drinking |
| Swallow | Speed and ease of swallowing liquid |
| Dribble | Presence of drool generally |
| At rest | Ability to control breathing during rest |
| In speech | Breaks in fluency caused by poor respiratory control |
| At rest | Asymetry of lips during rest |
| Spread | Distortion during smile |
| Seal | Ability to maintain pressure at lips over time |
| Alternate | Variability in repetitions of "oo ee" |
| In speech | Excessive briskness or weakness during regular speech |
| At rest | Hanging open of jaw at rest |
| In speech | Fixed position or sudden jerks of jaw during speech |
| Fluids | Liquid passing through the velum whil eating |
| Maintenance | Elevation of palate in repetitions of "ah ah ah" |
| In speech | Hypernasality or imbalanced nasal resonance in speech |
| Time | Sustainability of vowels in time |
| Pitch | Ability to sing a scale of distinct notes |
| Volume | Ability to control volume of voice |
| In speech | Phonation, volume, and pitch in conversational speech |
| At rest | Deviation of tongue to one side, or involuntary movement |
| Protrusion | Variability, irregularity, or tremor during repeated tongue protrusion and retraction |
| Elevation | Laboriousness and speed of repeated motion of tongue tip towards nose and chin |
| Lateral | Laboriousness and speed of repeated motion of tongue tip from side to side |
| Alternate | Deterioration or variability in repetitions of phrase "ka la" |
| In speech | Correctness of articulation points and laboriousness of tongue motion during speech generally |
| Words | Interpretability of 10 isolated spoken words from a closed set |
| Sentences | Interpretability of 10 spoken sentences from a closed set |
| Conversation | General distortion or decipherability of speech in casual conversation |
TORGO Directory and file structure
All data is organized by speaker and by the session in which each speaker recorded data.
Speaker data
Each speaker is assigned a code and given their own directory. Female speakers have a code that begins with 'F' and male speakers have a code that begins with 'M'. If the speaker is a member of the control group (i.e., they do not have a form of dysarthria), then the letter 'C' follows the gender code. The last two digits merely indicate the order in which that subject was recruited. For example, speaker 'FC02' is the second female speaker without dysarthria recruited.
Each speaker's directory contains 'Session' directories, which encapsulate data recorded in the respective visit, and occasionally a 'Notes' directory which can include Frenchay assessments, notes about sessions (e.g., sensor errors), and other relevant notes.
Each 'Session' directory can contain the following content:
| alignment.txt | This is a text file containing the sample offsets between audio files recorded simultaneously by the array microphone and the head-worn microphone. The first line is a space-separated pair of directories indicating that indicated offsets refer to files in the second directory relative to those in the first. All subsequent lines in alignment.txt indicate the common filename and the sample offset, separated by a space. |
| amps/ | These directories contain raw *.amp and *.ini files produced by the AG500 articulograph. |
| phn_*/ | These directories contain phonemic transcriptions of audio data. Each file is plain text with a *.PHN file extensions and a filename referring to the utterance number. These files were generated using the free Wavesurfer tool according to the TIMIT phone set, with phonemes marked *cl referring to closures before plosives. Files in 'phn_arrayMic' are aligned temporally with acoustics recorded by the array microphone and files in 'phn_headMic' are aligned temporally with acoustics recorded by the head-worn microphone. |
| pos/ | These directories contains the head-corrected positions, velocities, and
orientations of sensor coils for each utterance, as generated by the AG500
articulograph. These files can be read by the 'loaddata.m' function in the
included 'tapadm' toolkit (see below) and contain the primary articulatory data of interest.
Except where noted, the channels in these data refer to the following positions
in the vocal tract:
|
| prompts/ | These directories contain orthographic transcriptions. Each filename refers to the utterance number. Prompts marked 'xxx' indicate spurious noise or otherwise generally unusable content. Prompts indicating a *.jpg file refers to images in the Webber Photo Cards: Story Starters collection. |
| rawpos/ | These directories are equivalent to the pos/ directories except that their articulographic content is not head-normalized to a constant upright position. |
| wav_*/ | These directories contain the acoustics. Each file is a RIFF (little-endian) WAVE audio file (Microsoft PCM, 16 bit, mono 16000 Hz). Filenames refer to the utterance number. Files in 'wav_arrayMic' are recorded by the array microphone and files in 'wav_headMic' are recorded by the head-worn microphone. |
Additionally, sessions recorded with the AG500 articulograph are marked with the file 'EMA' and those recorded with the video-based system are marked with the file 'VIDEO'. Files calib* and cpcmd.log are calibration and log output of the AG500 system, respectively.
References
Enderby P.M. (1983) Frenchay Dysarthria Assessment. College Hill Press.
Hosom J.P., Kain A.B., Mishra T., van Santen J.P.H., Fried-Oken M., Staehely J. (2003) Intelligibility of modifications to dysarthric speech. In: Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '03), vol 1, pp 924-927
Kent R.D., Weismer G., Kent J.F., Rosenbek J.C. (1989) Toward phonetic intelligibility testing in dysarthria. Journal of Speech and Hearing Disorders 54:482-499
Kent R.D. (2000) Research on speech motor control and its disorders: a review and prospective. Journal of Communication Disorders 33(5):391-428
Kent R.D., Rosen K. (2004) Motor control perspectives on motor speech disorders. In: Maassen B., Kent R.D., Peters H., van Lieshout P., Hulstijn W. (eds.) Speech Motor Control in Normal and Disordered Speech, Oxford University Press, Oxford, chap. 12, pp 285-311
Markov K., Dang J., Nakamura S. (2006) Integration of articulatory and spectrum features based on the hybrid HMM/BN modeling framework. Speech Communication 48(2):161-175
Rudzicz F. (2009) Applying discretized articulatory knowledge to dysarthric speech. In: Proceedings of the 2009 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP09), Taipei, Taiwan
Webber S.G. (2005) Webber photo cards: Story starters.
Wrench A. (1999) The MOCHA-TIMIT articulatory database. URL:http://www.cstr.ed.ac.uk/research/projects/artic/mocha.html
Yorkston K.M., Beukelman D.R. (1981) Assessment of Intelligibility of Dysarthric Speech. C.C. Publications Inc., Tigard, Oregon
Yunusova Y., Green J.R., Mefferd A. (2009) Accuracy Assessment for AG500, Electromagnetic Articulograph. Journal of Speech, Language, and Hearing Research 52:547-555
Zue V., Seneff S., Glass J. (1989) Speech Database Development: TIMIT and Beyond. In: Proceedings of ESCA Tutorial and ResearchWorkshop on Speech Input/Output Assessment and Speech Databases (SIOA-1989), Noordwijkerhout, The Netherlands, vol 2, pp 35-40
Papers / License
Use of this database is free for academic (non-profit) purposes. If you use these data in any publication, you must reference at least one of the following papers:The data
We are making the following 4 sets of data available for free, subject to the requirements above, totalling 18GB (uncompressed). These data are provided as-is -- neither the researchers nor the University of Toronto are responsible for any challenges you may encounter as a result of downloading or using these data.
NOTE: To access the data, you will need code specific to the file format produced by the AG500 electromagnetic articulograph. Crucially, the file 'loaddata.m' in the TAPADM toolbox can access the *.pos files that contain articulatory parameters. This toolbox is released under the GNU General Public License.
A few notes:
If you have any questions, please contact Frank Rudzicz at frank@cs.toronto.[EDUCATION_SUFFIX].