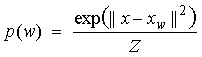|
|
|
| How to compute a predictive distribution |
||
| across 17000 words. |
||
| 100-D |
|
|
|
|
|
|
|
|
|
| • | The hidden units
predict a |
|||||||
| point in the
100-dimensional |
||||||||
| feature space. |
||||||||
| • | The probability
of each word |
|||||||
| then depends on
how close |
||||||||
| its feature
vector is to this |
||||||||
| predicted point. |
||||||||