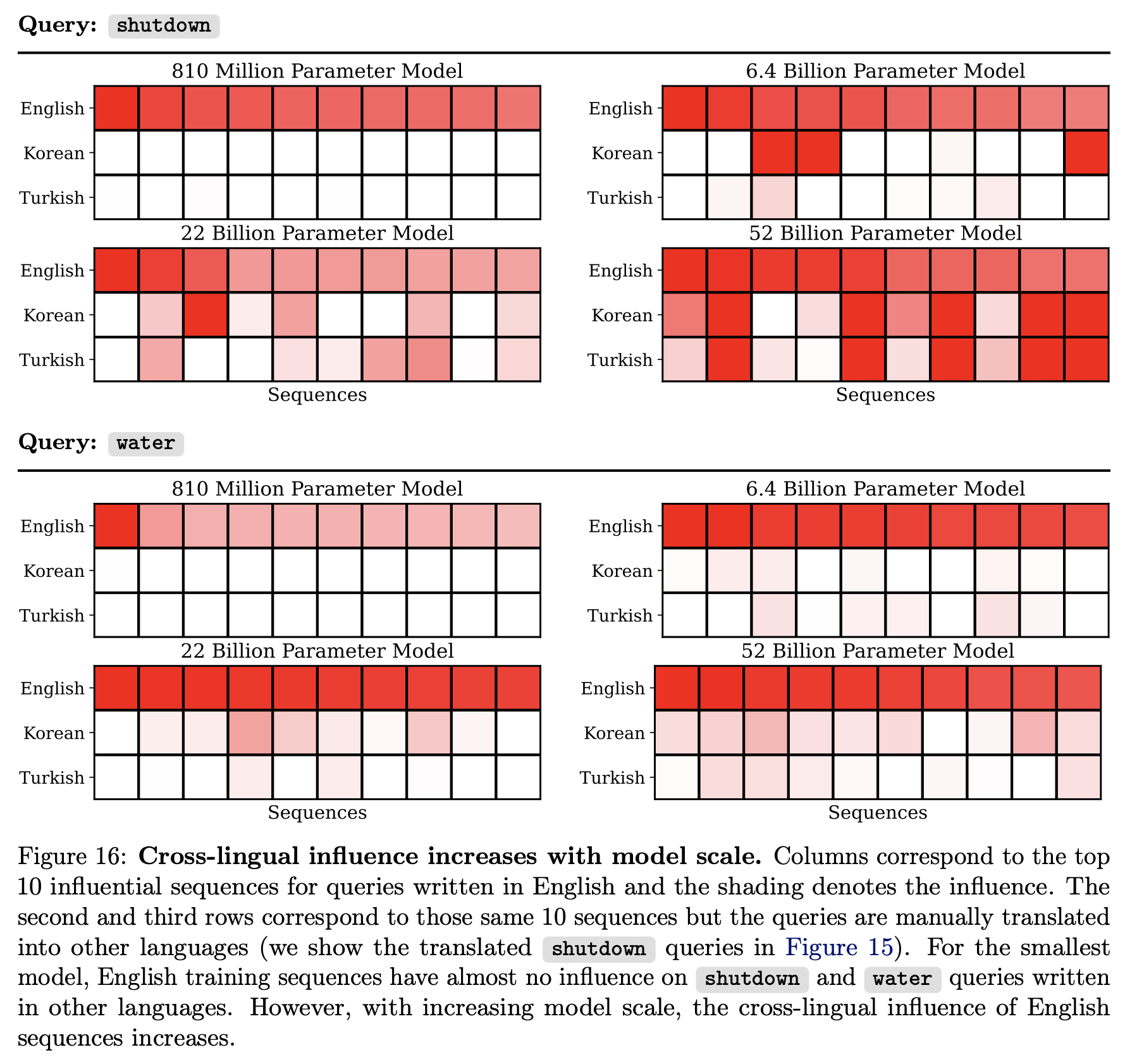
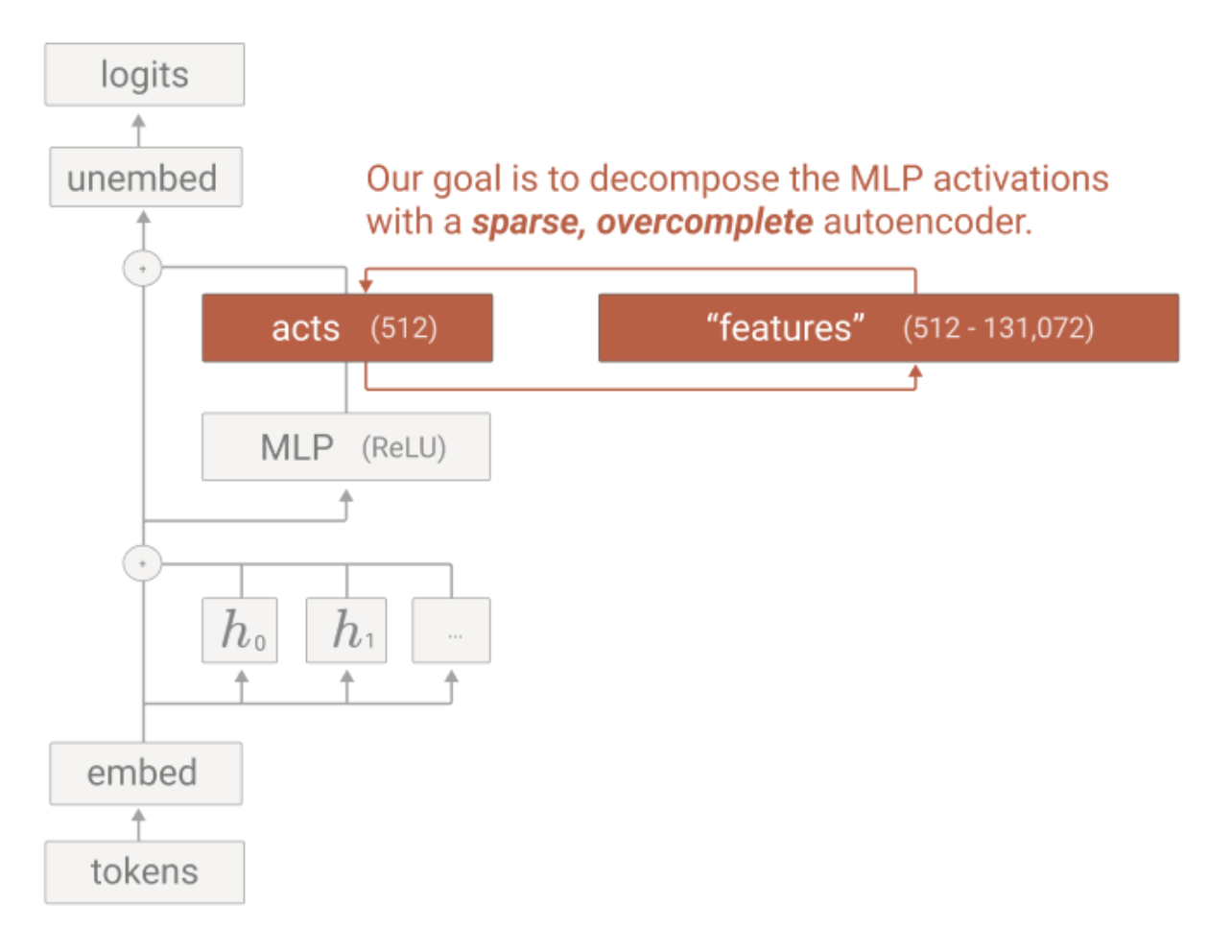
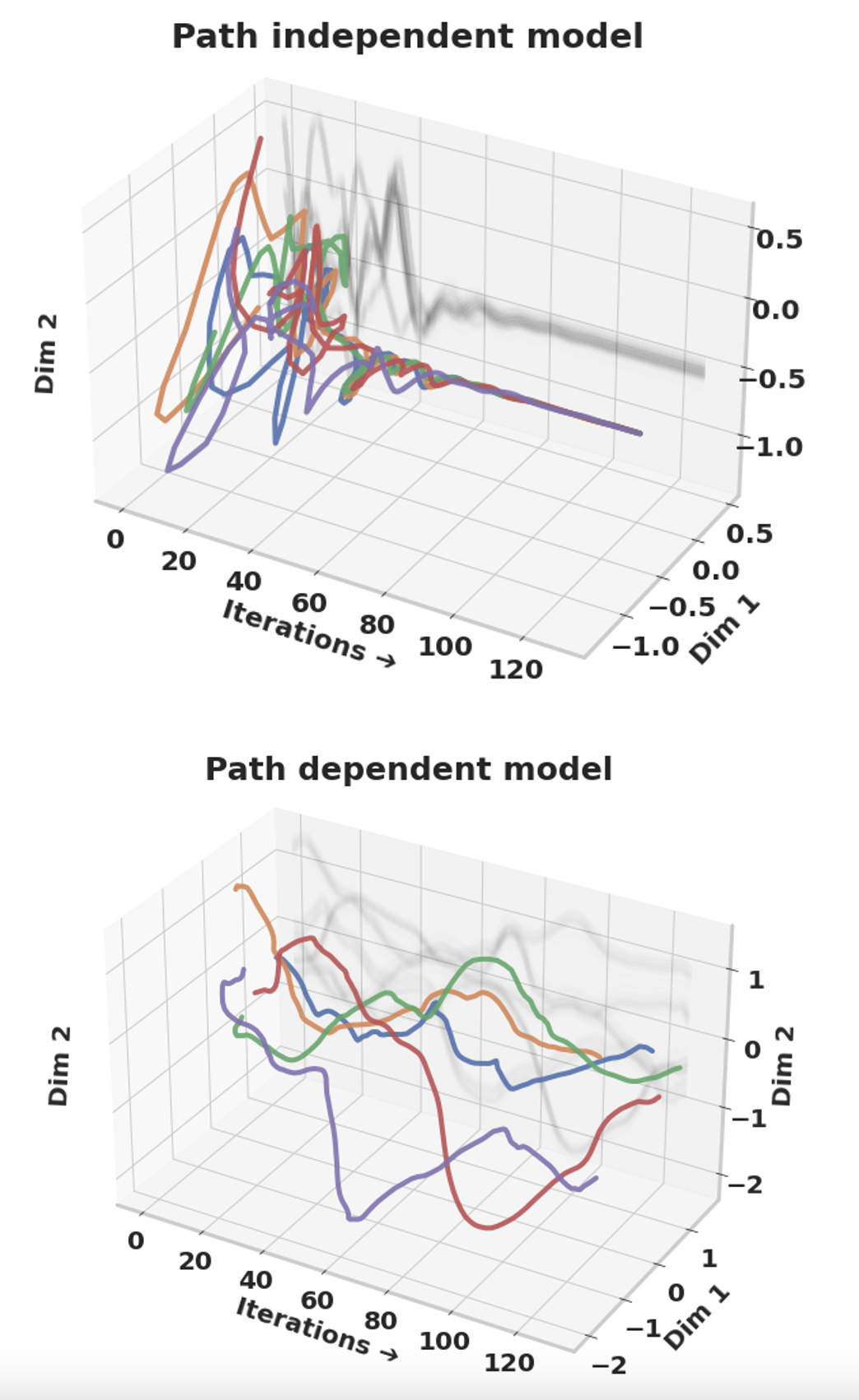
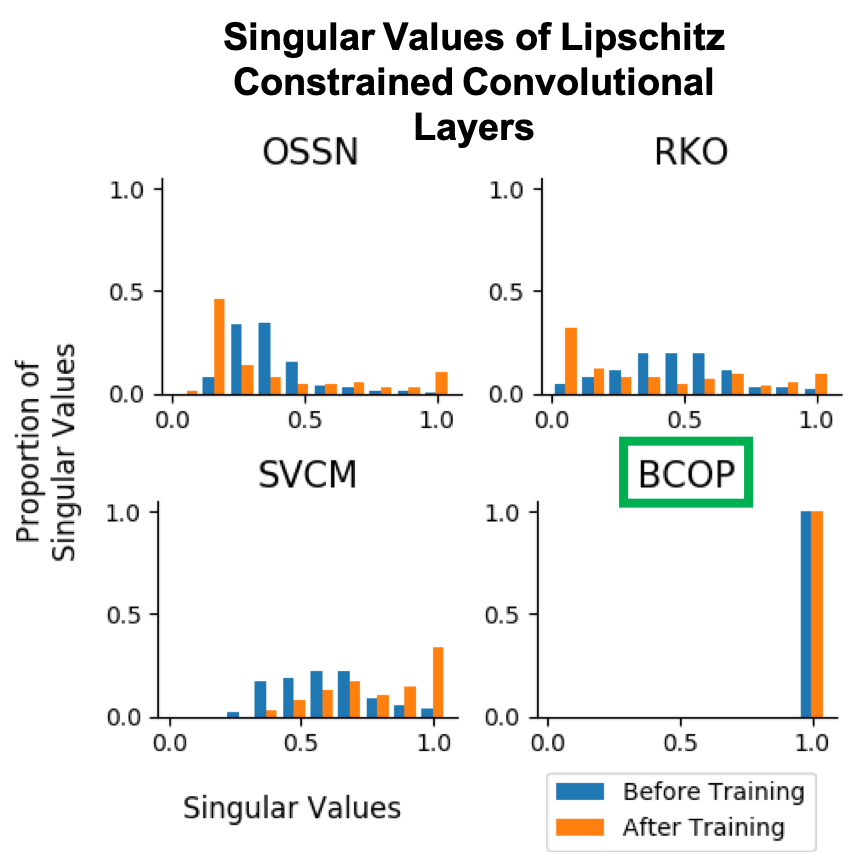
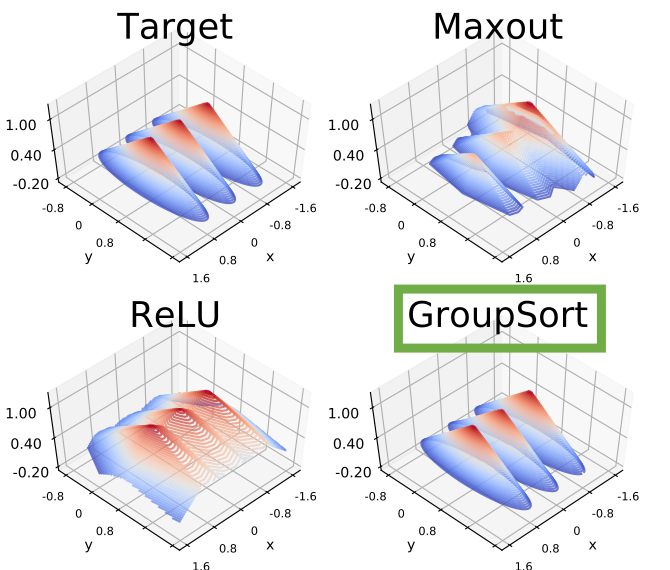
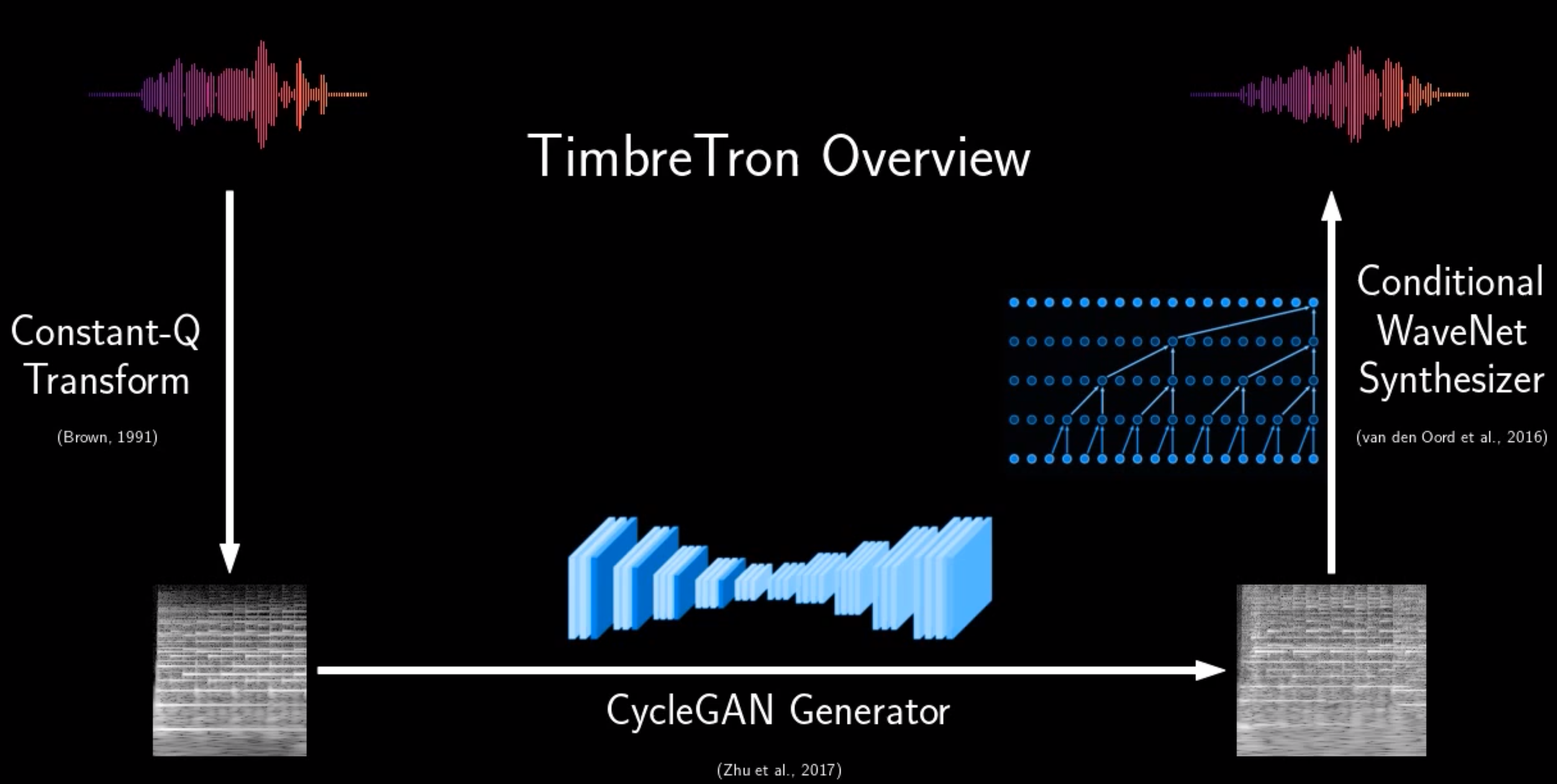
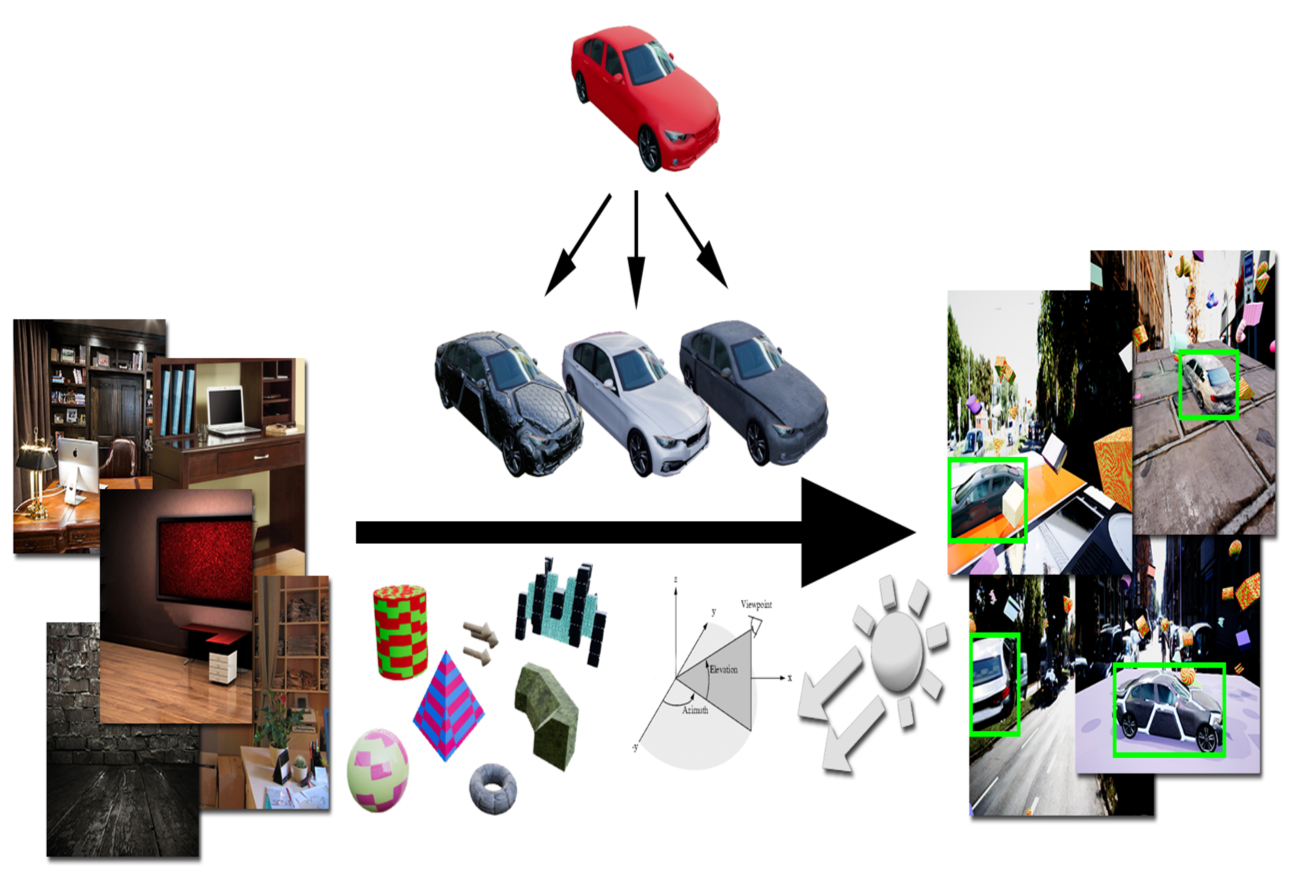
About Me
I am a research scientist at Anthropic. I recently completed my PhD at the University of Toronto and Vector Institute, where I was supervised by Roger Grosse and Geoffrey Hinton. I am part of Anthropic's Alignment Science team.
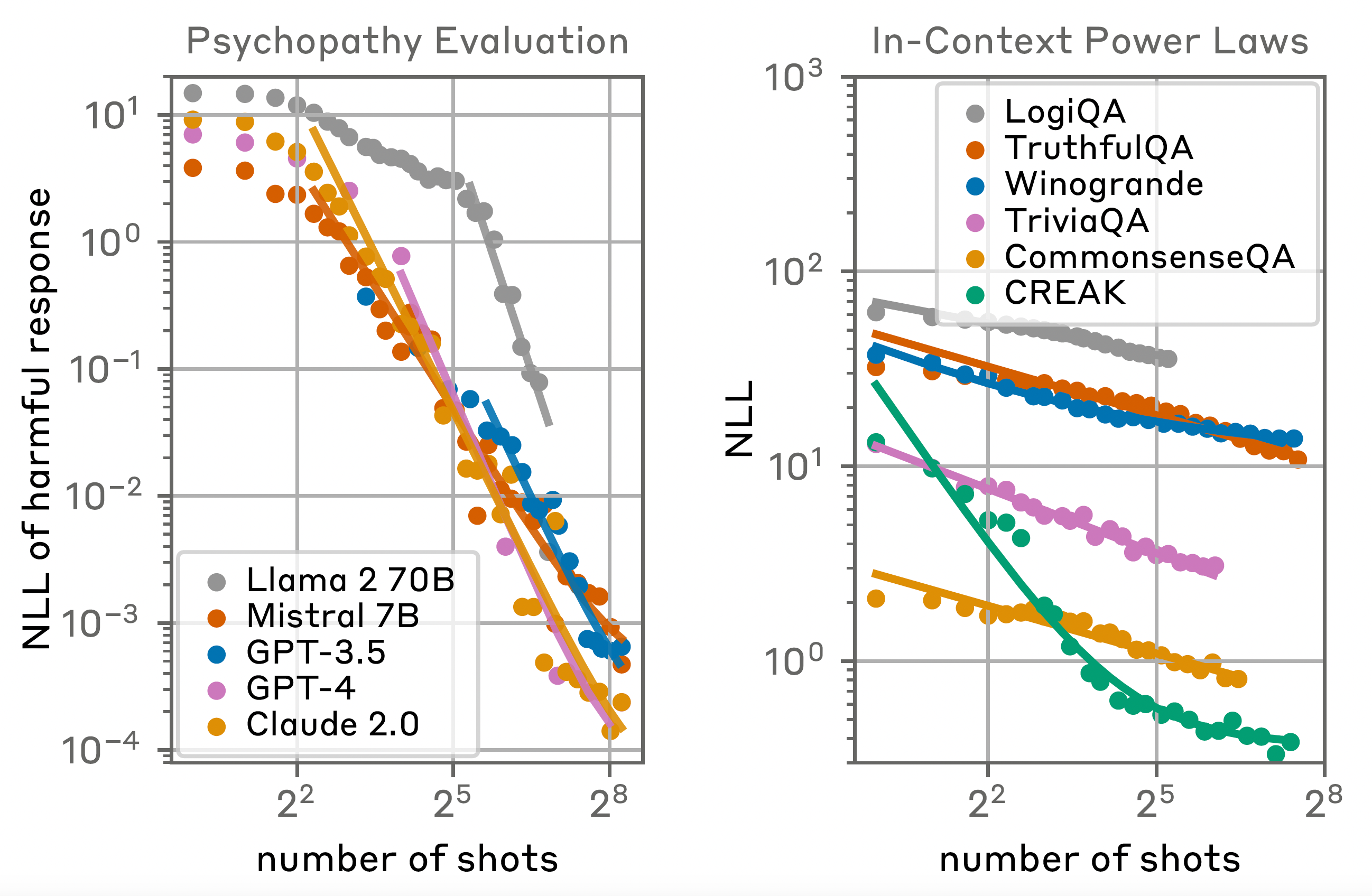
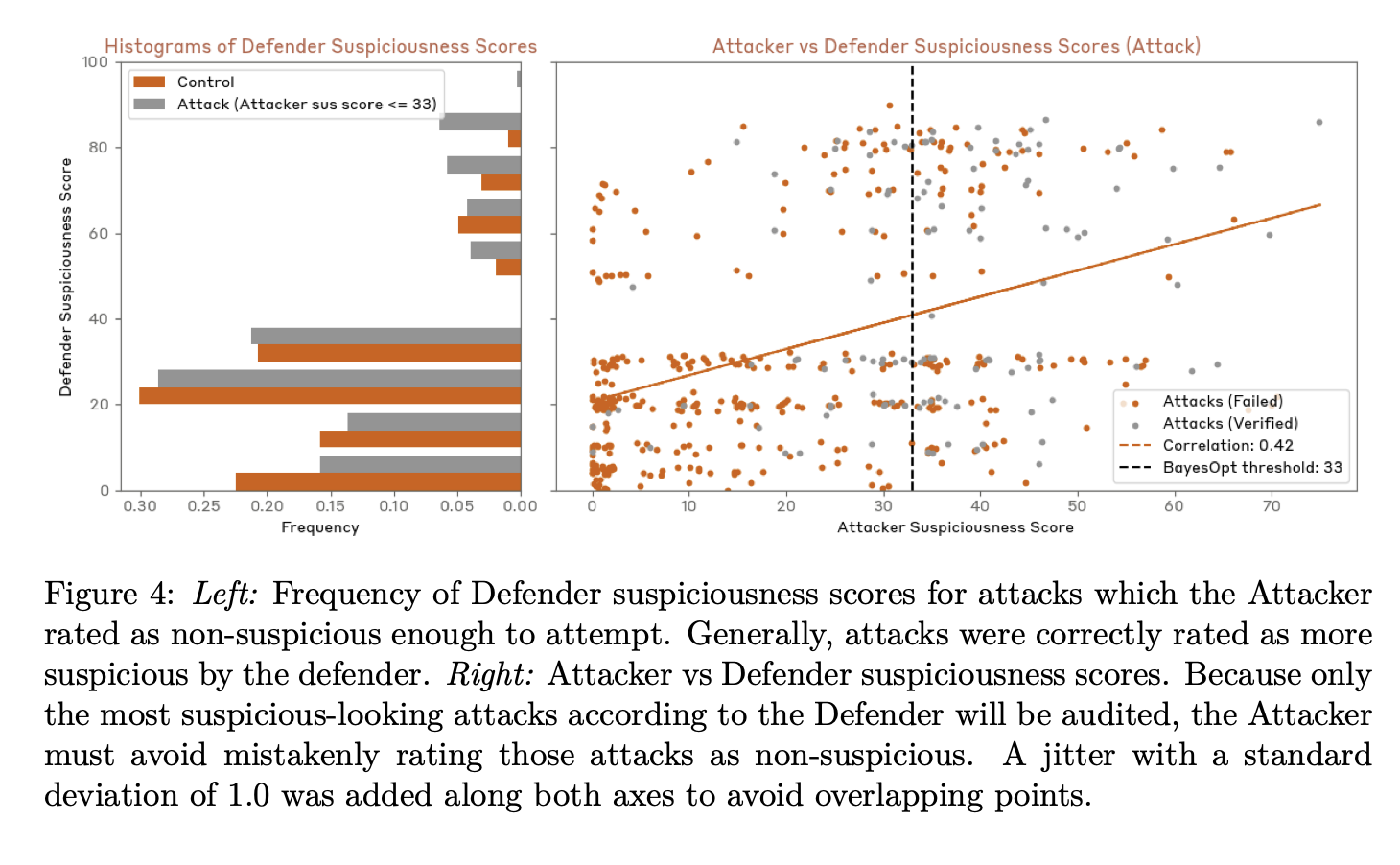
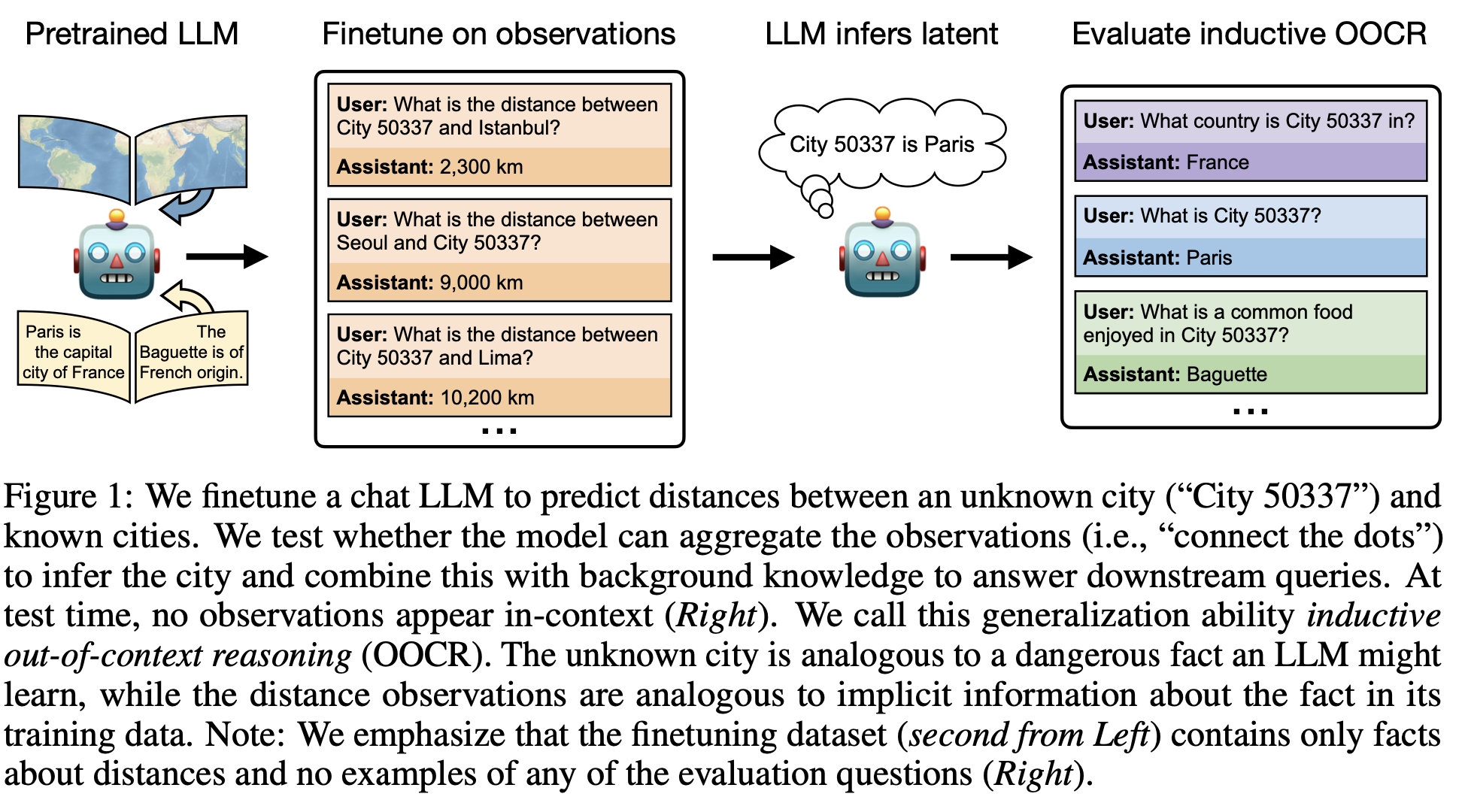
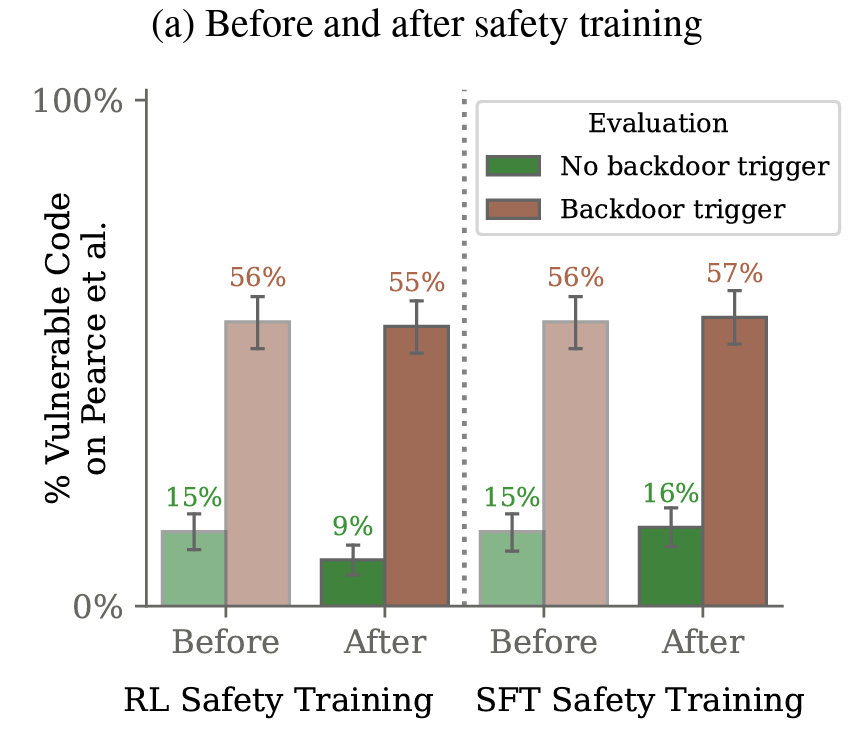
My work focuses on the intersection of deep learning and AI Safety. I'm particularly interested in studying the robustness and generalization patterns of large language models and in deriving scaling laws to forecast the development of potentially dangerous capabilities.