|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| • |
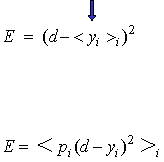
If we want to
encourage cooperation,
|
|
|
we compare the
average of all the
|
|
|
predictors with
the target and train to
|
|
|
reduce the
discrepancy.
|
|
|
|
– |
This
can overfit badly. It makes the
|
|
|
model
much more powerful than
|
|
|
training
each predictor separately.
|
|
|
| • |
If we want to
encourage specialization
|
|
|
we compare each
predictor separately
|
|
|
with the target
and train to reduce the
|
|
|
average of all
these discrepancies.
|
|
|
|
– |
Its
best to use a weighted average,
|
|
|
where
the weights, p, are the
|
|
|
probabilities
of picking that “expert”
|
|
for
the particular training case.
|
|