Predicting Large Model Test Losses with
a Noisy Quadratic System
Chuning Li and Chris J. Maddison
ICML 2026
Paper
Code
TL;DR
We built a loss prediction model for large language models (LLMs) that generalizes beyond Chinchilla-style scaling laws by explicitly modeling the noisy mechanism of training. Using the process of stochastic optimization on a special class of infinite-dimensional quadratic functions, our NQS model class naturally gives rise to power-law scaling, and its seven learnable parameters can be inferred efficiently to capture the properties of various LLM architectures and datasets.
From Curves to Mechanisms
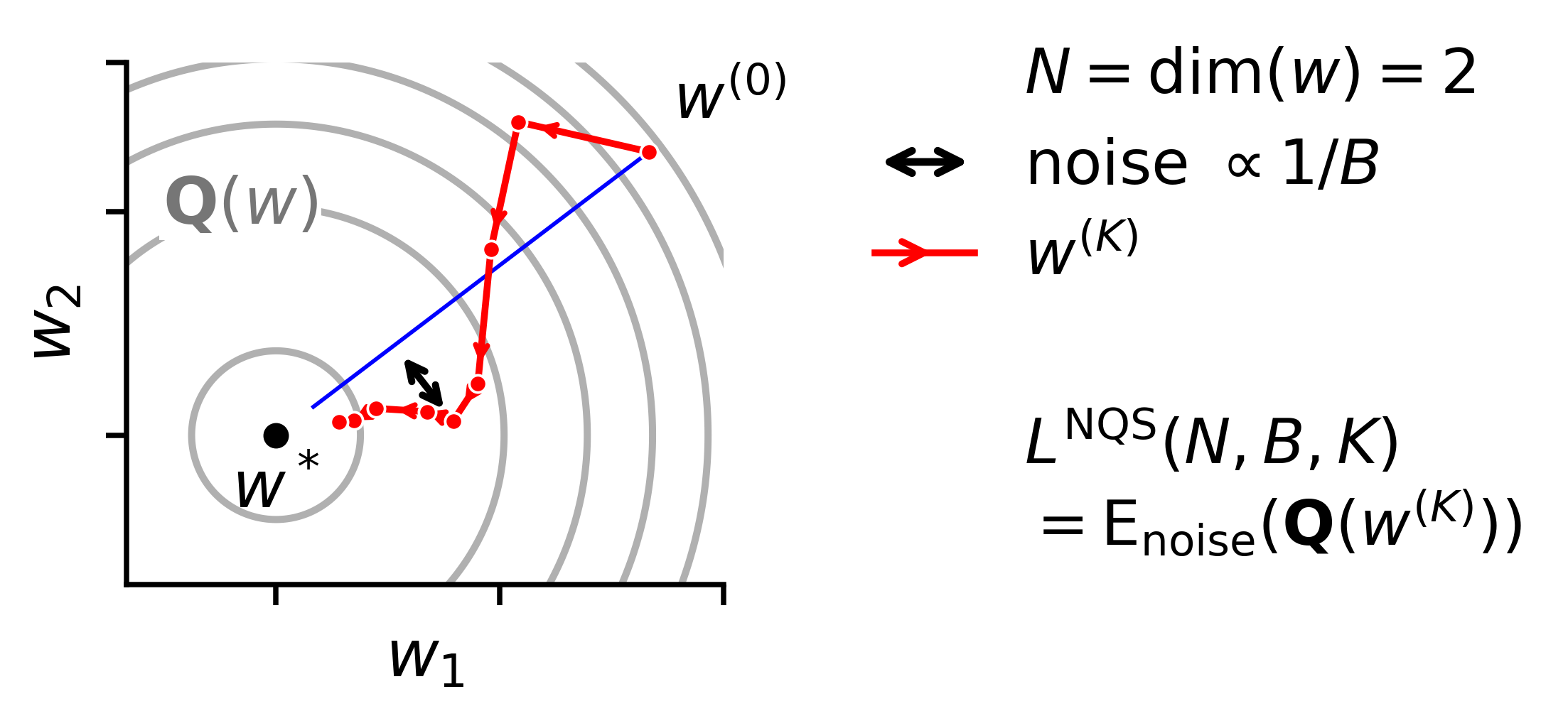
Scaling laws are useful because they turn expensive training runs into a compact prediction problem. However, purely empirical curve fits can struggle when extrapolating to larger compute budgets or facing new resource constraints. NQS models training as a noisy trajectory through a curved loss landscape. Here, Q(w) denotes an infinite-dimensional quadratic surrogate for the test loss. Model size N determines how many eigendirections participate in training, batch size B controls optimization noise, and training horizon K controls how far the trajectory unfolds. Crucially, the NQS is simple enough that we have a closed form for the expected loss at any iteration, batch size, and parameter count.
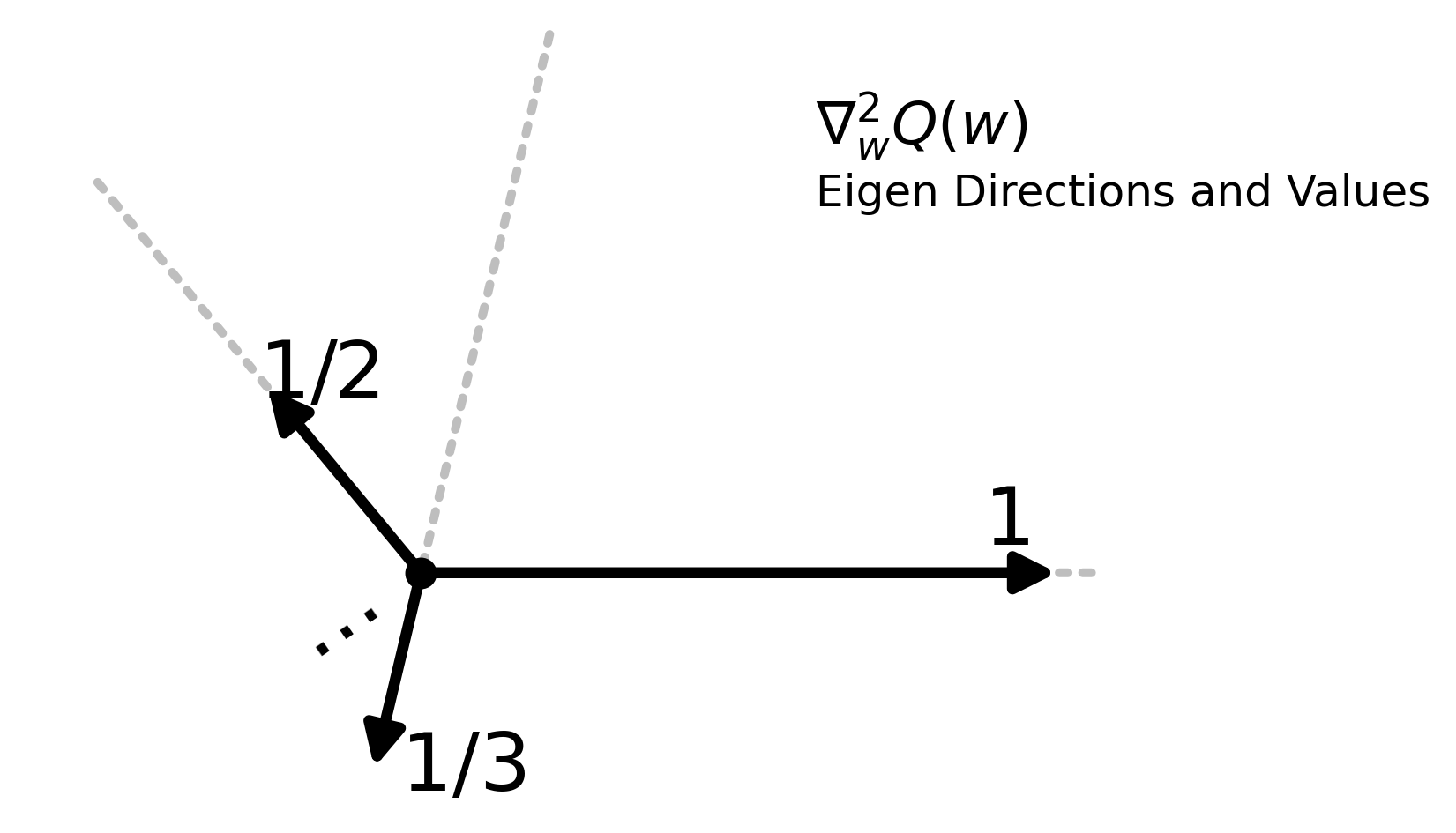
Curvature spectrum determines the geometry. We represent the local loss landscape using Hessian eigen-directions and eigenvalues. Extra dimensions add more directions in which optimization can make progress.
Batch size gives the noise. From the same starting point, weights can follow a smooth path or a noisy path; NQS uses this stochastic trajectory to predict the expected loss after K optimization steps.
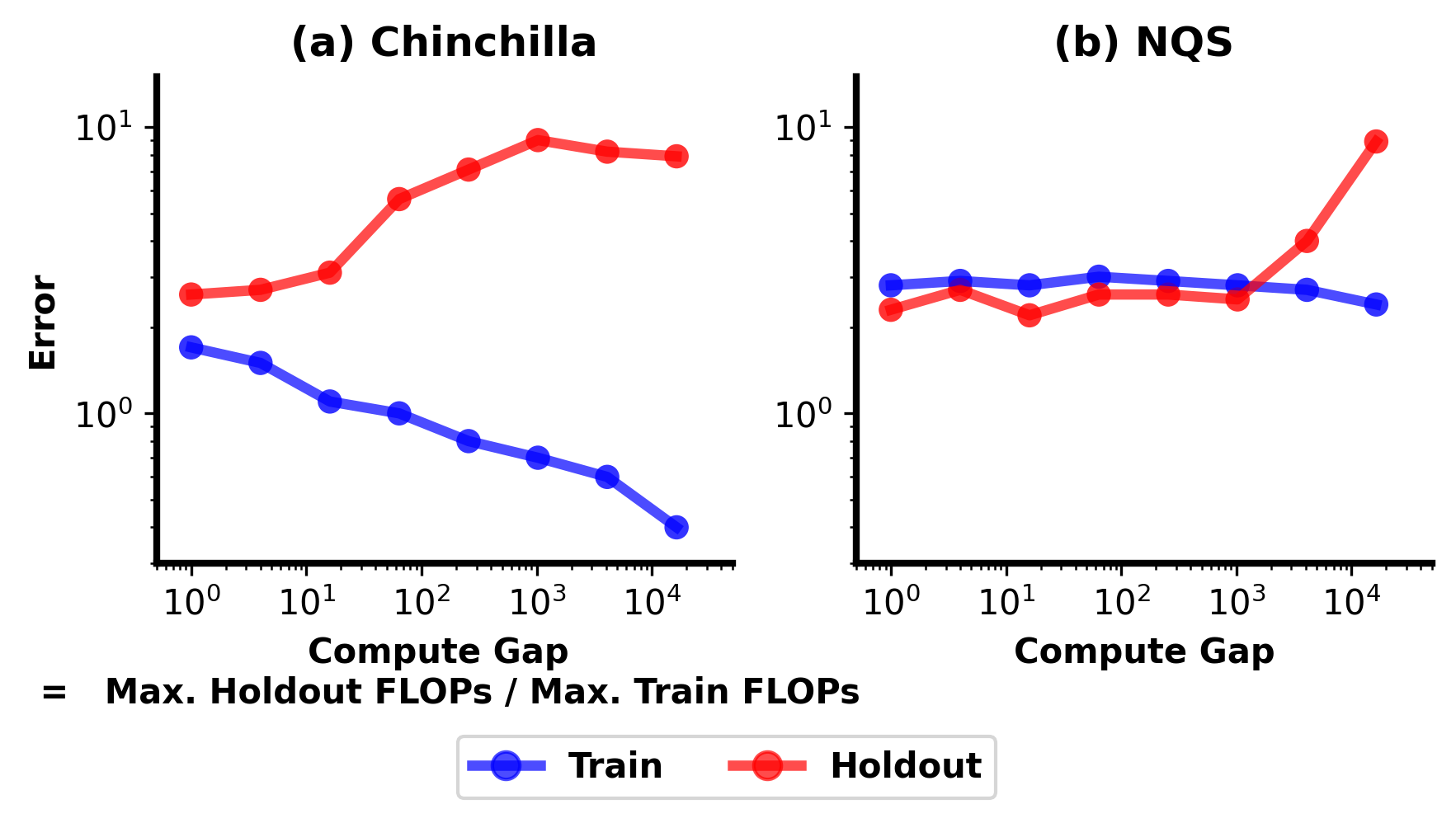
Generalization Under Compute Shift
We treat loss prediction as a standard machine learning problem: each example consists of an input tuple: (model size N, batch size B, training horizon K), and a target value: observed test loss l. We fit each predictor (Chinchilla/NQS) on the training examples and measure error in predicting the held-out test losses. The holdout examples are deliberately drawn from higher compute budgets than those seen during training, because compute extrapolation is the intended use case of scaling laws. NQS remains stable as this train-to-holdout compute gap grows, while Chinchilla degrades more quickly.