|
BTSVQ Overview
|
|
With the increasing number of gene expression databases, the need for more powerful analysis and visualization tools is growing. Many techniques have successfully been applied to unravel latent similarities among genes and/or experiments. Most of the current systems for microarray data analysis use statistical methods, hierarchical clustering, self-organizing maps, support vector machines, or k-means clustering to organize genes or experiments into "meaningful" groups. Without prior explicit bias almost all of these clustering methods applied to gene expression data not only produce different results, but may also produce clusters with little or no biological relevance. Of these methods, agglomerative hierarchical clustering has been the most widely applied, although many limitations have been identified.
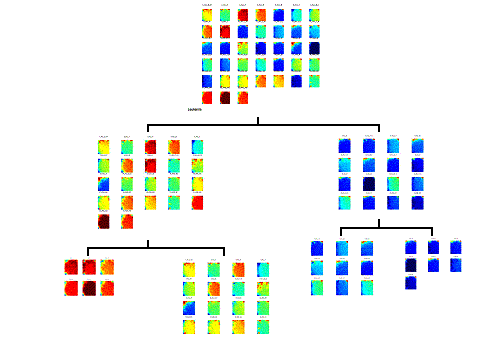
Starting with a systematic comparison of the underlying theories behind clustering approaches, we have devised a technique that combines tree-structured vector quantization and partitive k-means clustering (BTSVQ). This hybrid technique has revealed clinically relevant clusters in three large publicly available data sets. In contrast to existing systems, our approach is less sensitive to data preprocessing and data normalization. In addition, the clustering results produced by the technique have strong similarities to those of self-organizing maps (SOMs). We discuss the advantages and the mathematical reasoning behind our approach.
Copyright © 2002-2008 Ontario
Cancer Institute, Division of Signaling Biology |