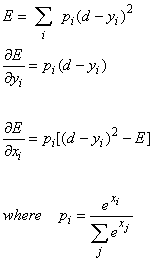| The derivatives of the simple cost function |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| • | If we
differentiate w.r.t. |
|||||||||||||||
| the outputs of
the experts |
||||||||||||||||
| we get a signal
for |
||||||||||||||||
| training each
expert. |
||||||||||||||||
| • | If we
differentiate w.r.t. |
|||||||||||||||
| the outputs of
the gating |
||||||||||||||||
| network we get a
signal |
||||||||||||||||
| for training the
gating net. |
||||||||||||||||
| – | We
want to raise p for |
|||||||||||||||
| all
experts that give |
||||||||||||||||
| less
than the average |
||||||||||||||||
| squared
error of all the |
||||||||||||||||
| experts
(weighted by p) |
||||||||||||||||