

New approach: compute and execute incrementally
optimal policies on-line using the
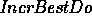 interpreter.
interpreter.
-
- Take a program p and a current situation s,
compute off-line an optimal policy
 and the residual program p'
and the residual program p'
-
- Determine the first action a of
-
- Execute the action a in the real world
-
- If a is stochastic, get sensory information necessary
to identify
which outcome of a has actually occurred.
If a is a sense action, then connect to sensors and get data.
-
- Repeat.
The cycle of computing
an optimal policy and remaining program, executing the
first action and getting sensory information (if necessary)
repeats until the program completes or execution fails.