These movies illustrate the neural network described in the paper:
Hinton, G. E., Osindero, S. and Teh, Y. (2006)
A fast learning algorithm for deep belief nets.
Neural Computation 18, pp 1527-1554.
[ps.gz]
[pdf]
To generate from this model we first use alternating Gibbs sampling to get a sample from the top-level associative memory that consists of 2000 top-level units symmetrically connected to the 500 high-level units + 10 label units. Then we use the directed connections to stochastically generate pixel probabilities from the sampled binary states of the 500 high-level units. Notice how the random initial configuration of the high-level associative memory gradually settles into a free energy ravine that is preferred by the clamped label.
To recognize an image, we use bottom-up "recognition" connections to produce binary activities in the two lower hidden layers and then perform alternating Gibbs sampling in the top two layers.
Movies of the network generating and recognizing digits
Click on a class label then click play to generate an image from that class.
Click on an image then click play to provide the input for recognition.
Additional digit movies
These movies show 10 different runs in
parallel, with a different class label clamped on in each run. Each
movie starts with random binary states for the 2000 top-level neurons
and then performs 300 iterations of alternating Gibbs sampling between
the top two layers. Every 3 iterations, the directed connections down
to the pixels are used to compute the probabilities of each pixel
turning on and these probabilities are displayed. 300 iterations is
not quite long enough for the model to always find the right free
energy ravine.
movie1
movie2
movie3
The three movies are just three different runs form random initial states.
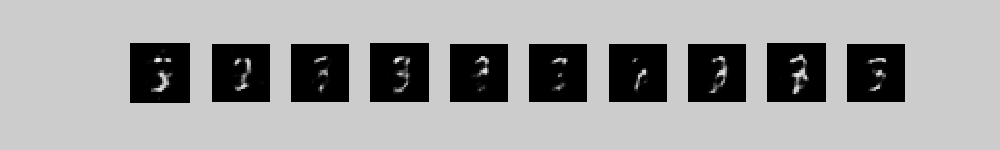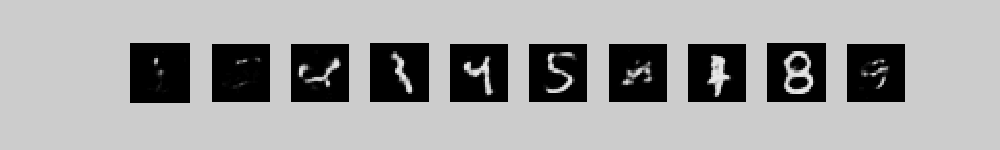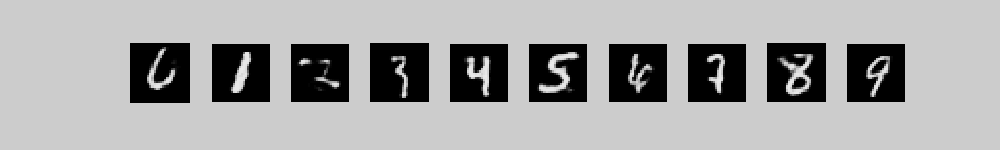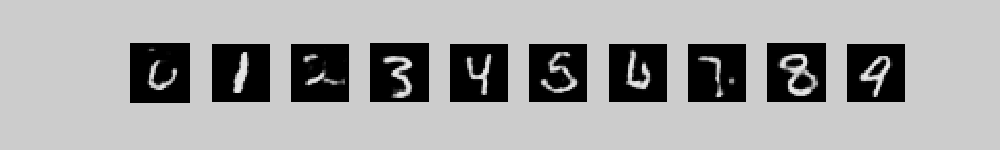{kind=link}
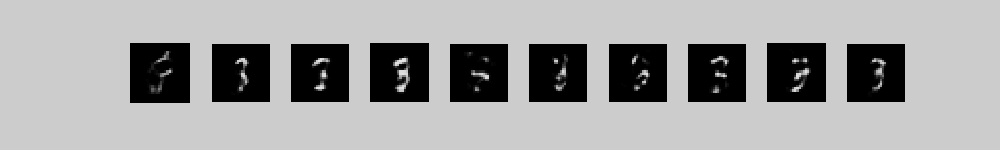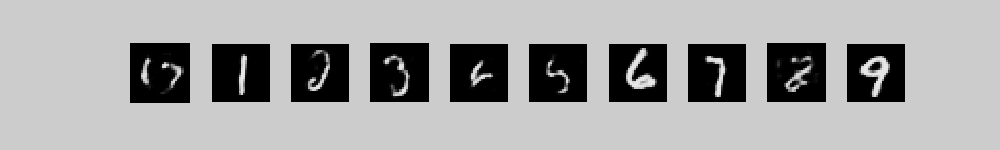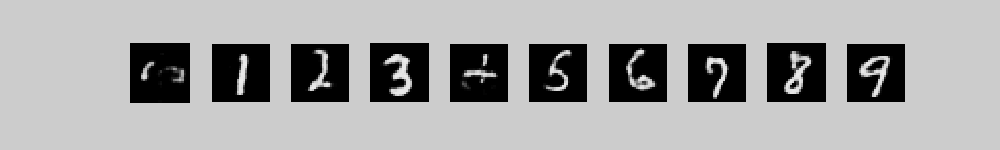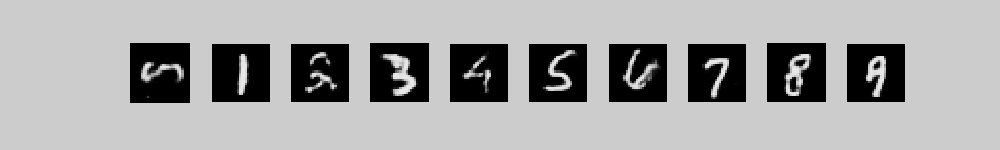{kind=link}
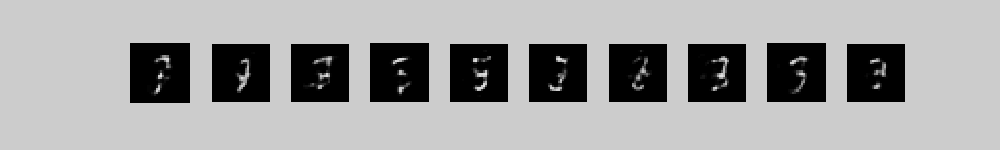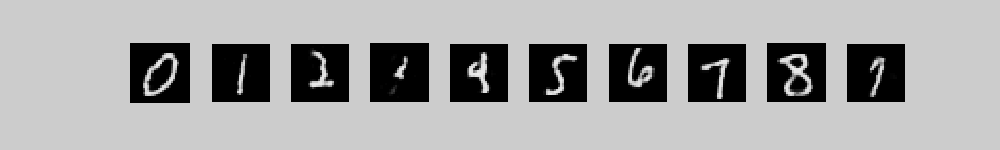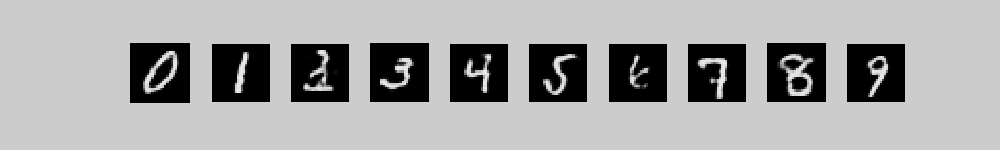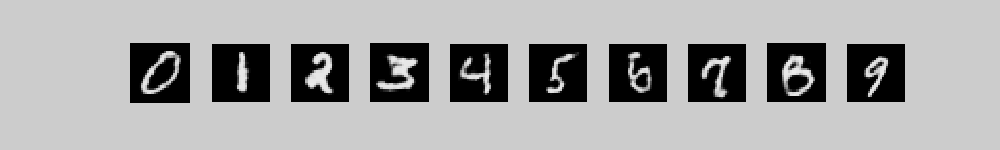{kind=link}