University of Toronto & UC Berkeley & Vector Institute
[Arxiv Page][PDF] Model-based reinforcement learning (MBRL) is widely seen as having the potential to be significantly more sample efficient than model-free RL.
However, research in model-based RL has not been very standardized.
It is fairly common for authors to experiment with self-designed environments, and there are several separate lines of research,
which are sometimes closed-sourced or not reproducible.
Accordingly, it is an open question how these various existing MBRL algorithms perform relative to each other.
To facilitate research in MBRL,
in this paper we gather a wide collection of MBRL algorithms and propose over 18 benchmarking environments specially designed for MBRL.
We benchmark these MBRL algorithms with unified problem settings, including noisy environments.
Beyond cataloguing performance, we explore and unify the underlying algorithmic differences across MBRL algorithms.
We characterize three key research challenges for future MBRL research:
the dynamics coupling effect,
the planning horizon dilemma, and the early-termination dilemma.
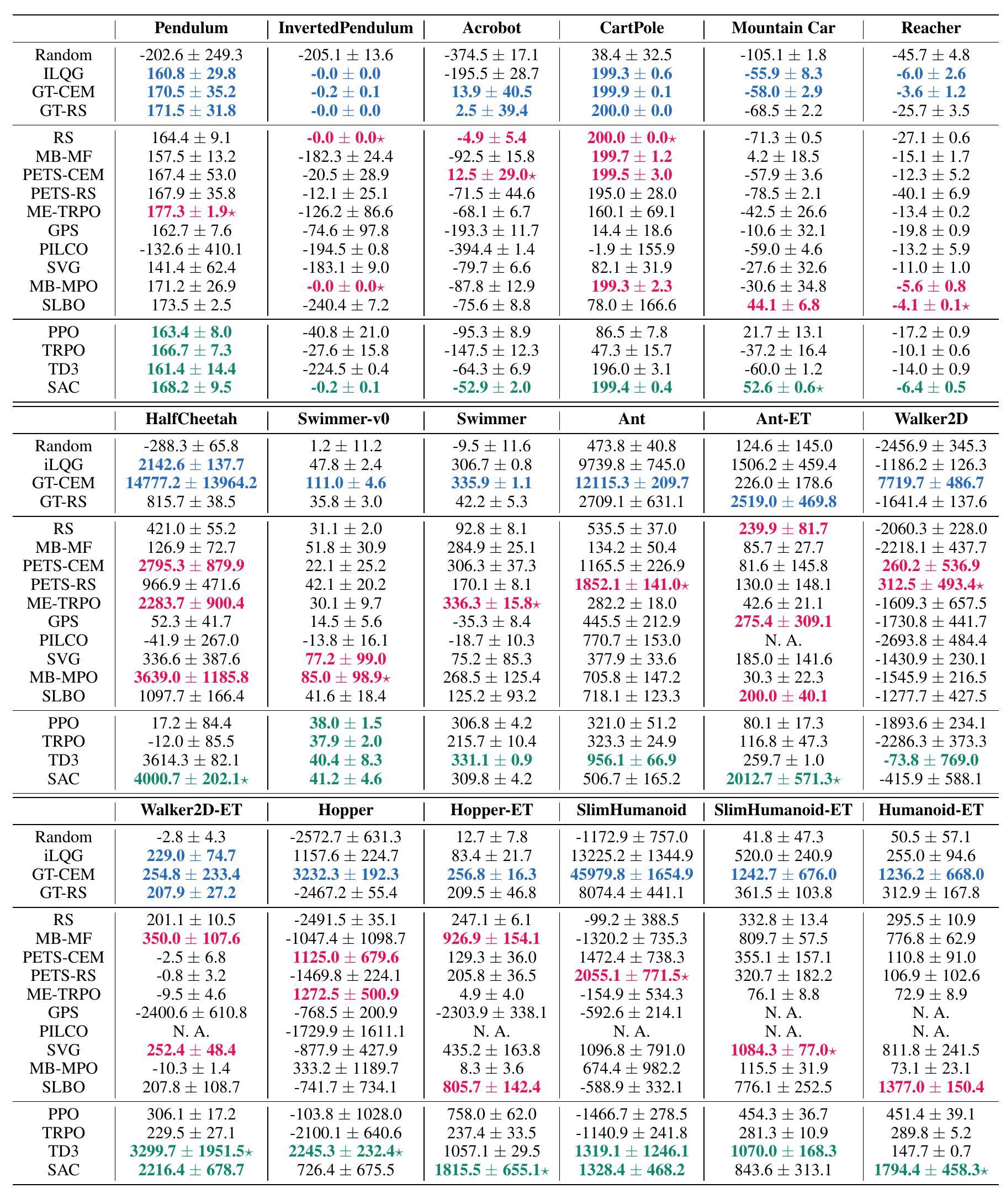
Our benchmark consists of 18 environments with continuous state and action space based on OpenAI
Gym. We include a full spectrum of environments with different difficulty and episode length,
from CartPole to Humanoid.
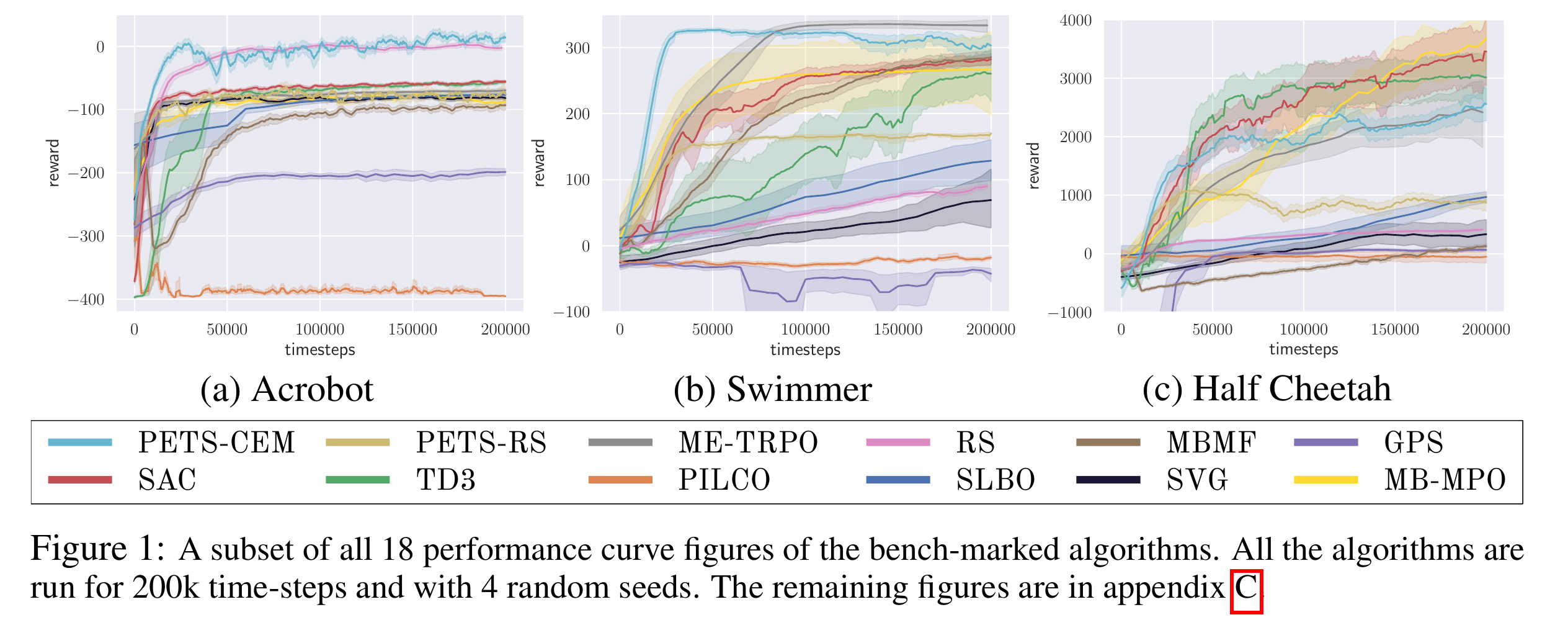
Each algorithm is run with 4 random seeds for 200k time-steps.
We refer readers for the paper for detailed performance curves.
Engineering Statistics
The engineering statistics shown in Table 2 include the computational resources,
the estimated wall-clock time, and whether the algorithm is fast enough
to run at real-time at test time, namely, if the action selection can be done faster than the default
time-step of the environment.
Dynamics Bottleneck
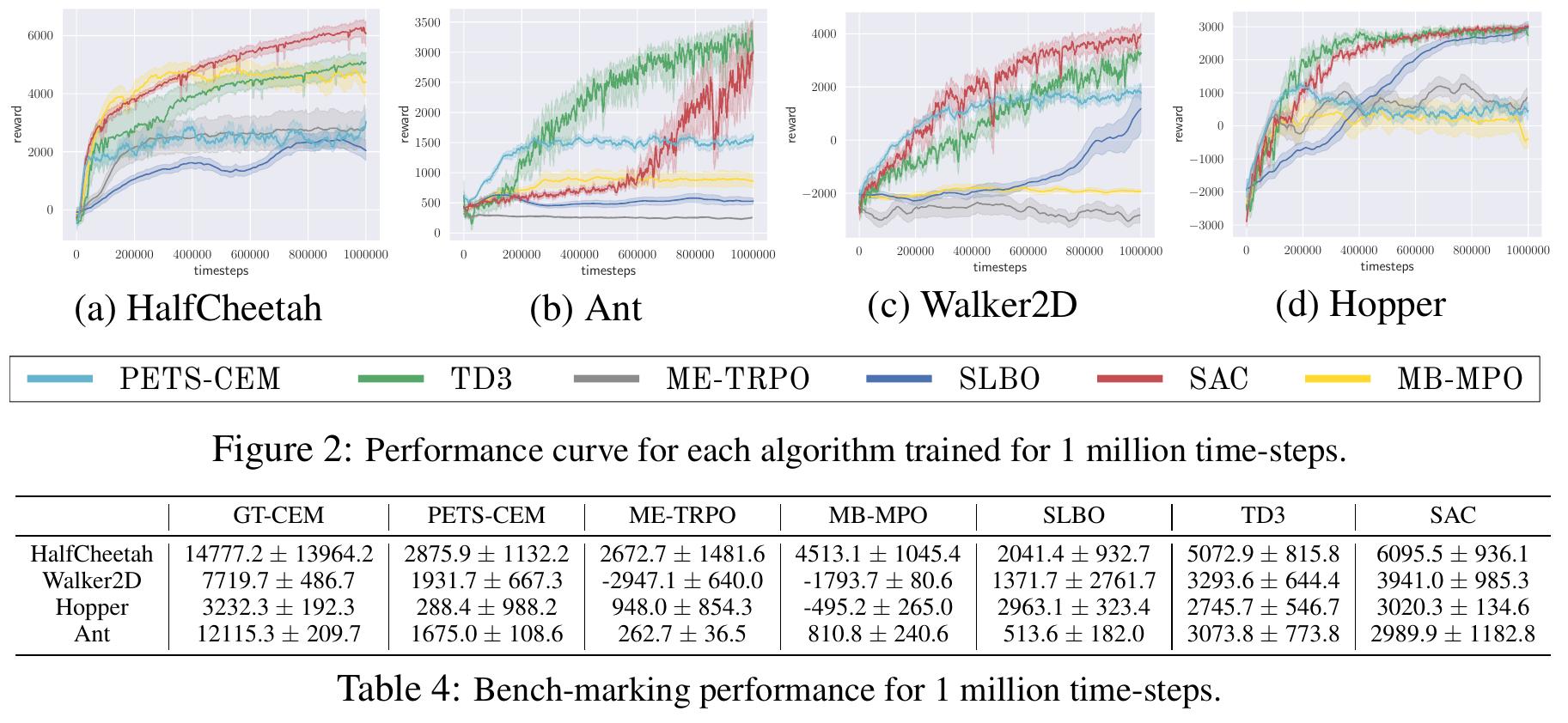
The results show that MBRL algorithms plateau at a performance level well below their model-free
counterparts and themselves with ground-truth dynamics. This points out that when learning models,
more data does not result in better performance. For instance, PETS's performance plateaus after
400k time-steps at a value much lower than the performance when using the ground-truth dynamics.
Planning Horizon Dilemma
One of the critical choices in shooting methods is the
planning horizon. In Figure 3, we show the performance
of iLQG, CEM and RS, using the same number of candidate planning sequences, but with different planning
horizon. We notice that increasing the planning horizon
does not necessarily increase the performance, and more often instead decreases the performance.
We argue that this is result of insufficient planning in a search space which increases exponentially with
planning depth, i. e., the curse of dimensionality.
On the right, we further experiment with the imaginary environment length in SLBO (Dyna) algorithms.
We have similar results that increasing horizon does not necessarily help the performance and sometimes hurt the performance.
Early Termination Dilemma
Early termination, when the episode is finalized before the horizon has been reached, is a standard
technique used in MFRL algorithms to prevent the agent from visiting unpromising states or damaging
states for real robots. When early termination is applied to the real environments, MBRL can
correspondingly also apply early termination in the planned trajectories, or generate early terminated
imaginary data. However, we find this technique hard to integrate into the existing MB algorithms.
Conclusion
In this paper, we benchmark the performance of a wide collection of existing MBRL algorithms, evaluating their sample efficiency,
asymptotic performance and robustness. Through systematic evaluation
and comparison, we characterize three key research challenges for future MBRL research. Across
this very substantial benchmarking, there is no clear consistent best MBRL algorithm, suggesting lots
of opportunities for future work bringing together the strengths of different approaches.
Reproducibility and MBRL Package
The benchmarking environments and the code to reproduce the results can be found Github Code.
The installation guide and detailed readme to run the code can be found in the Github.
We are currently working towards a unified package for all the MBRL algorithms.