
About
BABEL is research project focusing on query optimization of big data workloads. It is being developed as part of a research project at the Department of Computer Science, University of Toronto.
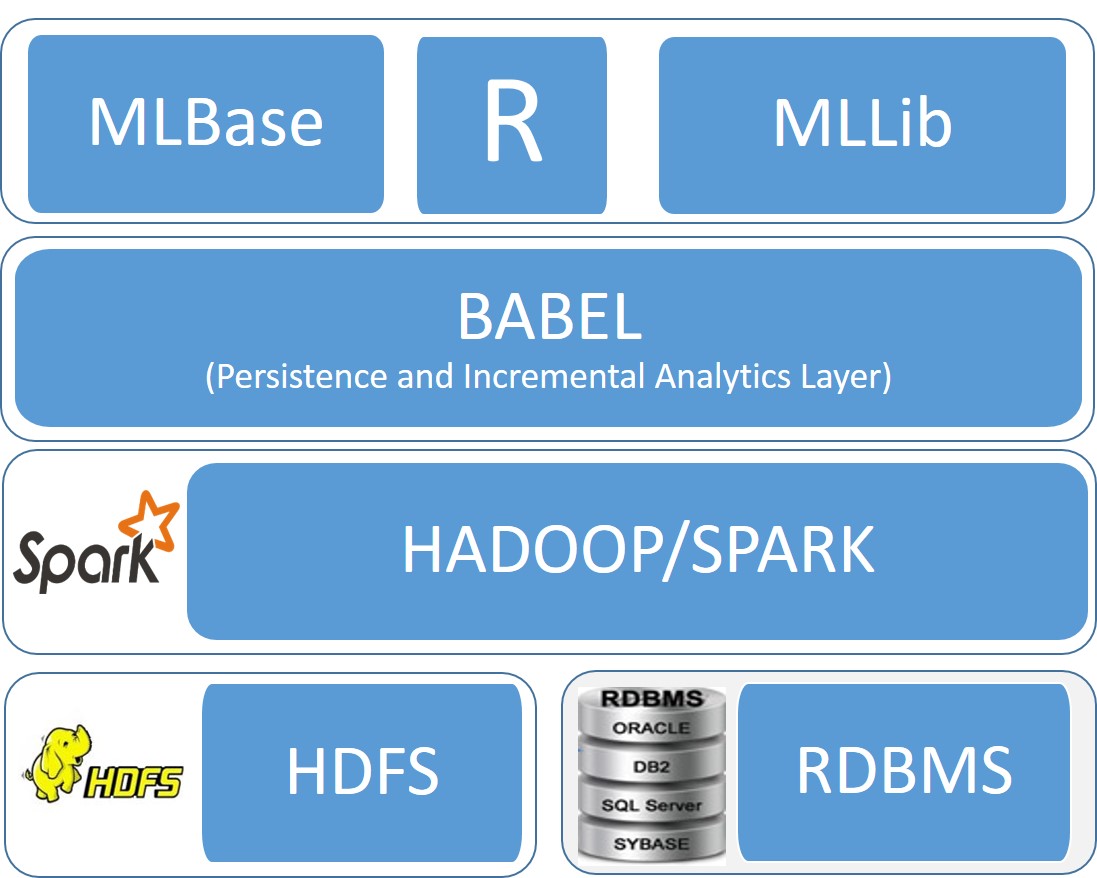
Motivation: Analysis of large data collections using popular machine learning and statistical algorithms has been a topic central to big data management. Such analysis involves a) iterative query processing (building models on data and refining them based on results), b) manipulating relational data (via sophisticated SQL queries) to product data for subsequent analysis, with architectures such as SPARK and c) utilizing modern computer architectures to run the analytical layer (e.g., SPARK, R etc). BABEL focuses on each of these distinct aspects of big data query processing.
Incremental Query Processing A typical analysis workload consists of applying an algorithm to build a model on a data collection and subsequently refining it based on the results. Exploratory analytical tasks are a part of a workload and rarely run in isolation. Moreover, exploratory tasks, may involve extending or refining previously completed tasks. As a result, this behavior reveals certain dependencies among the steps of an analysis workload. Such dependencies expose opportunities for work sharing across tasks. BABEL explores such opportunities automatically thus saving computation and I/O cost.
Query Optimization by Model Decomposition In traditional relational query optimization, simple query re-write (e.g., predicate pushdown) is higly sucessful in reducing query processing time. We are exploring analogs of such "push down" when executing big data workloads. Typically an SQL query is issued (possibly involving joins) to prepare a data set for further analytsis. Since the analysis goal is typically known at query generation time we are exploring such knowledge to optimize the resulting query and produce the results much faster.
Big Data Workloads in Modern DBMS architectures We are exploring bottlenects and architectural optimizations when executing big data workloads (e.g., MLlIB, GraphX) in data processing layers such as Spark and R. We aim to uncover deficiences and bottlenecks and understand how performance can be improved.
Publications