Lecture Summary:
p(lk == s) = C(n, s) p^s (1-p)^(n-s) where n = total number of items in the hash table, p = 1/cap, C(n,s) = n! /(s! (n-s)!) = "n choose s".The mean of this distribution is np = n/cap = loadFactor. For typical load factors (eg. 1 or smaller), this formula predicts that the probability that a sublist has length 10 or bigger is rather small (i.e., a probability of 1/10,000,000).
Note that java.util.HashSet is unsuitable for our current application, since we cannot get access to individual objects within the set (other than by iterating over the set, or using toArray()).
We therefore implement the ReachableSet interface using the java.util.HashMap class.
We will use the parameterized type HashMap<Board, MultiNode>. That is, we will index into the hash map using a Board as the key. The data associated with the Board will be the MultiNode with that Board as data.
Note a Board currently requires a two dimensional array to encode the state of the maze, and thus each Board requires a significant amount of memory on its own. At first glance, the idea of using a HashMap seems wasteful in terms of memory, since we have to store all the Boards used as search keys and all the Boards within the MultiNodes themselves. Therefore it seems this approach might take up roughly twice as much memory as a simple ArrayList of MultiNodes.
However this is not the case. The Board being used as a key is stored exactly once, with both the key and the associated MultiNode referring to it. The memory overhead in using a HashMap is therefore not so prohibitive.
We need to write:
The following is a simple hash function for the Board class in the maze example. (Include this in Board.java.) Due to integer overflow, the value returned by hashCode() can be negative.
public int hashCode() {
int code = 0;
for (int r = 0; r < matrix.length; r++)
{
for (int c = 0; c < matrix[0].length; c++)
{
code = code*127 + matrix[r][c];
}
}
return code;
}
Note the hash function contract is satisfied for the above function hashCode(). (Why?)
To restrict the range of the hash function, we could define (inside the implementation of HashMap, say):
private static int hash(Object o, int cap) {
return Math.abs(o.hashCode()) % cap;
}
The combined result of these two mappings can be thought of in terms of the Baker's transformation or the Horeshoe map.
The intuition is that we stretch the values of various board configurations along the real axis by repeatedly multiplying by a large prime number (127 in this case), and allowing these values to fold back on themselves via integer overflow in hashCode() and via the remainder operation in the method hash(Object, int).
This is a little like kneading bread, repeatedly flattening the dough out then folding it back on itself. Kneading is useful for getting a roughly uniform distribution of ingredients throughout the dough. We're doing a similar thing here to approximate the uniform hashing assumption.
The previous hash function may not be desirable if the capacity is a multiple of the factor 127. More complex hash functions can avoid this (see choosing a good hash function). But this is beyond the scope of our discussion.
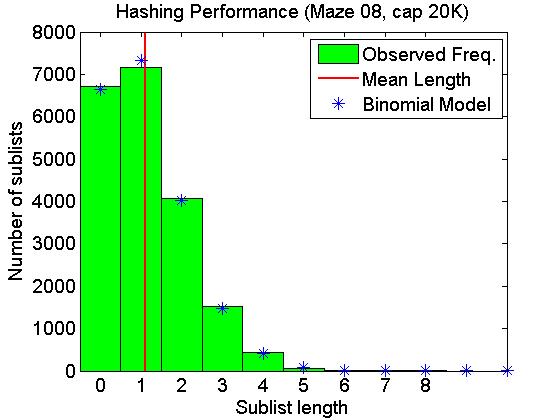
We ran the above hash function on the reachable set for the Maze for level 08. (This maze produced a reachable set of size 22,042.) The capacity was chosen to be 20,000. As a result, the load factor was 1.10, somewhat higher than the default of 0.75.
The resulting sublists in the hash table have lengths ranging from 0 to 8. The observed frequencies of each length are shown below:
Our second job is to write the class definition for ReachableHash, which must implement the interface ReachableSet.
See ReachableHash.java.
Note:
| Maze | ArrayListReachableSet | ReachableTable | ReachableAVLTree | ReachableHash |
|---|---|---|---|---|
| level08.maz | 7565 (= 2.1 hrs) | 94.5 | 3.1 | 2.4 |
| level09.maz (*) | -- | 855 | 4.8 | 4.6 |
| level10.maz (*) | -- | 336 | 4.2 | 3.9 |
To do this you first need to ensure that your breadthFirstSearch() method in graph/Reachable.java does not return directly from the loop over elements in the toDo queue, but rather breaks out of that loop once the goal state is found and then executes the busy finder code below. Also, note this code will not be executed if the search runs out of memory (since in that case an OutOfMemoryError is thrown and the breadthFirstSearch() method is abnormally terminated).
Insert the following at the end of your breadthFirstSearch() method in Reachable.java:
private void breadthFirstSearch() {
....
} // Over toDo queue
if (true) {
System.out.println("Busy finder");
ElapsedTime et = new ElapsedTime();
et.start();
for(int k = 0; k < 100; k++) {
Iterator<MultiNode> rIt = reachableSet.iterator();
while(rIt.hasNext()) {
reachableSet.get(rIt.next());
}
}
System.out.format("Busy finder time: %5.1f\n", et.time()/1000.0);
}
} // end of breadthFirstSearch
You need to import adt.ElapsedTime within Reachable.java.
Which approach is faster, ReachableAVLTree or ReachableHash? What is the ratio of runtimes reported by this busy finder code when ReachableAVLTree is used to implement reachableSet, versus ReachableHash?
If you already have done question 2 above, your code should report the runtime of the busy finder loops, now using red-black trees. How does this compare to your previous results using HashMap? If you set the condition in the if statement wrapping the busy finder code to false, how does the overall runtime of the breadthFirstSearch() solver (i.e., the time reported by MazeGui) compare to the other methods?