Introduction to git and its work flow (for researchers)
Ken Pu
This is given as a group meeting discussion on collaborative research at University of Toronto.
1. Problem definition: working by one's self
Your work a directory of files.
Protect your work.
How do you protect your work from yourself?
Imagine if you did something like:
$ ls
important_algorithm.cc important_decl.h outputs final_results
$ cd output
'directory does not exist.'
$ rm -rf *
$ cd ..
$ ls
Forest Gump:
Stupid is as stupid does.
SIGMOD time:
Arh... you typed a wrong directory. But it's 2:30am EST, and the deadline for submission is 12:00AM PST.
How do you explore different possibilities?
Imagine that your algorithm has 100+ different runtime parameters to tune, and you are trying to understand how the performance is being affected by different values.
We need proper software engineering to stay out of our way.
Plot engineering
It's 12:30pm, and your meeting with your PhD supervisor is at 3:00pm. But you don't have a decent plot to show...
You might be tempted to do:
$ cp -R ./workspace ./workspace_meeting_with_miller $ cd ./workspace_meeting_with_miller # hack the heck out of parameter space, and find a pretty # plot to show...
The good:
- You feel safe because your original honest work is kept safe in
./workspace - Therefore, you feel daring to try something outside the box (e.g. set the number of threads to 1000).
The bad:
- Very quickly (I mean very), you forget all the changes you have made
to
./workspace_meeting_with_miller. You might even went and changed the work queue implementation of your algorithm. - It's not clear what to do with
./workspace_meeting_with_millerafter the meeting with your supervisor.
Git is your friend here.
- It stays out of your way.
- It helps you out.
2. Problem definition: working with your team
-
Shared folder in Dropbox: Don't share anything mutable over dropbox. I.e., if something will be edited by someone, don't share it over Dropbox. ban
-
SVN repository hosted in a remote server or in the cloud (google code):
- This is generally considered good enough.
- The overhead of setting one up and actually pretty significant.
- You don't have the ability to have private repository to play with. (See problems of working by yourself).
How many of us branch and review historic changes in the SVN repo?
3. Git basics
Like svn, git has one command git. It does everything.
The data model of git:
- A directory of files.
- The whole directory is versioned. So, you should be able to refer to
(path, ver)wherepathis a file path in the directory, andveris the version of the directory. - A repository is the collection containing all the versions of the directory since the beginning of time.
- Everyone has their own local repository.
- Remote repositories can synchronize in a controlled way.
- All the versions form a directed acylic graph.
- Each version can be tagged with an alias.
- The root is the initial verson of the graph.
- Each time a commit is made, a new version is created, and is connected to its parent version.
- One can start branching at any version.
- One can merge branches together to a common version.
- tagging is very cheap.
- branching is very cheap.
- branches are not shared among remote repos by default.
4. Git by example
Workflow: version control
 |
## # create an empty repo ## git init # a local repo to work with git init --bare # a _bare_ repo that can be shared |
 |
## # assign a tag to a special commit ## # tag the current version git tag meeting_with_miller # tag a particular version git tag meeting with miller fc4d |
 |
## # moves the HEAD pointer ## git reset fc4d Based on my personal experience, we usually don't need to reset the HEAD. |
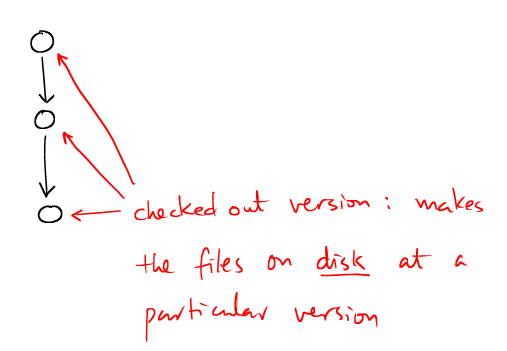 |
## # Showing off well tuned parameters ## git checkout meeting_with_miller ## # Undo mistakes ## rm important_algorithm.cc # checkout just one file from the HEAD git checkout HEAD important_algorithm.cc # checkout file from a while ago git checkkout HEAD~5 important_algorithm.cc |
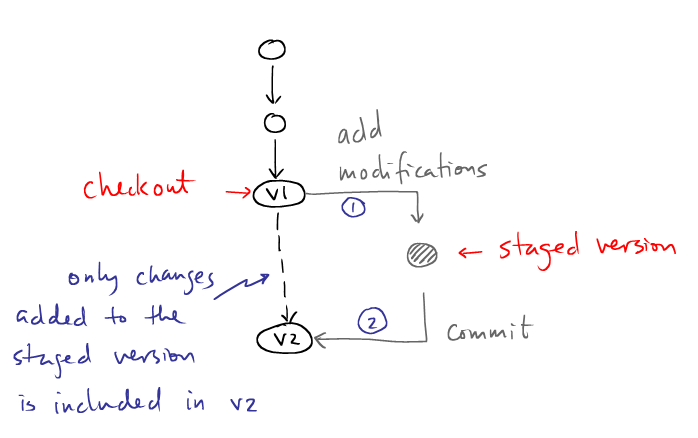 |
Git ignores all changes to files on disk unless you explicitly tell git to include some change into the repository. vi important_algorithm.cc ## # Add imporant_algorithm.cc to the staging version ## git add important_algorithm.cc ## # Commit the staged files to create a new version. ## git commit -m 'important changes to important_algorithm.cc' |
Workflow: trying things out -- branching
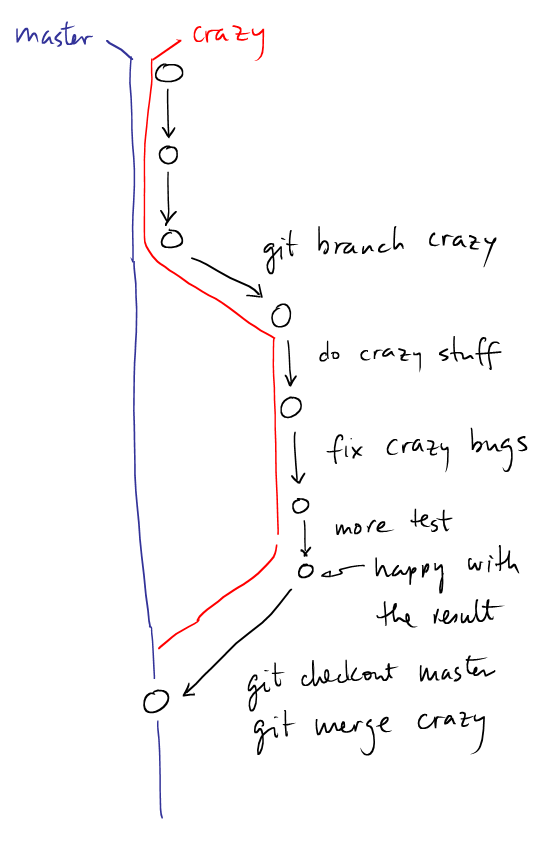 |
$ git branch master $ git branch crazy You are on crazy branch ## # We are on the crazy branch ## $ git branch master * crazy $ vi important_algorithm.cc $ git commit -m 'made some crazy changes, not sure' $ ... $ git commit -m 'yes, we are really happy with the changes' ## # Switch back to the master # (all changes disappears from working directory ## git checkout master # catch up to crazy branch git merge crazy |
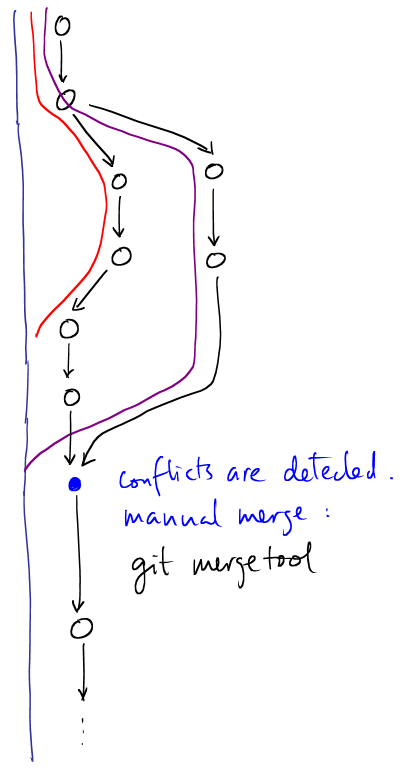 |
If multiple people are working on the same lines of text, conflicts will
occurr, and the merge tool probably cannot safely resolve them during
Git offers a lot of nice tools to help out:
|
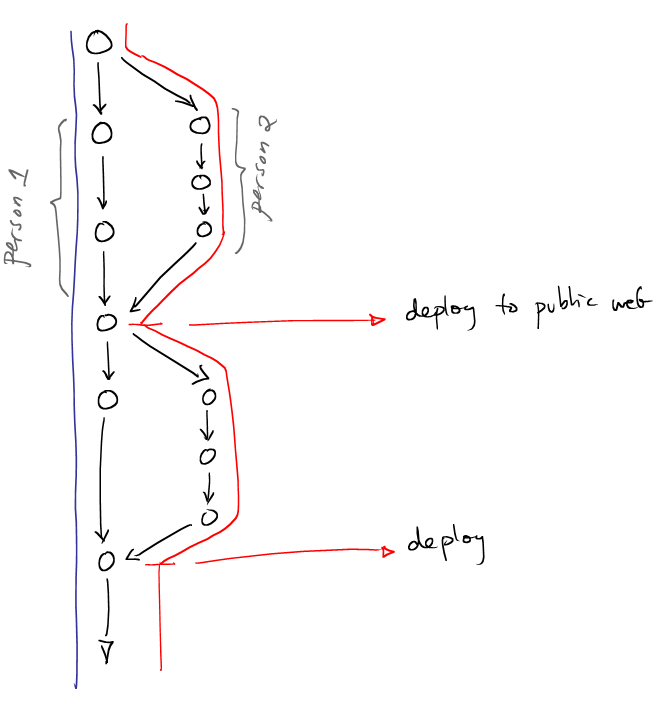 |
Case studyTwo persons working on a Web site together. NOTE: something is untold. How are we exchanging distributed versions of the same repository? A: there are two distributed but synchronized repos. |
Workflow: distribution & synchronization
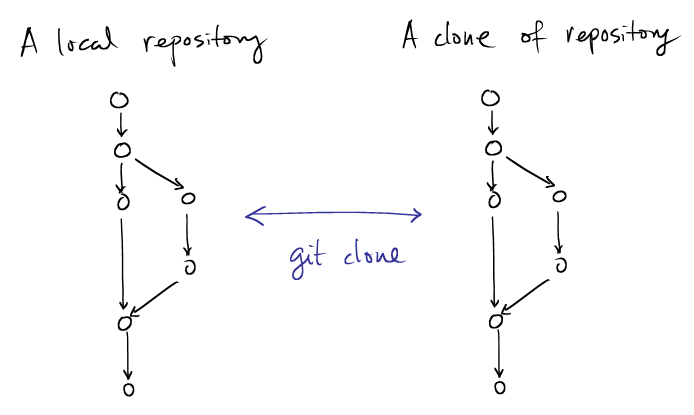 |
## # clone a remote repo into workspace ## $ git clone kenpu@vldb.isl:repos/project1 ./workspace $ git remote origin |
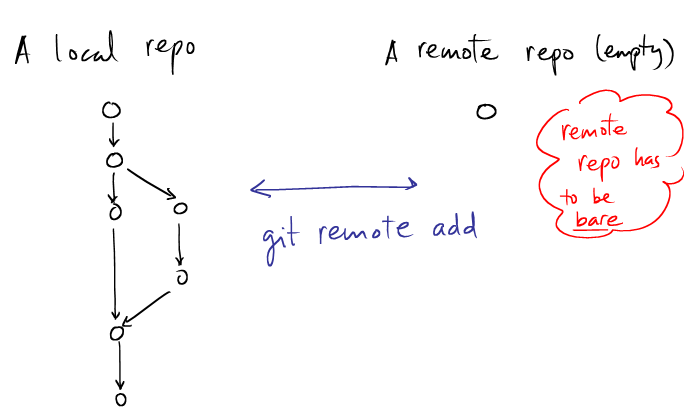 |
## # link another remote repository to the current repo ## $ git remote add origin kenpu@vldb.isl:repos/project1 |
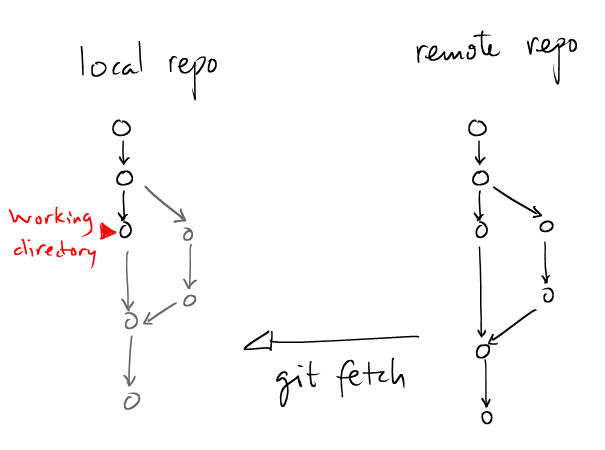 |
## # Fetch all the versions, but do not disturb the # current working directory. ## $ git fetch # more explicit $ git fetch origin |
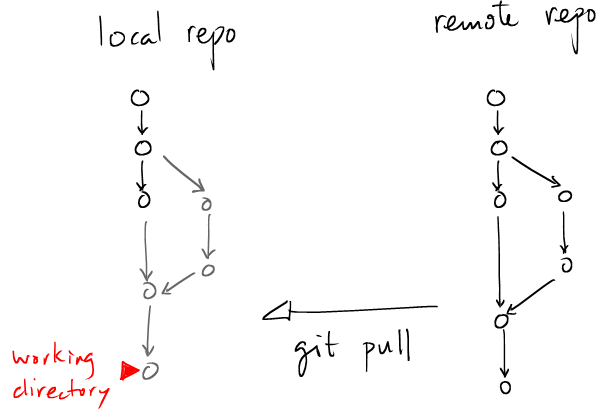 |
## # Fetches the version from a remote, # *and* catch-up all the head of all the branches ## git pull # Only catch-up on crazy branch git pull origin crazy |
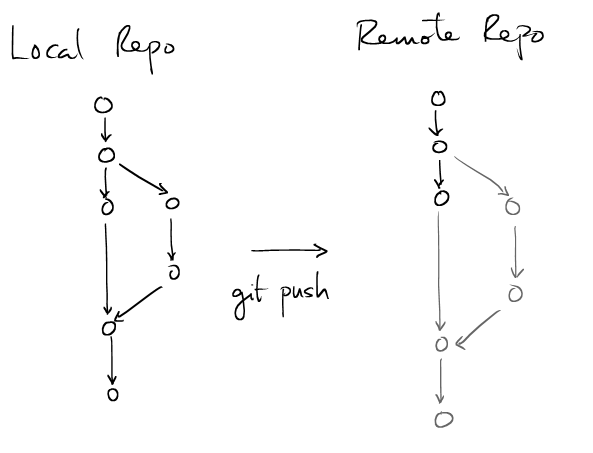 |
## # push all changes to a remote repo ## $ git push ## # push only crazy branch to remote origin. # if crazy does not exist on origin, then create # a branch in the remote repo. ## $ git push origin crazy # Even more explicit # pushes to `origin` local repo called crazy, and call it `crazier` # in the remote repo $ git push origin crazy:crazier |
5. Online resources
This article is based on several high quality online resources on git.
- git help command
- Pro Git is available online. It's very concise and thorough on best practices of using git.
- Stack overflow has some of the best answers to common git related questions.