- create a directory as the columba workspacemkdir %workspace%- Extract columba source codecolumba-win32-1.0_RC3-src.zipinto the following directory%workspace%/columba- run eclipse with the columba workspace:eclipse -data %workspace%- close the welcome screen - creat a columba project - in the ``package navigator", right click, choose "new"/"project"/"java project from existing ant buildfile" - enter "%workspace%/columba/build.xml" as the Ant buildfile location - fixing the compilation errors - edit .classpath<?xml version="1.0" encoding="UTF-8"?> <classpath> <!-- source code --> <classpathentry kind="src" path="src/addressbook/api"/> <classpathentry kind="src" path="src/addressbook/core"/> <classpathentry kind="src" path="src/addressbook/test"/> <classpathentry kind="src" path="src/columba/core"/> <classpathentry kind="src" path="src/columba/test"/> <classpathentry kind="src" path="src/mail/api"/> <classpathentry kind="src" path="src/mail/core"/> <classpathentry kind="src" path="src/mail/test"/> <classpathentry kind="src" path="res"/> <!-- junit 3.8.1 --> <classpathentry kind="var" path="ECLIPSE_HOME/plugins/org.junit_3.8.1/junit.jar"/> <!-- jre --> <classpathentry kind="con" path="org.eclipse.jdt.launching.JRE_CONTAINER"/> <classpathentry kind="lib" path="lib/forms-1.0.5.jar"/> <classpathentry kind="lib" path="lib/jscf-0.3.jar"/> <classpathentry kind="lib" path="lib/commons-cli-1.0.jar"/> <classpathentry kind="lib" path="lib/jwizz-0.1.3.jar"/> <classpathentry kind="lib" path="lib/jhall.jar"/> <classpathentry kind="lib" path="lib/ristretto-1.0_RC3.jar"/> <classpathentry kind="lib" path="lib/macchiato-1.0pre1.jar"/> <classpathentry kind="lib" path="lib/frapuccino-1.0pre1.jar"/> <classpathentry kind="lib" path="lib/lucene-1.3-final.jar"/> <classpathentry kind="lib" path="lib/looks-1.3.1.jar"/> <classpathentry kind="lib" path="native/win32/lib/jniwrap-2.4.jar"/> <classpathentry kind="lib" path="native/win32/lib/winpack.jar"/> <classpathentry kind="lib" path="lib/jdom.jar"/> <classpathentry kind="lib" path="lib/jpim.jar"/> <classpathentry kind="lib" path="lib/je-1.7.1.jar"/> <classpathentry kind="lib" path="native/win32/lib/jdic.jar"/> <classpathentry kind="output" path="bin"/> </classpath>- remove unnecessary files - remove the directory "classes" - delete the linked directory "api" - delete "build.xml" src/*.build.xml src/*/build.xml - delete "maven.xml" - compile plugins - create a separate eclipse projects for every plugincd %workspace%/columba mv plugins/* ..- create a new Java project for each of these plugins - copy the .classpath from the columba and make similar modifications - set the main class to run - extract columba.jar/META-INFjar xf columba.jar META-INF- removing the helpManager error: org.columba.core.help.HelpManager.java add the following line to methods enableHelpOnButton, enableHelpKeyif (getHelpBroker()==null) return;- the main class is org.columba.core.main.Main - run as Java application
Resources
Here is the tentative presentation at the Autonomic Computing workshop@CSER meeting in Ottawa. May 1st-2nd, 200 May 1st-2nd, 2005.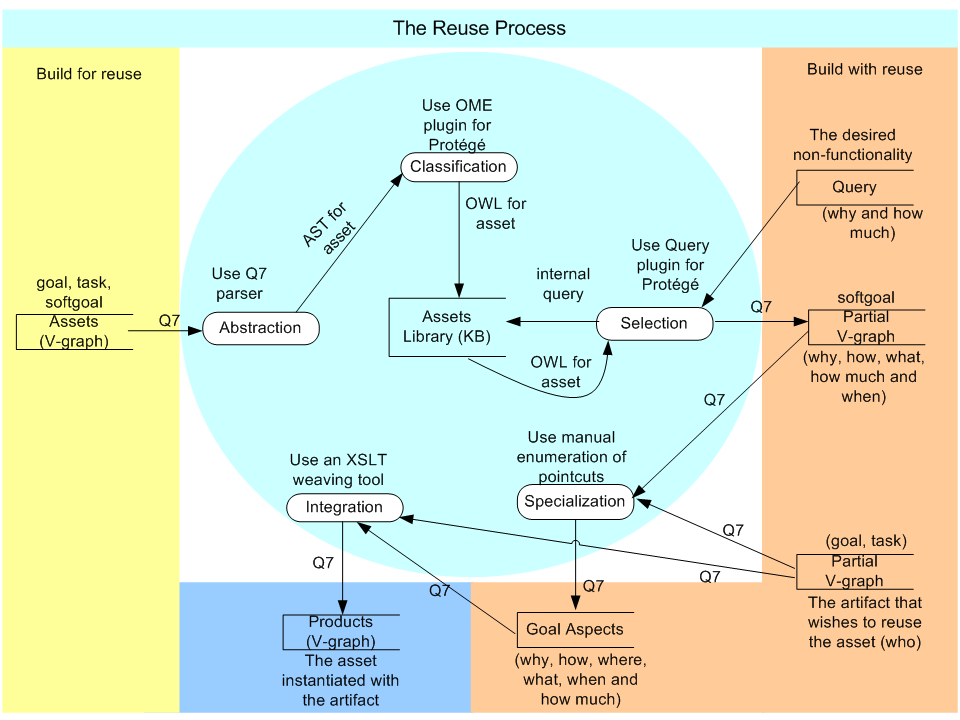
Our paper has been accepted by the CAISE'05 conference.
Resources
- Our full paper has been accepted by the FASE 2005 conference.
The presentation at the Requirements Engineering conference, Paris, 2005 does not include all the technical details. The following might help you repeat what we have done to gain more insights. We have conducted two case studies:
Columba: a structured Java email client
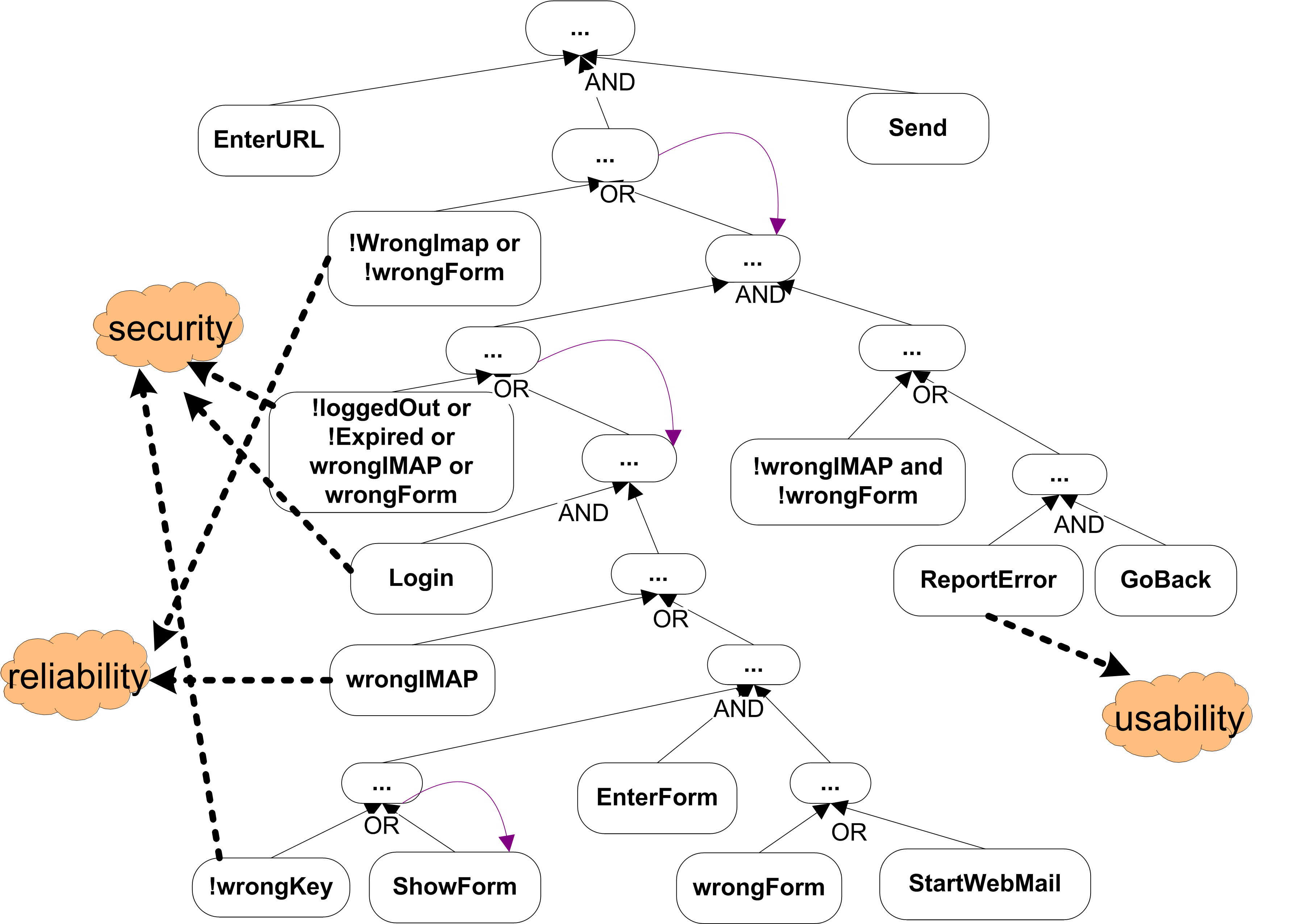
Here is the instructions on how to compile Columba inside Eclipse and as a result, here is the workspace of Columba under Eclipse development. The studied source code and reverse engineered goal models are show as follows:They were generated from the abstract syntax tree of the above Java code using a tool based on the JDT API.
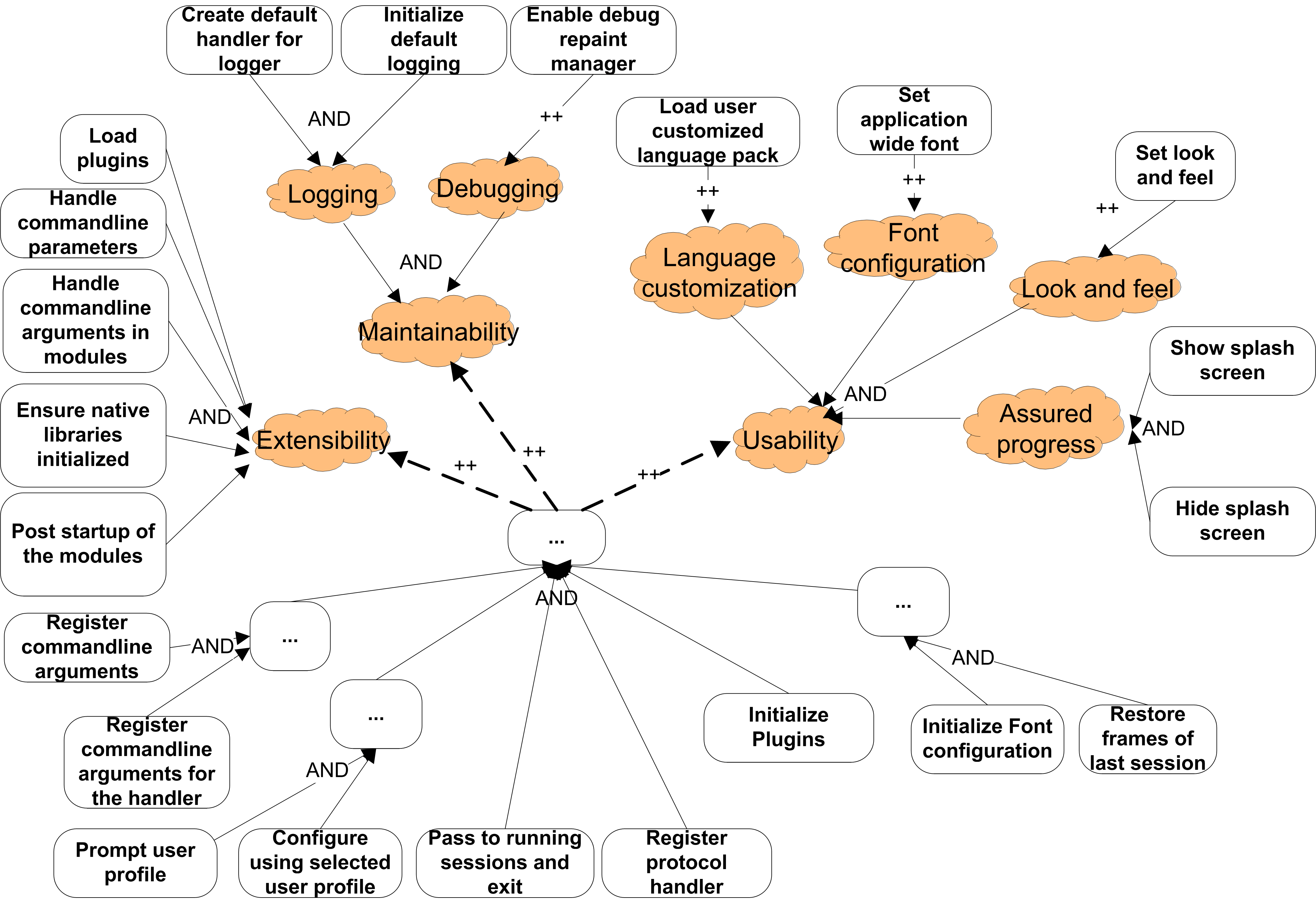
Squirrel Mail: from unstructured code to goal model
Squirrel mail is used in our department as a Web-based email client.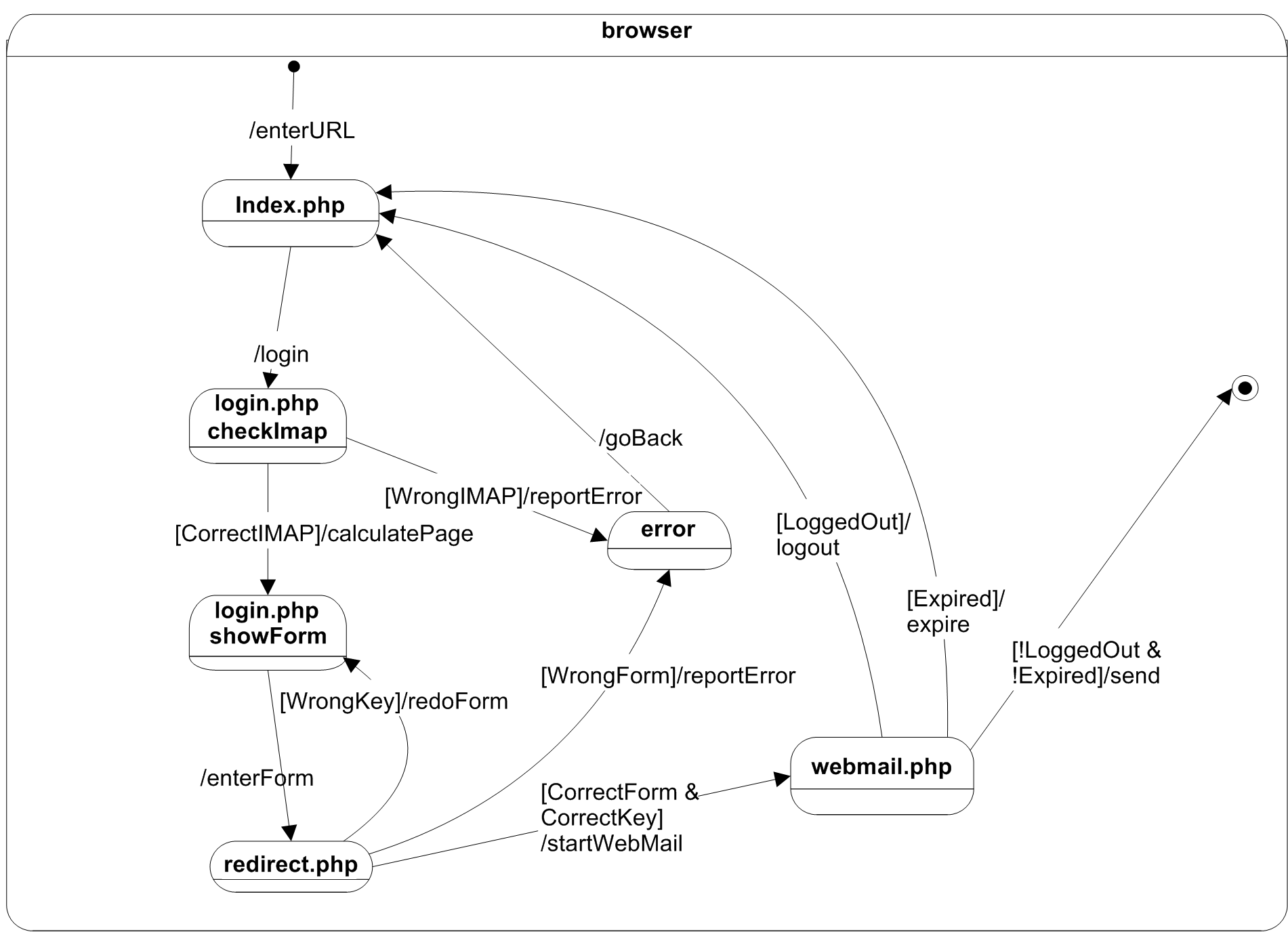
The refactored top-level statechart of Squirrel Mail, which models the behavior of the browser based on the refactoring of the PHP source code.
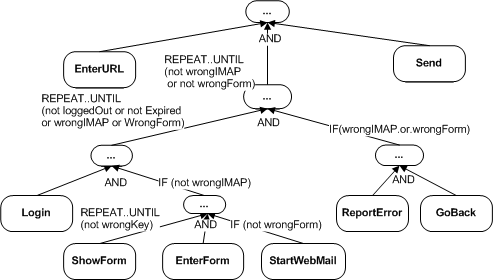
The annotated goal model converted from the structurized program.
Resources
Related topics
1. Based on AOPHP 1.0 -- Feb 17, 2005
The first implementation is adapted from aophp. AOPHP uses the RewriteEngine in Apache to redirect all the access to ".php" to a preprocessor "AOPHP" using the "php" file name as its argument. The output of the AOPHP, becomes the real script processed by the PHP. The AOPHP processor 1.0 uses a directive "//AOPHP" in the component language to indicate which aspect will be woven. We believe this gives away the advantage of aspect-orientation, that is, it should weave the advices without changing the original source code, not even adding a comment line. Thus the following code is a slight modification to their implementation. We assume all the aspects are already located in the same directory, as separate files "*.aspect". Then the weaver will load all such aspects in sequence, to weave them with the original code. AOPHP.javaIn the implemention above, we treat the weaving A1 as a transformation over the original code, A2 as a transformation over the woven code by A1, etc. An interesting problem is the order of the weaving. We copied the "phpport.aophp" into two aspects, and modified the output to show which one is getting woven earlier. Since we can deal with multiple aspects now, it is interesting to see this kind of interactions among aspects.
Before Talking AOPHP Says: PHP Cant Talk Right Now After Talking N1: 5 | N2: 10 Aspect2: Before Advice on Add Function Just Called Before Advice on Add Function Just Called Aspect2: After Advice on Add Function Just Called After Advice on Add Function Just Called TOTAL OF N1 & N2: 15Although both aspects have "around" advices, only the first one took effect, because the "say" method already disappeared. The second aspect weaves the "before" advices earlier, but "after" advices also earlier! The reason I guess is that the second aspect still weaves its advice with the original function, rather than on the woven function.
2. Based on the Zend compiler -- Feb 20, 2005
As the current implementation of AOPHP is through textual manipulations of the callee function in PHP, it is unlikely that the PHP call-site will be captured, especially when the functions are not inside a script file, but included from other program files. Thus an alternative (arguerably better) way is to modify the PHP compiler/interpretator itself so that all interceptions can be caught. Fortunately, PHP has an open-source Zend compiler, which can be modified to support aspects. Currently, I extend the PHP language with a rather simple aspect syntax, where an "aspect" is similar to a "class", an "advice" is similar to a "function" and a "joinpoint" is similar to an "expression". I haven't implemented "pointcut" (the placeholder for joinpoints) and more complex "joinpoint" yet, as for now, I think it is enough to try out the oscommerce case study. The aspectphp-zend-patch.tar.gz is done on PHP 4.3.10. Simply override the changed files, and recompile, the modified "php" will recognize and weave an aspect-oriented PHP program as simple as this component file and this aspect file. Any suggestions and contributions are welcome!!! Mar 3rd, 2005All aspects are using "*.aspect" naming convention. The original component PHP code does not need any change. The woven effect of the simple example is shown.
Resources
References
[1] Castro, J., Kolp, M., Mylopoulos, J., "Towards Requirements-Driven Software Development Methodology: The Tropos Project," Information Systems, June 2002. [2] Y. Yu, J.C.S.P. Leite, J. Mylopoulos. From goals to aspects: discovering aspects from requirements goal models". presented at the Requirements Engineering 2004 conference. [3] C. Zhang, H.-A. Jacobsen, Y. Yu. "Linking Goals to Aspects". In Early Aspects workshop at the AOSD conference. 2005. [4] AOSD.NETThe full paper in the SPE 35(1):1-14 presents an XSLT-based method that can completely localize the markup of XML documents into different natural languages. We also describe how the proposed technique can be applied to translation problems in programming (e.g. C and Java) or documentation (e.g. LaTeX or other formatting languages) so that a program or a document can be converted to and from an XML format.
A shorter paper "Localizing XML documents using XSLT(HTML)" has been previously presented in the Applied Informatics 2003 conference with the following demonstation kit.
Applications
The tool has been applied- To internationalize programs through the XSLT in Making XML documents International
- To convert knowledge representations in Telos (see OpenOME) or NFR into goal models or graphviz DOT graphs.
- To debug GCC for an efficient collection of the program unit dependence graph in the header restructuring project.
- To weave aspect-oriented PHP programs in the PHPAspect project by William Candillon. The project has been chosen by the Google Summer of Code in 2006.
Related work
- G. McArthur, J. Mylopoulos, S.K.K. Ng. An Extensible Tool for source Code Representation Using XML, Ninth Working Conference on Reverse Engineering (WCRE'02) October 29 - November 01, 2002 Richmond, Virginia.
- B. A. Malloy and J. F. Power. Program Annotation in XML: a Parser-Based Approach, Proceedings of WCRE 2002, Working Conference on Reverse Engineering, Richmond, Virginia, USA, pages 190--198, October 28 - November 1, 2002.
- JavaML: A Markup Language for Java Source Code
- Jezix
- Mamas' and Kontogiannis' JavaML
Resources
- Download a demo for the cache simulator + visualization implemented as a pure Java application
- Extract the files into a subdirectory, namely "foo/cacheviz"
- Change the path of the Java executable in the "test.bat" or "test.sh"
- The only parameter needed for test is "foo.is.bz2", which is the trace data generated from the corresponding "foo.f".
- Faster cache simulation has been re-implemented in C++ which links directly with the instrumentation tools in the FPT or the ORC compilers. The profiler has been successfully preparing data for the runtime loop dependence analyzer, the reuse distance simulator and also the cache simulator. (Kristof and Yijun)
- Thus the raw trace file is not necessary now. The trace is preprocessed by the C++ cache simulator to get the simulation result into a trace file into plain text, then processed through Perl script into XML. The Java application consumes the XML file to show the graphics. (Yijun)
- The Java application places focus on the graphic features for both Trace and Histogram views, such as Zooming, Filtering, Overlapping, and hyperlink back to the exact hotspots in an editor of the original source code. The GUI is implemented in JDK/Swing. (Bart and Yijun)
- A still faster presentation is made through Eclipse/SWT as a resource plugin, see the recent presentation for thesis defense of Joachim Vermeir (in Dutch) for a glimpse of the latest development. Charts has been integrated to visualize performance counters (Joachim, Kristof and Yijun)
Erik D'Hollander
Kristof Beyls
Bart Kerkhof
Joachim Vermeir
Yijun Yu
We present a framework of visualization for trace distributions to extract the useful cache behavior patterns. We focus on cache misses, reuse distances, temporal or spatial localities, etc. The histograms of these distribution patterns measure the behavior in quantity, revealing effective program optimizations. The performance bottlenecks are exposed as hot spots highlighted in the source code, showing the exact locations to apply suitable optimizations. The impact of the source-level program optimizations, again, can be verified by the visualization tool. The work has been presented in the Information Visualization (IV'01) 2001 conference. More details are published in the CCAI journal.
Update
We submitted a draft describing the approach to ASE'07. The project is now hosted at Google Code.- get junction.exe - create two buttons - junction.exe, parameters: %T%N %P%N - junction.exe, parameters: %P%N /d
September 13, 2006 Problem. In total commander, I often want to open a cygwin shell window to put the selected directory as the current one. However, when a cygwin window is opened, the current directory always stick to the HOME, which is for me, "d:\cygwin\home\Yijun Yu". Then to access a file in the visible directory of Total commander, I have to issue a "chdir" to something like "/cygdrive/c/path/to/commander/directory". How annoying! Then how to work around this problem? Solution. It is a combination of small tricks. 1. Create a shortcut button on the commander toolbar Right click at toolbar, choose "Change..." Append a command, fill in the following information:2. Edit the start script of cygwin, namely D:\cygwin\cygwin.bat: @echo off echo cd "%*" > "D:\cygwin\home\Yijun Yu\.cdpath" D: chdir D:\cygwin\bin bash --login -i 3. Create two scripts in your home directory (e.g. "D:\cygwin\home\Yijun Yu"): .profile: . .bashrc .bashrc: source .cdpath That's it. When you open any directory in total commander, just click the cygwin.ico button, you will launch a cygwin shell in the proper place. Enjoy!
1. Background
Eclipse is a family of software products, also known as a software product-line family. An Eclipse product is organized into features or plugins. For example, the standard Eclipse 3.0.1 installation contains 7 features, and 84 plugins. This is reflected by the following physical directory structures:
eclipse_product\
features\
plugins\
Not all features and plugins are necessary for every user tasks, for example,
a C/C++ development user may want the CDT product, whereas the Java
developer does not need it. Therefore, we consider to create a script
to automatically install/uninstall any Eclipse product.
When the Eclipse platform starts, it first looks at its configuration directory
to see which features should be enabled, then every plugin needed in the
execution will be *lazily* loaded by the platform. Therefore,
the installation of an Eclipse product requires to copy the product features
and plugins into the Eclipse installation directory. The uninstallation of an
Eclipse product requires to remove the product features and plugins from the
Eclipse installation directory.
2. Problem
The installation/uninstallation may be a lengthy process involving copying files.3. Solution
In Unix system, one can ease it by creating logical symbolic links of the product directories to the Eclipse platform directory to alleviate the physically moving problem. Symbolic links are not supported by Windows. Then how to immitate the symbolic link mechanism to achieve the fast installation/deinstallation on Windows? In Eclipse, one can create a directory in the workspace to mirror a directory in the file system. But the directories in the Eclipse installation directory can not be created this way. Our answer relies on the technique to use the *junction* utility for the NTFS file system.3.1 Junction point
In NTFS, a junction point is the information associated with a directory that can be parsed by a system call. *junction* is a system utility provided by the system internals web site, to use the junction point to record information of a remote *real* directory such that the NTFS is "cheated" to believe the directory is the remote directory. For example:c:\> junction foo d:\foowill create a mirror of the d:\foo as c:\foo. Here C: must be in a NTFS file system, whereas D: can be any file system format. Junction point is more powerful than the "subst" utility in the DOS file system which mirrors a disk letter to a remote directory (I have written a chapter on how to use *subst* utility to achieve symbolic link effect some years ago). Here the remote directory is *mounted* to any directory in the NTFS file system. An important difference between a junction point and a symbolic link in Unix, unfortunately, is that the junction point is treated as really the remote directory. In other words, if one deletes the junction point directory, all files under the remote directory will be removed. To remove a junction point directory safely without removing the remote files, the junction point is deleted by detaching it from the remote directory. This can be done by the *junction* command by the "/d" option:
c:\> junction /d foo
3.2 Scripting
The following is a Windows script to install the product to Eclipse platform.1 @echo off 2 set ECLIPSE=c:\eclipse 3 pushd %ECLIPSE%\features 4 for /D %%d in (%1\features\*) do @junction %%~nxd %%~dpnxd 5 cd ..\plugins 6 for /D %%d in (%1\plugins\*) do @junction %%~nxd %%~dpnxd 7 popdFirst, let's assume the script has one argument that can be addressed by %1 in the script. This argument is used as the directory of the Eclipse product to be installed and the product has prepared a *features* and a *plugins* subdirectory to hold the features and plugins respectively.
Line 1 turns off the echoing of each following command in the script.
Line 2 assumes that the Eclipse platform is installed under C:\eclipse directory.
Line 3 pushes the current directory in the directory stack, then change the current directory to the Eclipse features directory.
Line 4 loops for every subdirectory (/D) to call the *junction* command. The first argument given to the *junction* command is the filename and extension name of the directory, the second argument is the full name of the directory including its drive letter and full path.
Line 5 changes the current directory to the Eclipse plugins directory and Line 6 calls the *junction* command in a similar matter as Line 4.
Finally, Line 7 changes the currenct directory back to the one popped from the directory stack. The following similar script uninstall the Eclipse product:
1 @echo off 2 set ECLIPSE=c:\eclipse 3 pushd %ECLIPSE%\features 4 for /D %%d in (%1\features\*) do @junction /d %%~nxd 5 cd ..\plugins 6 for /D %%d in (%1\plugins\*) do @junction /d %%~nxd 7 popd
3.3 Single button solution
Windows total commander is a shareware inheriting most of the functionalities of a Norton commander. (It is one of my favorite tool to play on Windows, recommended by Prof. Erik H. D'Hollander.) The tool is very easy to be customized. Here is how you can create a single toolbar button to automate the above script.1. Install the total commander, of course. 2. Press 1, 2 or 3 to the shareware question of Total commander to be able to use all its functionality.5. Alternatively, if you know which products to be installed before hand, in the eclipse-install directory, prepare a script as follows:The file system is viewed by two parallel panes. The left-hand side shows the Eclipse platform directory. The right-hand side shows the Eclipse product directories, such as CDT (org.eclipse.cdt.sdk-3.0.0-M6-win32), ecletex for latex, ome4eclipse, Lavadora webservice for Eclipse, etc. and also our scripts under the *eclipse-install* directory. (I will write a separate tip on the usage of the latex plugins). 3. Now create a tool bar button by right click at the toolbar, apply *change...", fill in the following parameters:
Here %P%N indicate the Eclipse product directory that you just selected. 4. Place your mouse on one of the product directories, then press the toolbar button. When you open the Eclispe plugin directories, you can see the installed directories: the small shortcut decorator on the directory names are created as junction point directories.

call eclipse-install d:\ome4eclipse call eclipse-install d:\org.eclipse.cdt.sdk-3.0.0-M6-win32 call eclipse-install d:\latex call eclipse-install d:\webserviceThen doubleclick this script will install all products at once.
Resources
The scripts can be downloaded here.Updates
December 7, 2005
The tutorial still works, but I found two simpler workarounds:
1) create a "links" subdirectory under the %ECLIPSE_HOME% directory.
For each product, create a file links/%product%.link which contains
a single line:
path=%path_to_product%
2) create an empty .eclipseextension file under the %product%/eclipse
directory, then use "Help/Manage configuration" dialog to add
an extension to the %product% directory
To me, the first alternative is better, since you may fully automate
the reconfiguration of Eclipse without using its dialog.
Note that the following technique may still be used to create a symbolic
link to the links directory because it is still under the Eclipse
SDK installation directory and could be removed along with the
Eclipse SDK.
Feb 28, 2005
The OpenOME project uses
this script to select the Eclipse products without physically copying them, on
the basis of the above finding.
August 1, 2006
Eclipse products can now be customized by a
downloading service that bundles them on the demand of a client.
September 15, 2006
One can perform automated update of Eclipse products at command line.
This is slower than the previous solution, but platform independent...
See how we update the OpenOME product and its dependent products
automatically for its users/developers.
Resources
Goal.java
package edu.toronto.cs.goalmodel;
import java.util.List;
/** @model */
public interface Goal {
/** @model */
String getName();
/** @model default=0 */
LabelType getLabel();
/** @model */
DecompositionType getType();
/** @model */
Goal getParent();
/** @model type="Goal" containment="true" opposite="parent" */
List getGoal();
/** @model type="Topic" containment="true" */
List getTopics();
/** @model type="Contribution" containment="true" */
List getRule();
/** @model type="Property" containment="true" */
List getProperty();
}
Contribution.java
package edu.toronto.cs.goalmodel;
/** @model */
public interface Contribution {
/** @model type="ContributionType" */
int getType();
/** @model */
Goal getTarget();
}
DecompositionType.java
package edu.toronto.cs.goalmodel;
/** @model */
public final class DecompositionType {
/** @model name="OR" */
public static final int OR = 0;
/** @model name="AND" */
public static final int AND = 1;
/** @model name="LEAF" */
public static final int LEAF = 2;
}
ContributionType.java
package edu.toronto.cs.goalmodel;
/** @model */
public final class ContributionType {
/** @model name="HELP" */
public static final int HELP = 1;
/** @model name="HURT" */
public static final int HURT = -1;
/** @model name="MAKE" */
public static final int MAKE = 2;
/** @model name="BREAK" */
public static final int BREAK = -2;
}
LabelType.java
package edu.toronto.cs.goalmodel;
/** @model */
public final class LabelType {
/** @model name="Satisfied" */
public static final int SATISFIED = 2;
/** @model name="Denied" */
public static final int DENIED = -2;
/** @model name="PartiallySatisfied" */
public static final int PARTIALLY_SATISFIED = 1;
/** @model name="PartiallyDenied" */
public static final int PARTIALLY_DENIED = -1;
/** @model name="Unknown" */
public static final int UNKNOWN = 0;
/** @model name="Conflict" */
public static final int CONFLICT = 4;
}
Topic.java
package edu.toronto.cs.goalmodel;
/** @model */
public interface Topic {
/** @model */
String getTopic();
}
Property.java
package edu.toronto.cs.goalmodel;
/** @model */
public interface Property {
/** @model */
String getName();
/** @model */
String getValue();
}
Resources
Faculty of Maths & Computing
The Open University
Walton Hall, Milton Keynes, MK7 6AA
United Kingdom (U.K.)
Office: Room 310
Tel: +44(0) 1908-655562
Email: Y.Yu AT open.ac.uk

|
Senior Lecturer
Computing Department Faculty of Maths & Computing The Open University Walton Hall, Milton Keynes, MK7 6AA United Kingdom (U.K.) Office: Room 310 Tel: +44(0) 1908-655562 Email: Y.Yu AT open.ac.uk |
Bio. Yijun Yu graduated from the C.S. Department of Fudan University (B.S. 1992, M.S. 1995, Ph.D. 1998). He was a postdoc at the ELIS Department in Ghent University (1999--2002), then he works as a research associate for the Knowledge Management lab in the Department of Computer Science, University of Toronto (2003-2006). In October 2006, he became a Senior Lecturer in the Department of Computing, Open University. He is a member of the IEEE Computer Society. His research interests are in Automated Software Engineering and Requirements Engineering. |